How Much VRAM Does Your LLM Need? A Guide to GPU Memory Requirements
Discover how to determine the right VRAM for your Large Language Model (LLM). Learn about GPU memory requirements, model parameters, and tools to optimize your AI deployments.


You found an open-source large language model (LLM) model you want to deploy, but aren't sure which GPU you should run your model with.
Each GPU has a "VRAM" size, but what does that really mean? You could just play it safe and pick the highest VRAM, but you might end up wasting money on unused resources. On the flip side, your LLM won't run if you don't give it the minimal required VRAM.
This guide will help you understand what VRAM is, why it matters, and how to pick the right GPU for your LLM. Let's get into it.
What is VRAM?
Video Random Access Memory (VRAM) is a special type of memory used in GPUs. GPUs were originally designed in 1999 to accelerate image & graphics rendering.
Their purpose was to offload these tasks from the CPU (Central Processing Unit), allowing for more efficient and faster rendering of complex visual scenes, particularly in video games. Early GPUs needed a memory solution that could efficiently render complex graphics in real time, and traditional RAM simply couldn't achieve this.
Enter, VRAM. VRAM offers much higher bandwidth compared to the standard system RAM. This allows for faster data transfer between the GPU and its memory, which enables processing large amounts of graphical data quickly.
Unlike system RAM, which is shared with the CPU and other components, VRAM is dedicated solely to the GPU. This ensures that the GPU has uninterrupted access to memory, leading to better and more predictable performance.
Why is VRAM important for LLMs?
VRAM is crucial for managing the high volume of data and computations needed for both training and running inference on LLMs (inference is a fancy word used to describe the process of generating predictions or responses based on the input data provided to the model).
LLMs, particularly those that use the transformer architecture (GPT, Llama, etc), rely heavily on parallel computing. They consist of multiple layers, each containing parameters (weights) that need to be loaded into VRAM for quick and efficient access. The attention mechanism in transformers, which helps the model understand context and relationships between words, requires significant VRAM.
How do LLMs use VRAM?
LLMs use VRAM to efficiently handle large amounts of data and computations for inference. Here's how VRAM is utilized:
- Model Parameters: LLMs have millions to trillions of parameters, which are stored in VRAM during inference. This is the bulk of the VRAM used by LLMs today.
- Activations: Each layer of an LLM generates substantial amounts of activation data which is then temporarily stored in VRAM.
- Batch Size: LLMs process inputs in batches to improve efficiency. Larger batch sizes require more VRAM to hold multiple inputs simultaneously.
- Precision: The precision of an LLM affects VRAM usage. Precision refers to different types of floating-point numbers used for inference. Lower precision (e.g., FP16) reduces VRAM requirements, enabling larger models or batches to fit within the same VRAM size with minimal tradeoff in accuracy.
The image below shows us the large amount of memory occupied by the LLM's parameters alone.
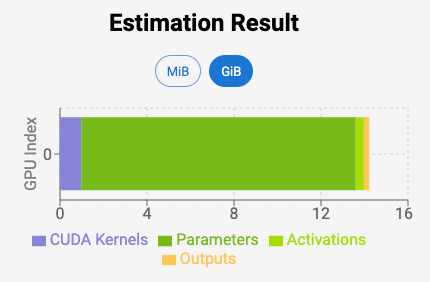
Side note: vLLM is a framework used to drastically decrease memory usage and increase throughput. Learn more here about vLLM and read till the end to run your model with vLLM in 30 seconds.
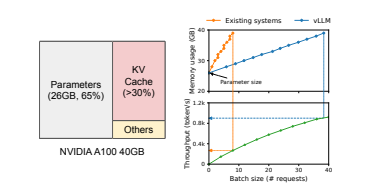
How much VRAM do you need?
Too little VRAM and your model fails, too much and you end up wasting money. So let's try to calculate how much you really need.
Since we know parameters take up the bulk of VRAM, we can calculate how much VRAM is needed with some quick back-of-the-napkin math:

Here are some online tools you can use to estimate how much VRAM you need:
- Vokturz’ Can it run LLM calculator
- Hugging Face's Model Memory Usage Calculator
- Alexander Smirnov’s VRAM Estimator
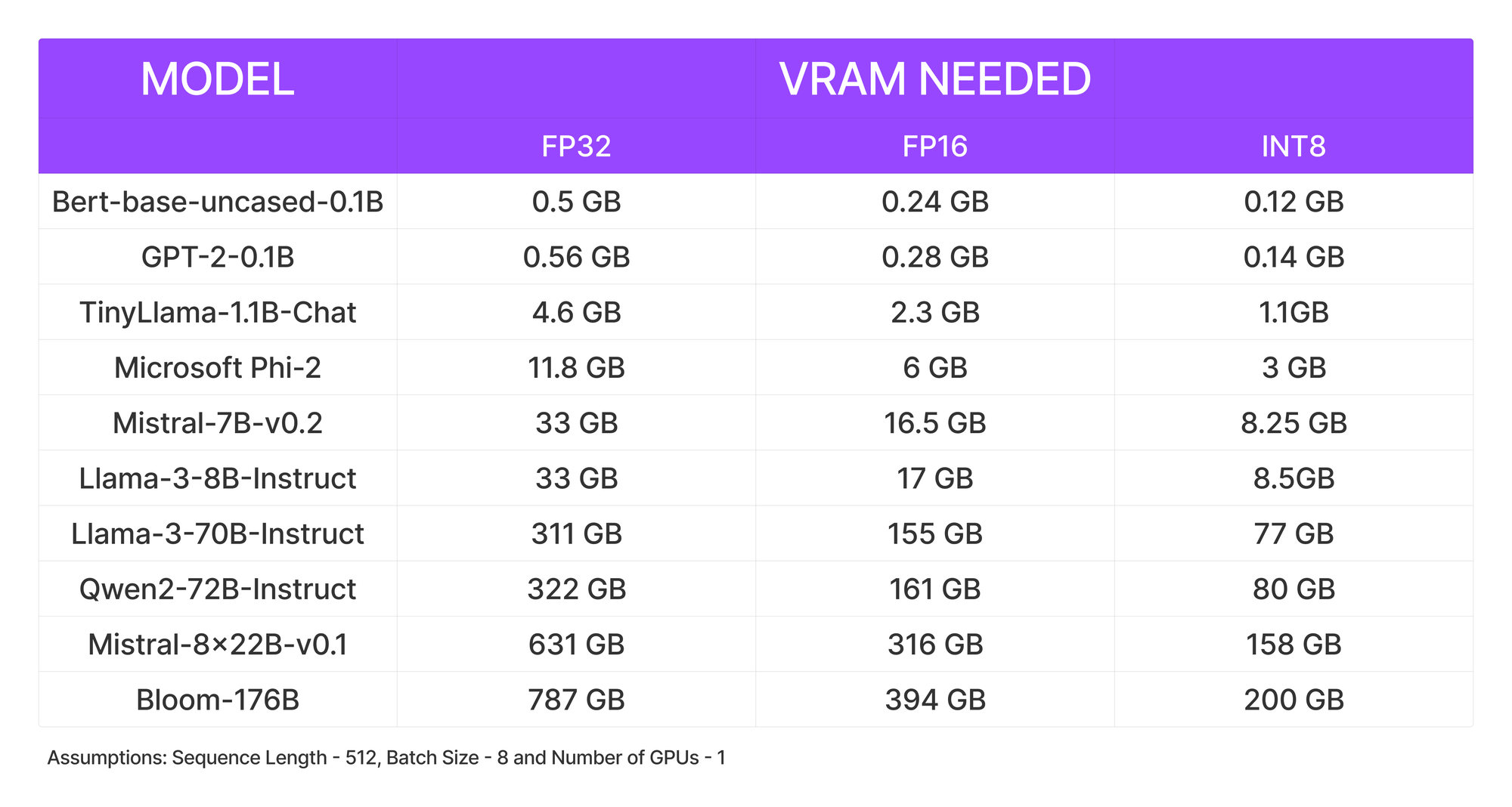
Finally, we put together this table that shows how much VRAM is needed for the most popular LLMs (assuming a fixed sequence length, batch size, and a single GPU):
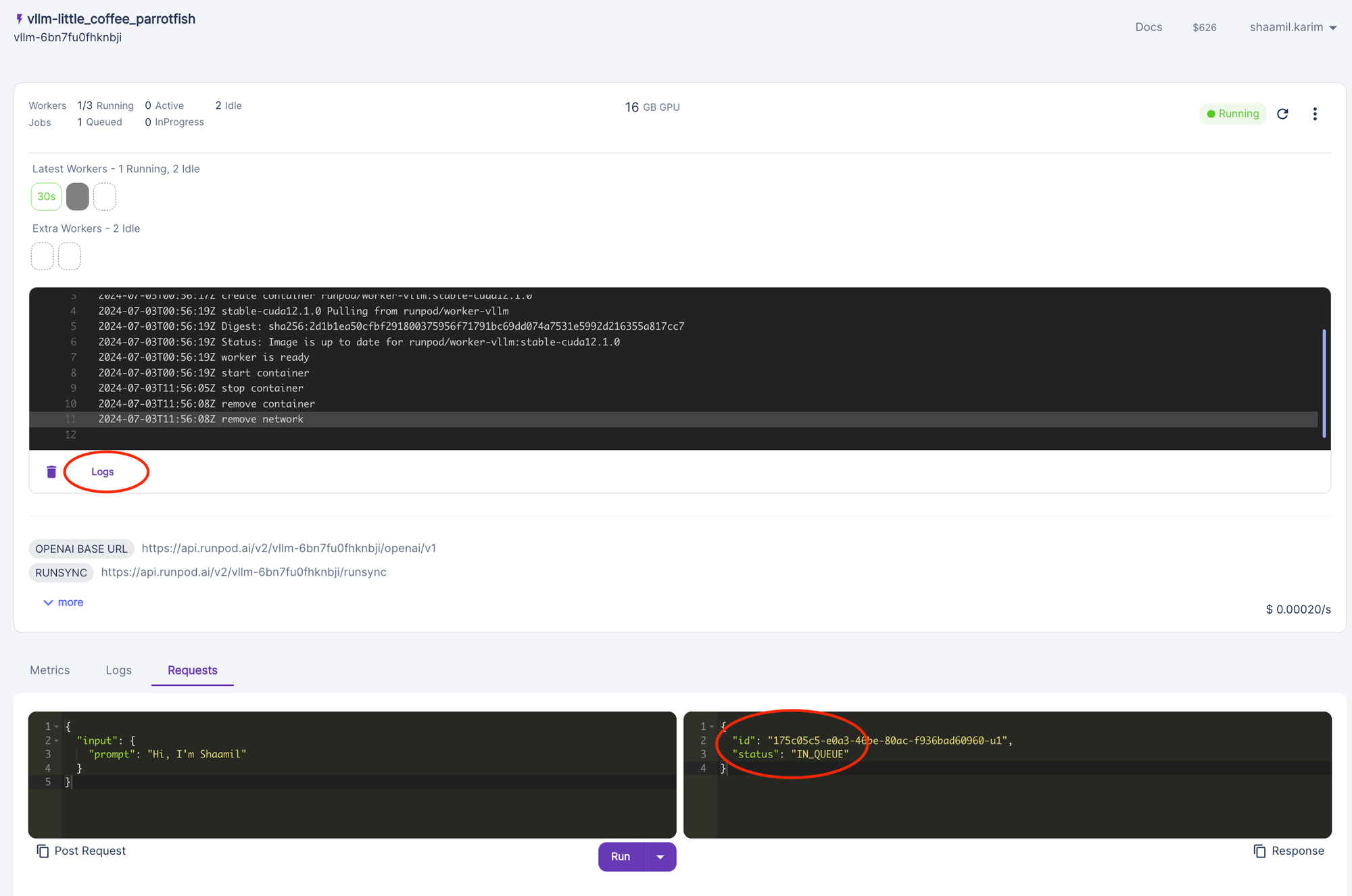
Try it for yourself in 30 seconds
Now let's see this in practice.
- Use the rough formula or this tool to estimate the VRAM you need.
- Deploy your LLM here. Select “Serverless vLLM” from the Quick Deploy section and paste your hugging face model along with your access token if you’re using a gated model.
- Select the right specifications you need. You could skip the terminology and use defaults if needed.
- Navigate to the requests tab to test out your model in action. Done!
Troubleshooting
When sending a request to your LLM for the first time, your endpoint needs to load your model weights and initialize your model. If the output status remains "in queue" for more than 5-10 minutes, read below!
- Check the logs to pinpoint the exact error. Make sure you didn't pick a VRAM that was too small! Be sure to use the VRAM estimator tool.
- If your model is gated (ex. Llama), first make sure you have access, then paste your access token from your hugging face profile settings when creating your endpoint.
Conclusion
To recap, Video Random Access Memory (VRAM) is dedicated memory for your GPU to handle the intensive computations and vast data required by LLMs. VRAM was originally designed for rendering complex graphics in real-time and offers the high bandwidth necessary for processing the millions to billions of parameters in LLMs efficiently.
To prevent your LLM from failing from too little VRAM or wasting money on too much, it's important to estimate the minimal amount of VRAM you'll need. The most important variables to do so are model parameters, activations, batch size, and precision. Since model parameters take the bulk of VRAM memory, we can use the rough estimate formula above or tools like Vokturz’ Can it run LLM calculator.
Hopefully, now you're ready to select a GPU with the optimal VRAM size for your LLM, ensuring efficient performance without overspending. Ready to deploy your model? Try out Runpod's quick deploy serverless vLLM option here.