Introduction to vLLM and PagedAttention


What is vLLM?
vLLM is an open-source LLM inference and serving engine that utilizes a novel memory allocation algorithm called PagedAttention. It can run your models with up to 24x higher throughput than HuggingFace Transformers (HF) and up to 3.5x higher throughput than HuggingFace Text Generation Inference (TGI).
How does vLLM achieve this throughput improvement? Existing systems waste 60%-80% of the KV-Cache (LLM memory), whereas vLLM achieves near-optimal memory usage with a mere waste of under 4%. Because of this improved memory usage, we require fewer GPUs to achieve the same output, so the throughput is significantly higher than that of other inference engines.
Thousands of companies use vLLM to reduce inference costs. For example, LMSYS, the organization behind Chatbot Arena and Vicuna, cut the number of GPUs used to serve their growing traffic of ~45k daily requests by 50% while serving 2-3x more requests per second. vLLM leverages PagedAttention to reduce memory waste and achieve these efficiency improvements.
What is PagedAttention, and how does it work?
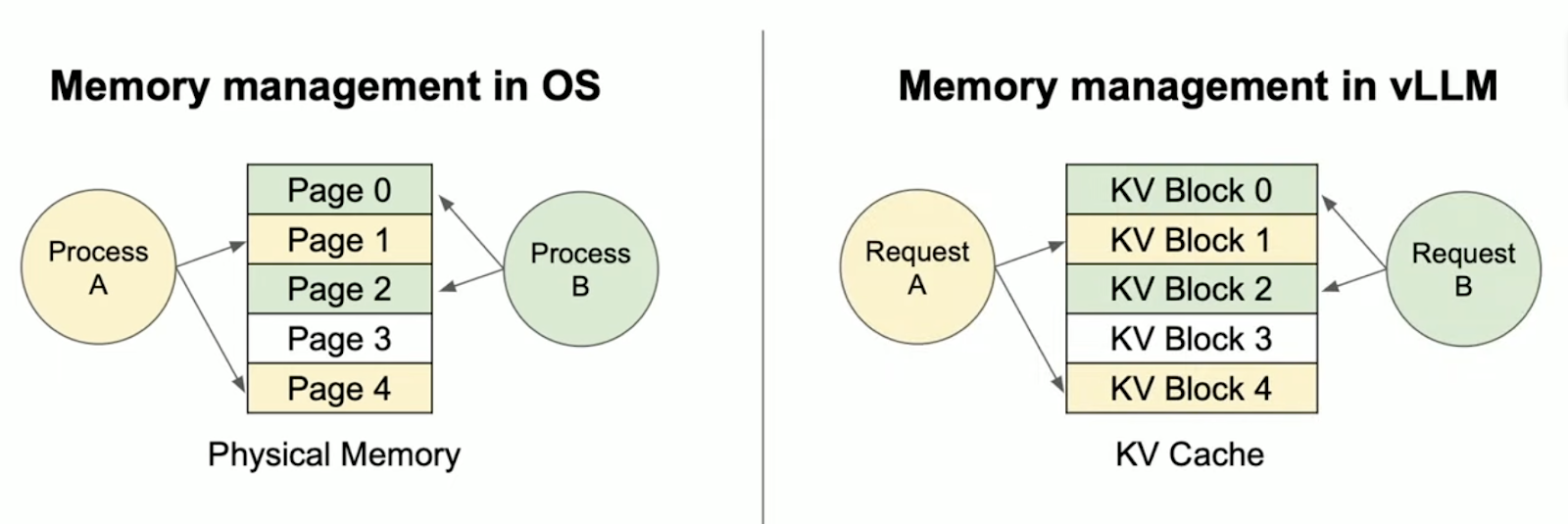
In early 2023, the authors behind vLLM noticed that existing inference engines only used 20%-40% of the available GPU memory. When exploring solutions to this problem, they remembered the concept of Memory Paging from operating systems. They applied it to better utilize KV-Cache, where transformers store attention calculations during LLM inference. Let's start with understanding Memory Paging.
Inspiration—Memory Paging
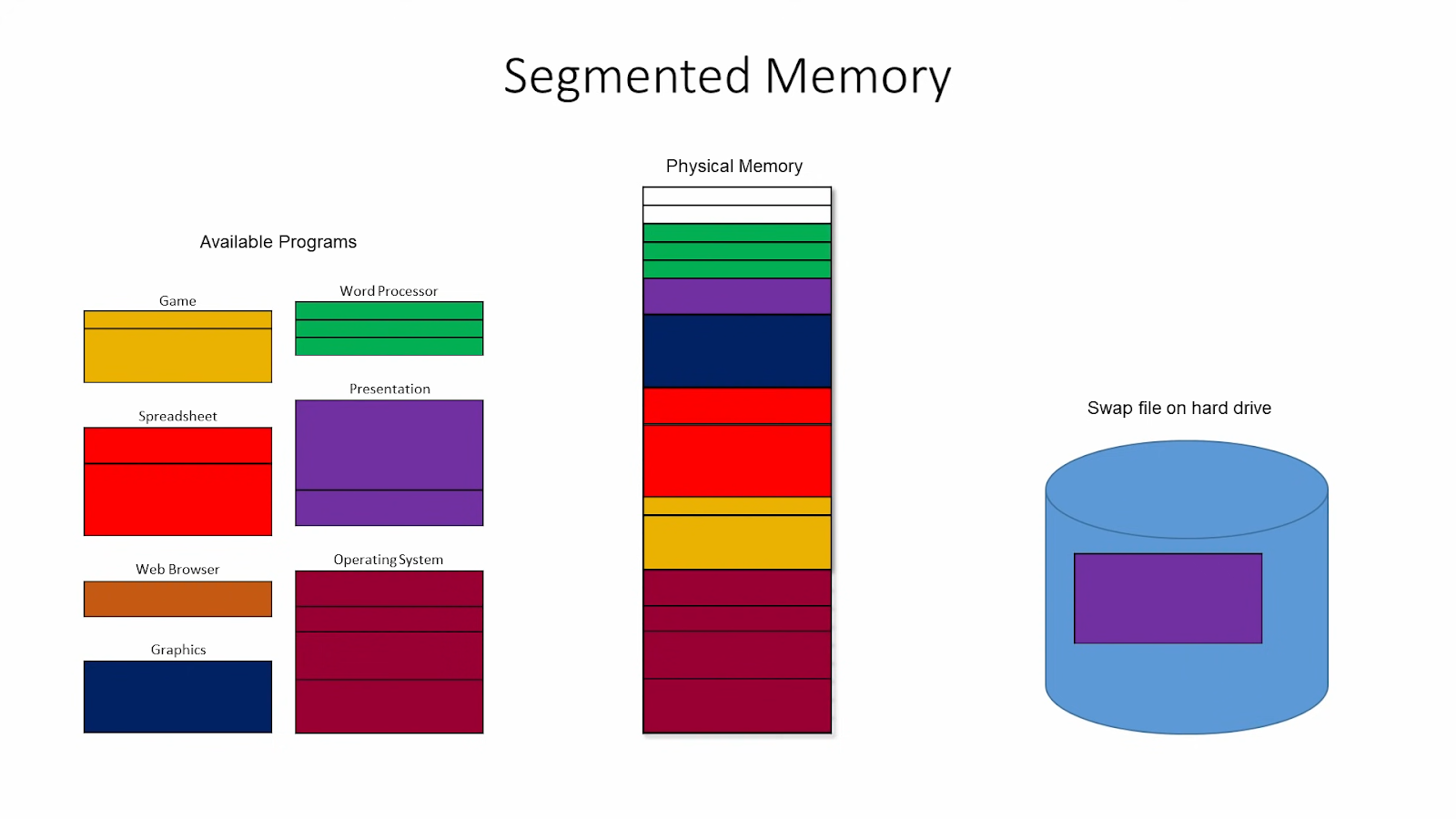
In their paper, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” the authors introduce PagedAttention, a novel algorithm inspired by virtual memory paging. Memory paging is used in operating systems, including Windows and Unix, to manage and allocate sections of a computer's memory, called page frames. It allows for more efficient memory usage by swapping out parts of memory that are not actively used. PagedAttention adapts this approach to optimize how memory is used in LLM serving, enabling more efficient memory allocation and reducing waste.
Understanding KV Cache
Have you noticed that the first few tokens returned from an LLM take longer than the last few? This effect is especially pronounced for longer prompts due to how LLMs calculate attention, a process heavily reliant on the efficiency of the Key-Value (KV) Cache.
The KV Cache is pivotal in how transformers process text. Transformers use an attention mechanism to determine which parts of the text are most relevant to the current tokens generated. This mechanism compares a newly generated query vector (Q) against all previously stored key vectors (K). Each key vector corresponds to earlier context the model considers, while each value vector (V) represents how important these contexts are in the current computation.
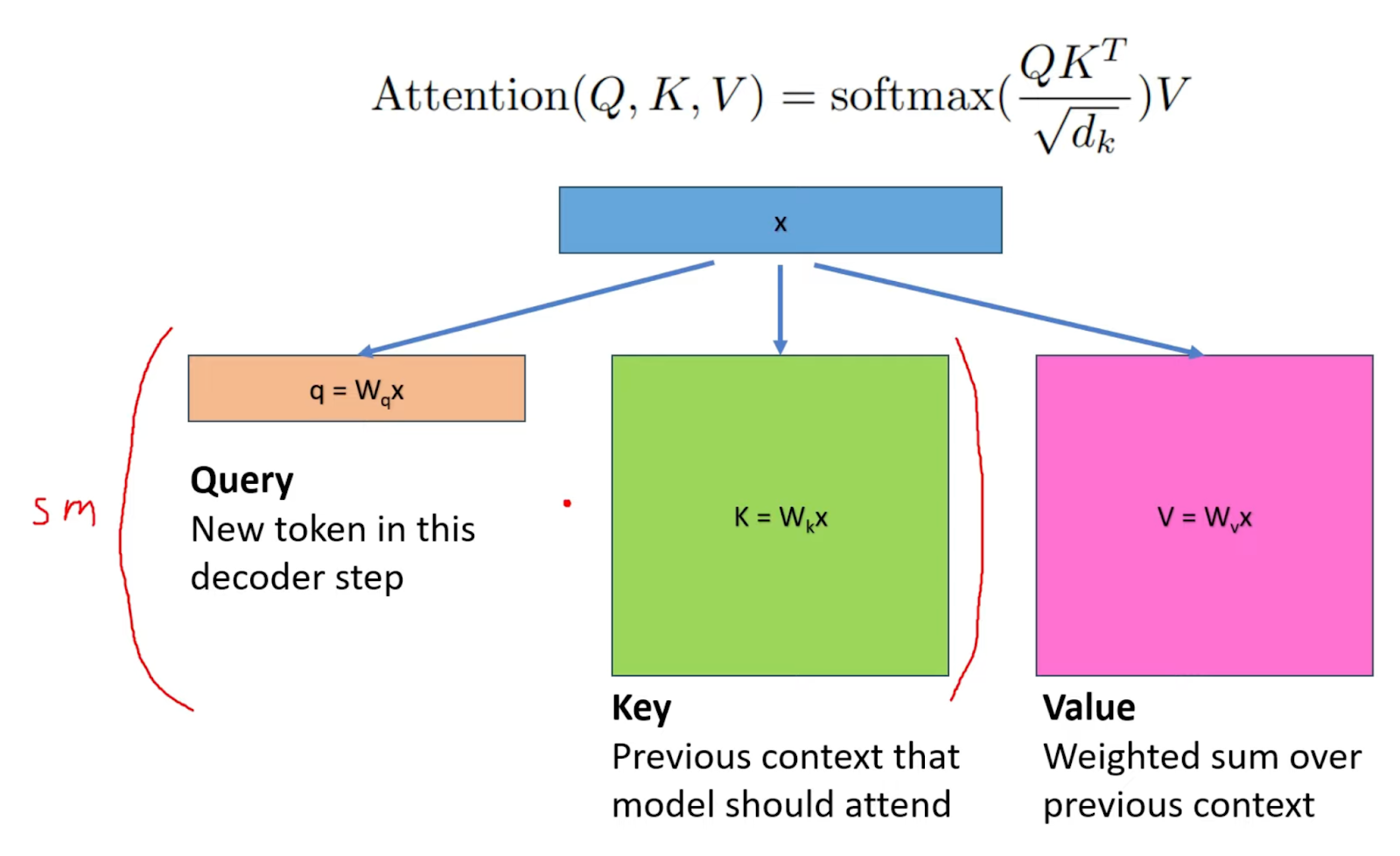
Instead of re-calculating these KV pairs for each new token generation, we append them to the KV cache so they can be reused in subsequent calculations.
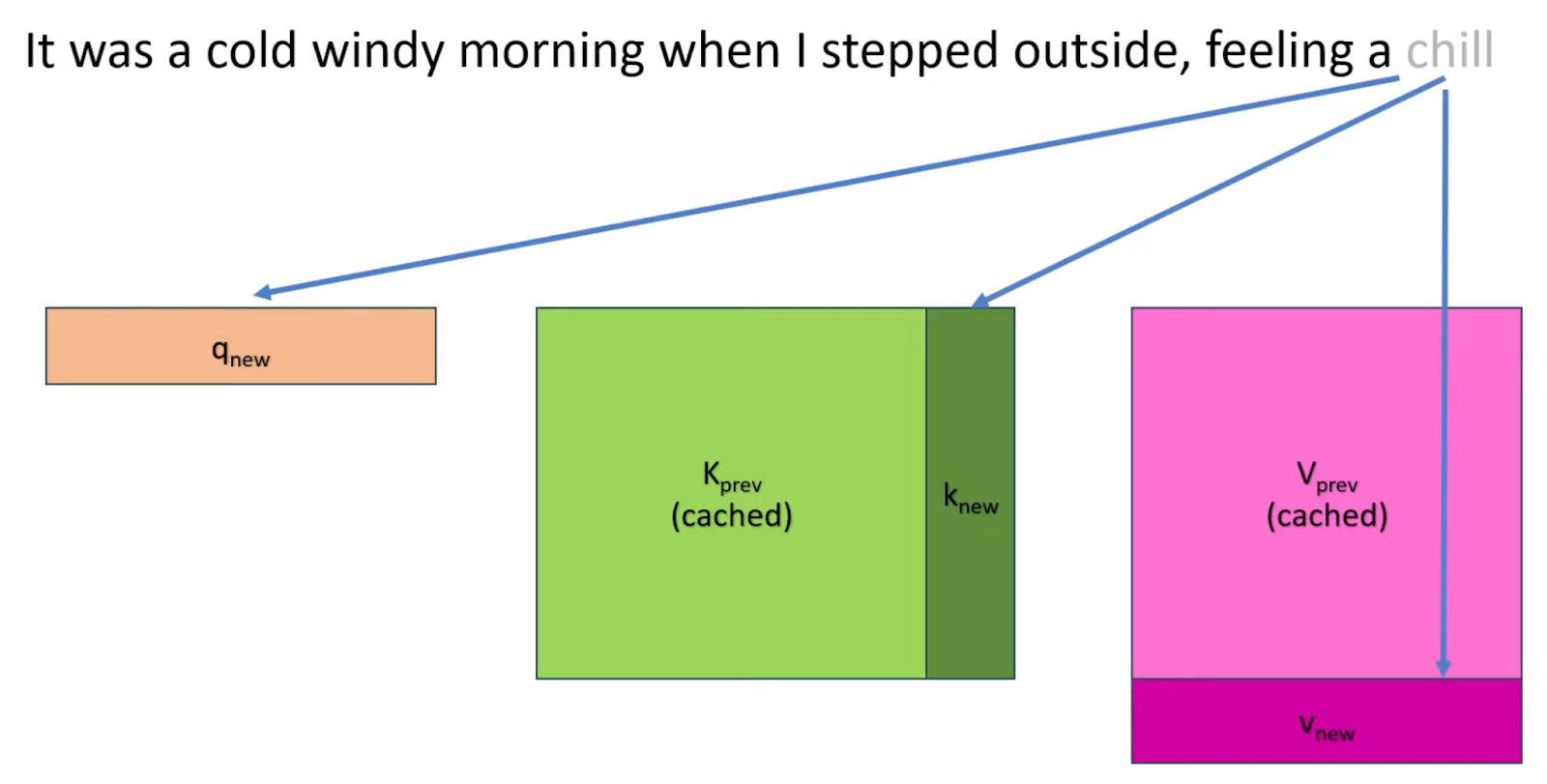
The Cache is initially empty, and the transformer needs to precompute it for the entire sequence to start generating new tokens. This explains the slow speed of the first few tokens. However, traditional implementations of KV cache waste a lot of space.
How PagedAttention Optimizes KV Cache Utilization
PagedAttention addresses these inefficiencies through a more dynamic memory allocation using the previously unused space. Let's understand how existing systems waste memory space.
The parameters of a 13B LLM like llama-13b take up about 26GB. For an A100 40GB GPU, this already takes up 65% of its memory. We now only have about 30% of the memory for managing the KV Cache.
Existing systems store KV cache pairs in continuous memory spaces. In other words, they allocate a fixed, unbroken block of space for every request. However, requests to an LLM can vary in size widely, which leads to a significant waste of memory blocks.
The researchers behind vLLM break this down further into three types of memory waste:
- Internal fragmentation: Slots of memory for a sequence output are allocated but never used, because the system does not know how many tokens the model will generate. The input prompt's complexity and the inherent design of autoregressive models like transformers influence the output sequence length. These models generate one token at a time, adjusting their output based on the tokens generated so far, which makes the exact sequence length variable.
- Reservation: To ensure sequences are processed without interruption, the system reserves the entire block of memory for the duration of the request. Even if only a part of the reserved memory is used, the rest remains blocked off and cannot be used by other requests. In other words, the system prioritizes the stability and continuity of the current processing task over memory efficiency.
- External fragmentation: External fragmentation occurs when fixed-size memory blocks do not match the variable lengths of sequences, leaving unused gaps between them that cannot be allocated to other processes, unlike internal fragmentation, which involves excess space within allocated blocks.
As a result, only 20-40% of the KV cache being used to store token states.
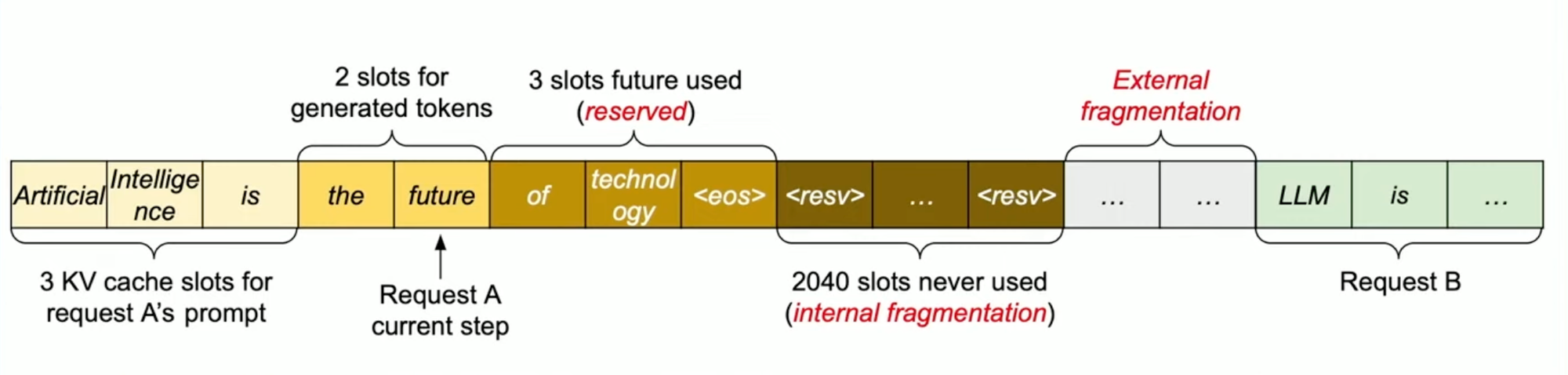
This continuous or fixed memory space allocation can suffice if the input and output lengths are static and known but is inefficient if the sequence lengths are dynamic, as is the case with most LLM inference use cases.
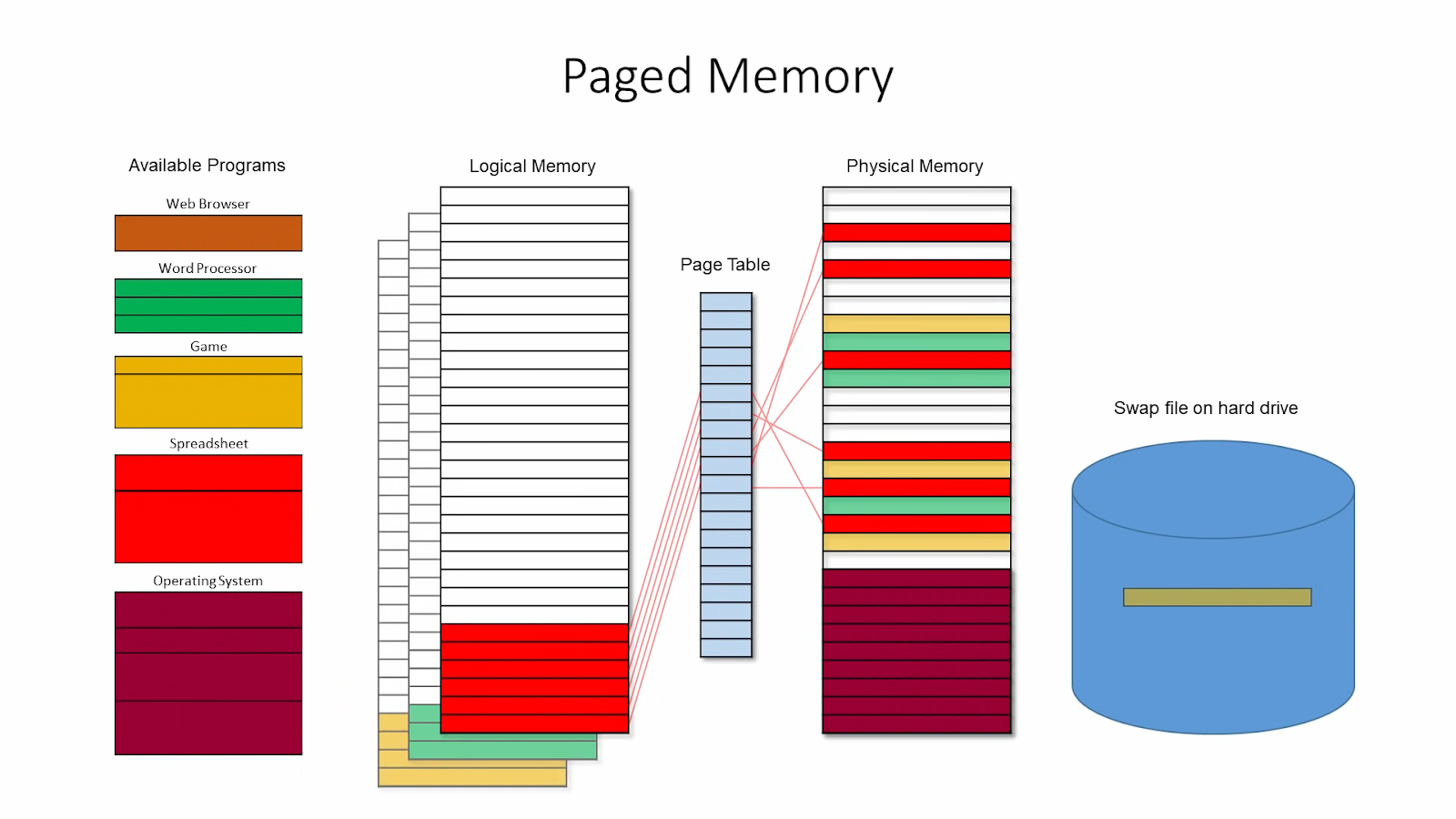
PagedAttention applies the concept of Memory Paging to more efficiently manage the KV Cache. It allocates blocks dynamically, enabling the system to store continuous blocks in arbitrary parts of the memory space. They are allocated on demand. The mapping between the logical KV cache and the physical memory space is stored in the Block table data structure.
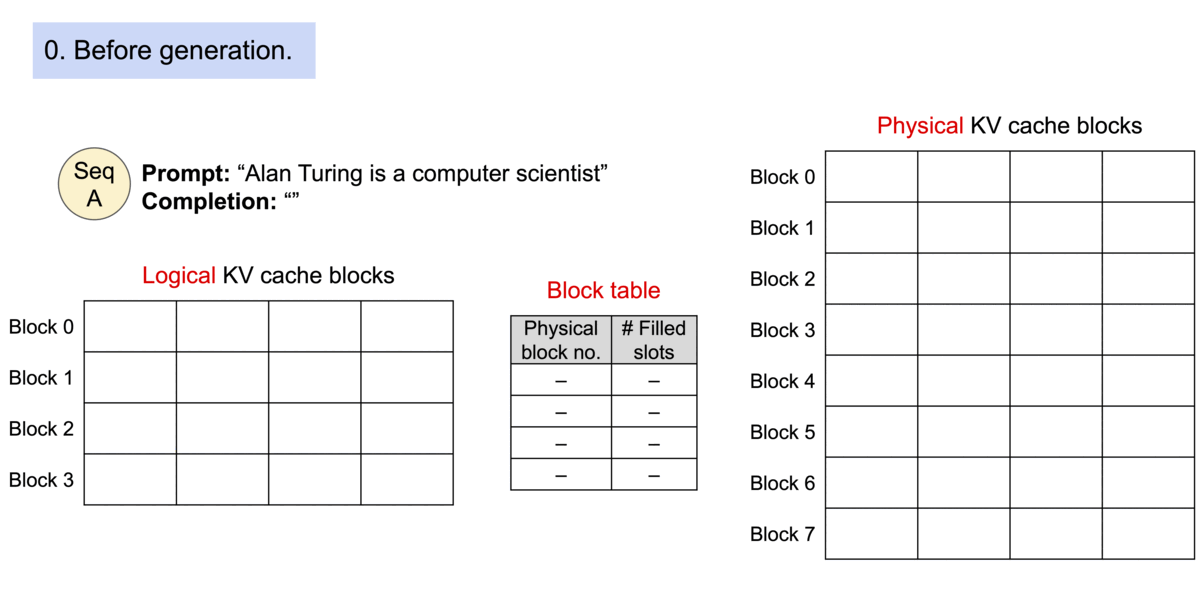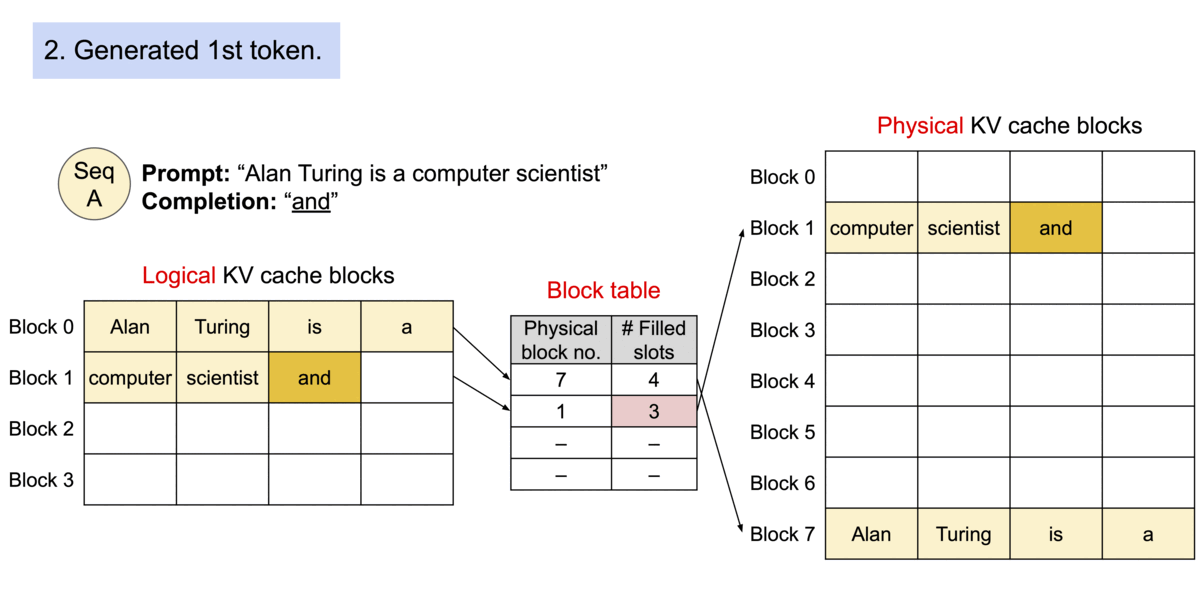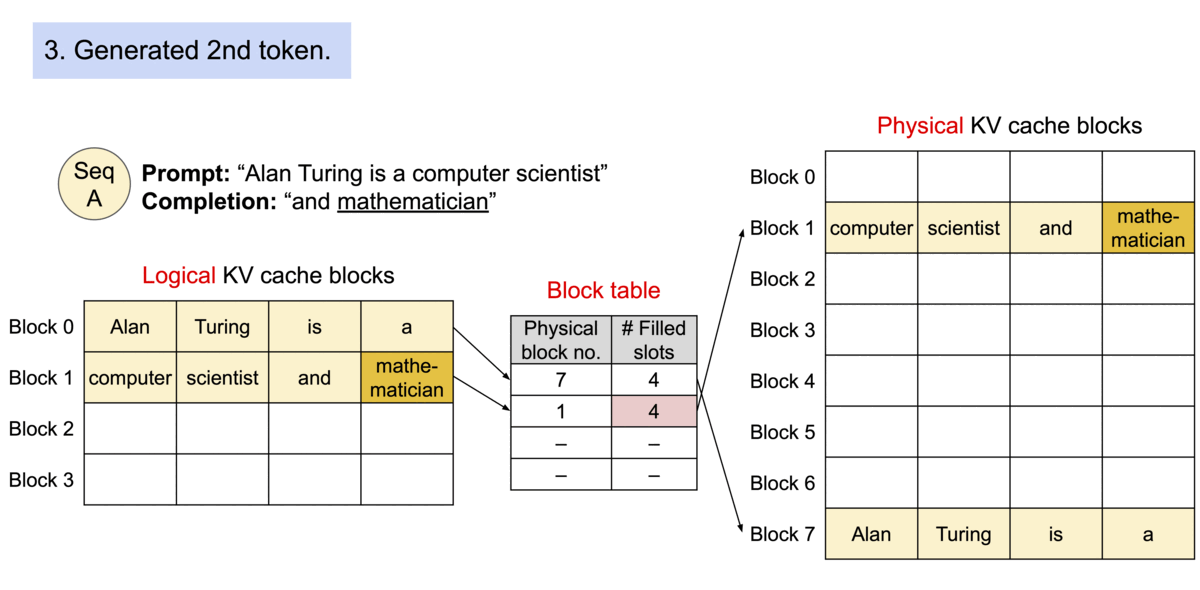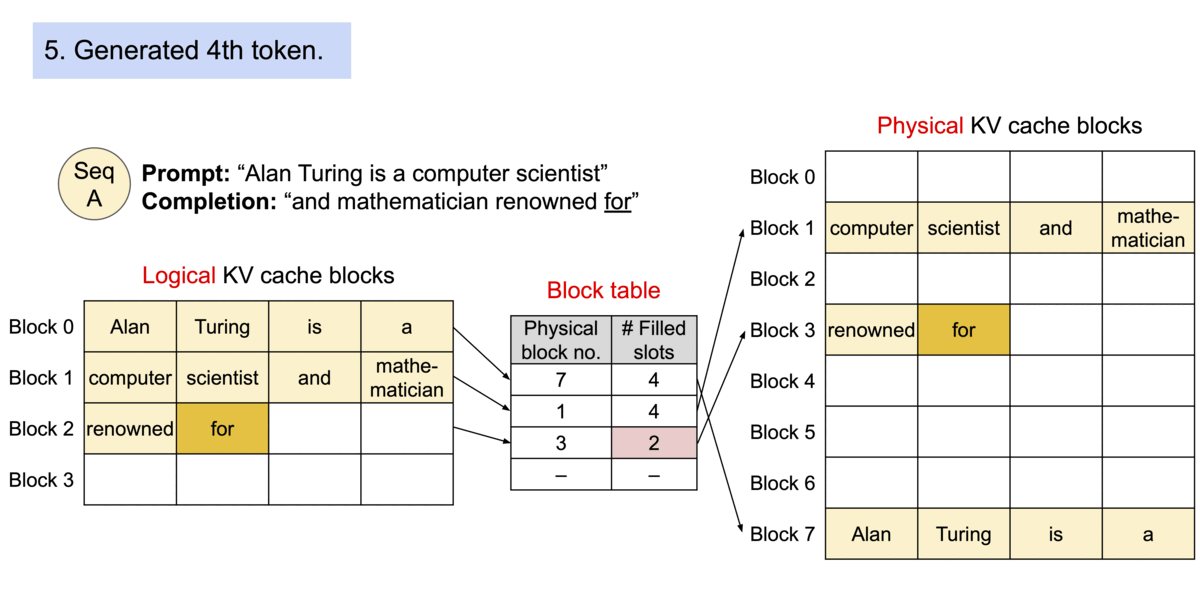
With PagedAttention, vLLM eliminates external fragmentation—where gaps between fixed memory blocks go unused—and minimizes internal fragmentation, where allocated memory exceeds the actual requirement of the sequence. This efficiency means nearly all allocated memory is effectively used, improving overall system performance.
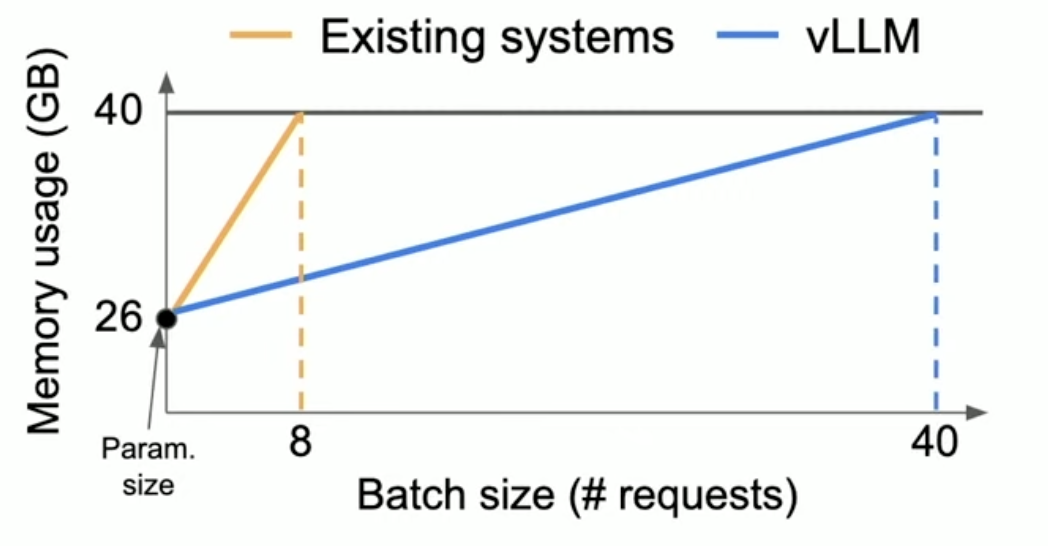
While previous systems waste 60%-80% of the KV cache memory, vLLM achieves near-optimal memory usage with a mere waste of under 4%.
The enhanced memory efficiency achieved through PagedAttention allows for larger batch sizes during model inference. This allows for more requests to be processed simultaneously and means that GPU resources are used more completely and efficiently, reducing idle times and increasing throughput.
Memory Sharing with PagedAttention
Another advantage of PagedAttention's dynamic block mapping is memory sharing between separate requests and their corresponding sequences.
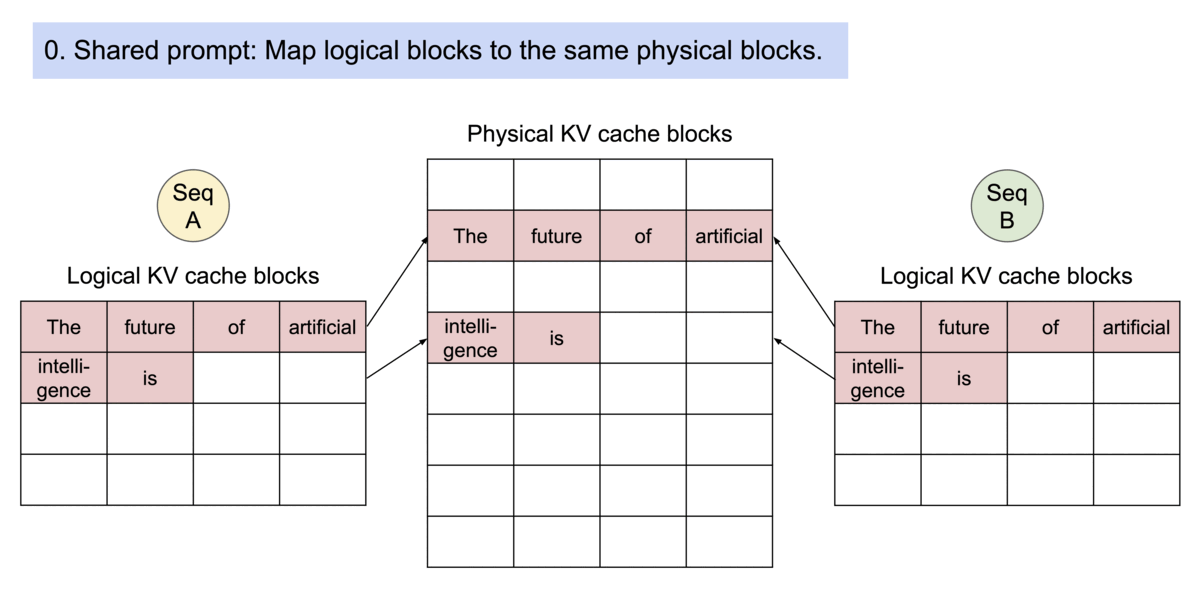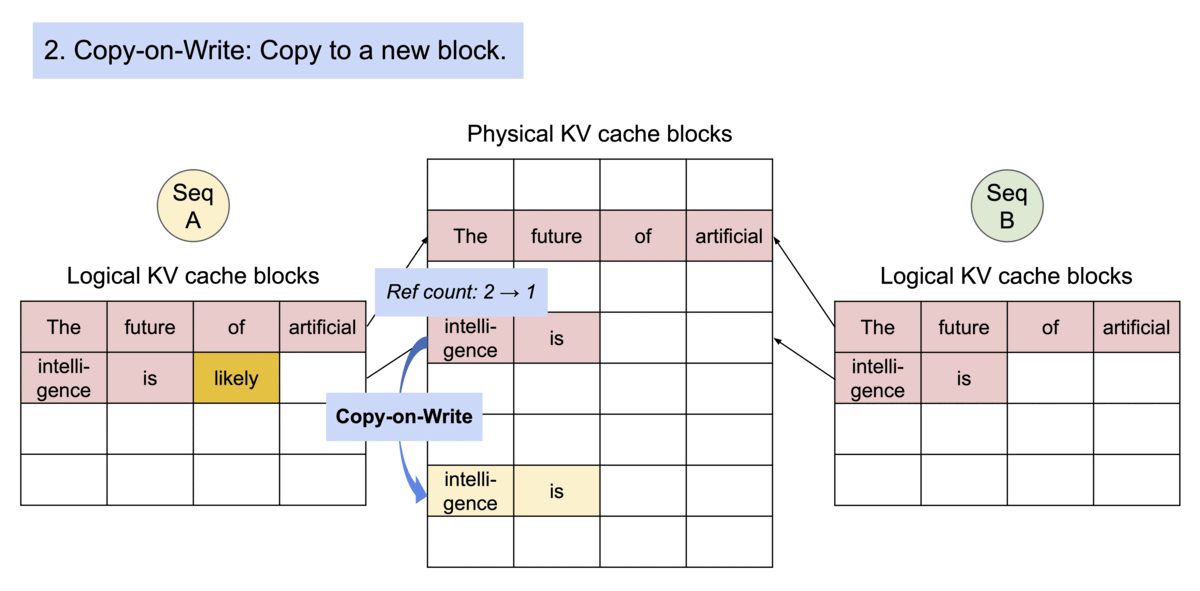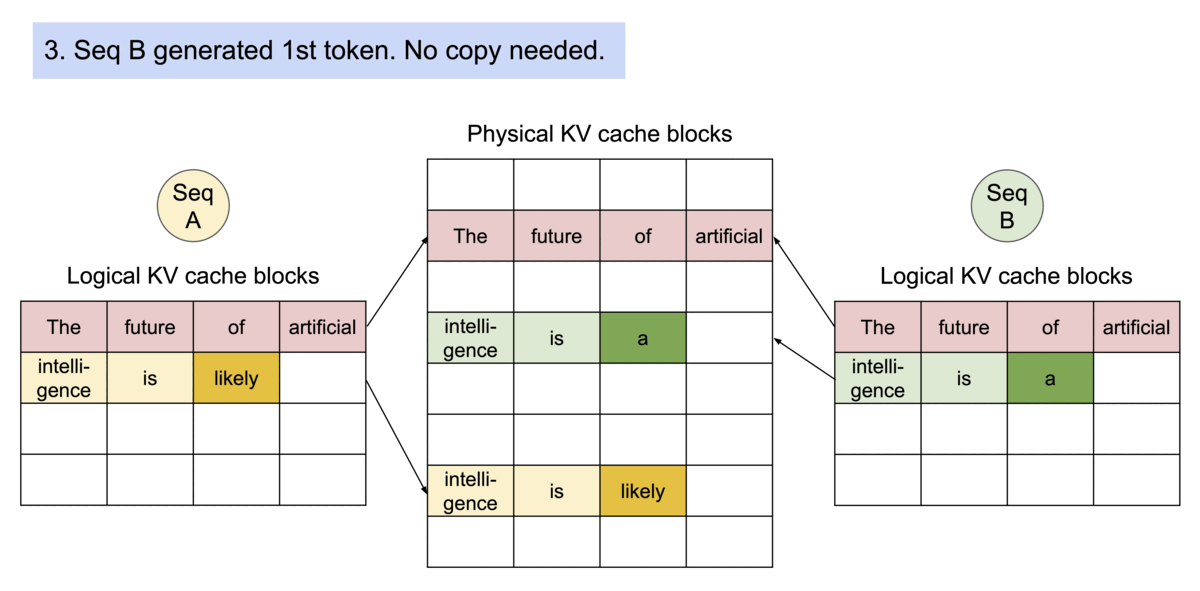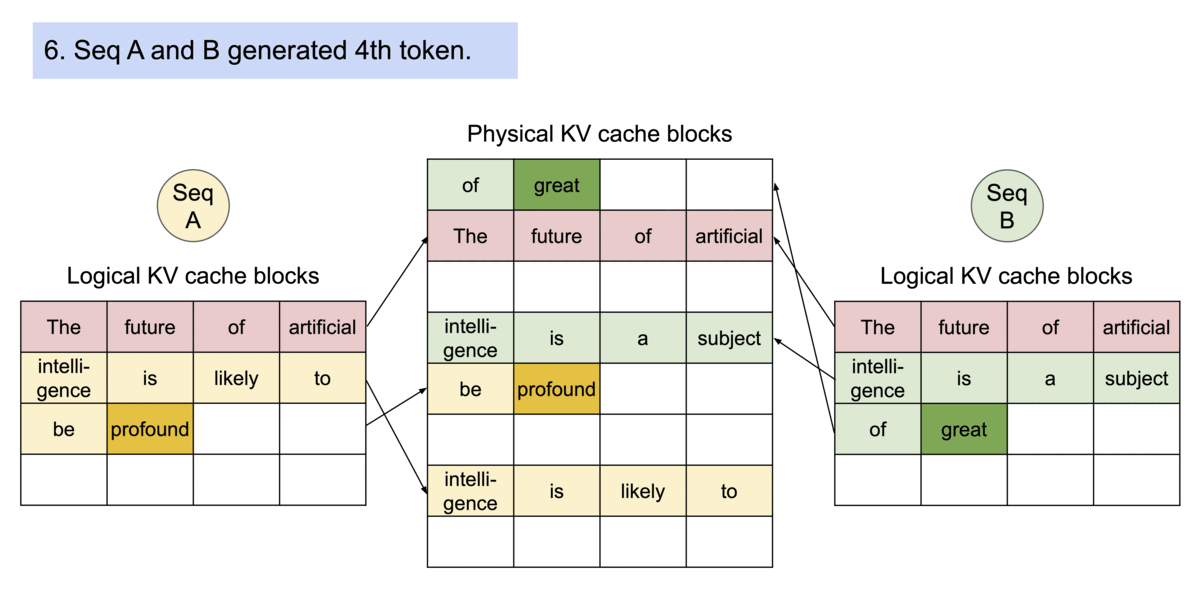
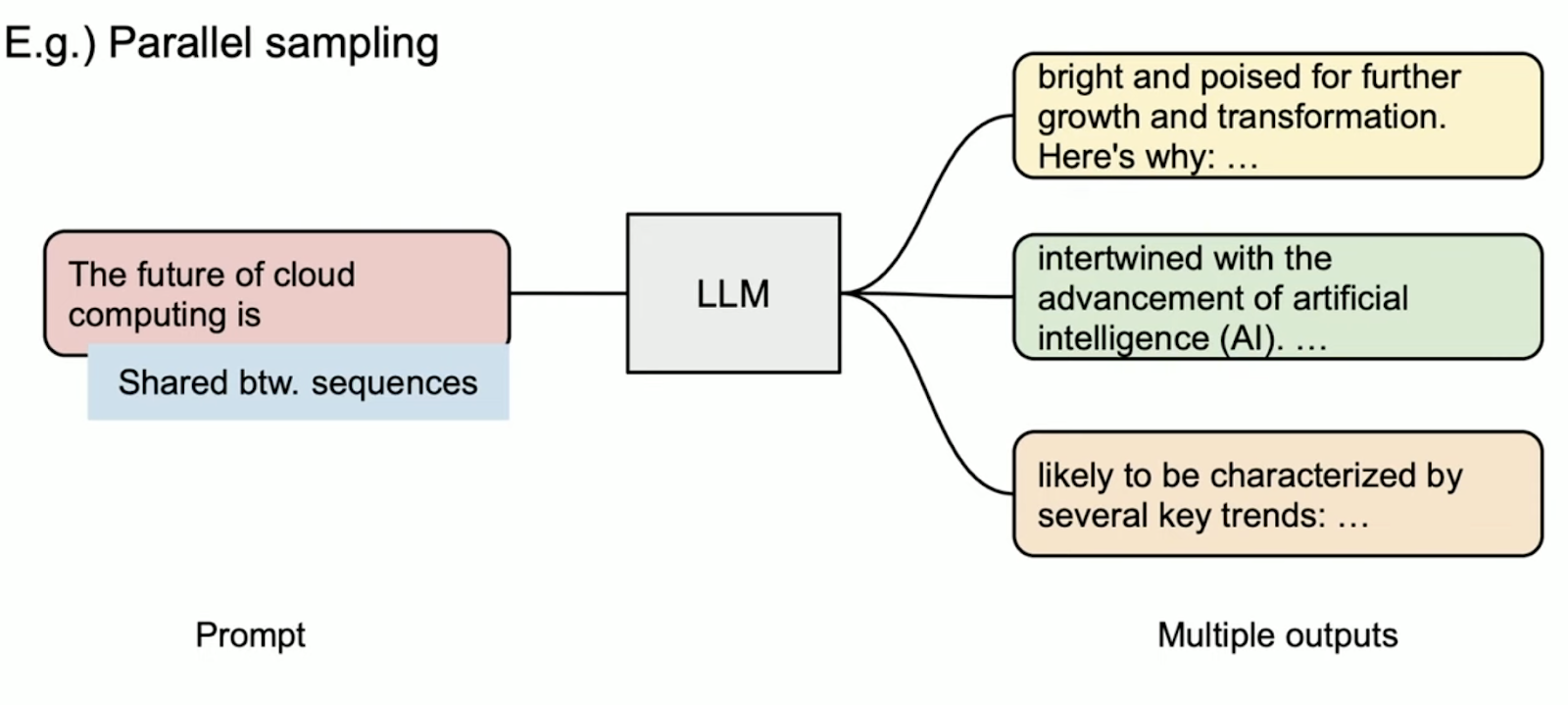
Let's look at two LLM-inference decoding algorithms where this memory sharing helps us:
- Parallel sampling/decoding: This method generates multiple output samples from the same prompt. It's particularly useful for applications where selecting the optimal response is crucial. For instance, in a content generation application, users can compare and choose the best variation. Similarly, in model testing scenarios, you can use it to compare several outputs. vLLM enables the sharing of the computation and memory for the prompt.
- Beam Search: Beam search is a strategy used in tasks like machine translation to find the most likely sequence of words. It expands the most promising options at each step, known as beams. As more of the sequence is generated, these options are narrowed down by continuing the paths with the highest probabilities. vLLM efficiently manages the memory of shared beam branches.
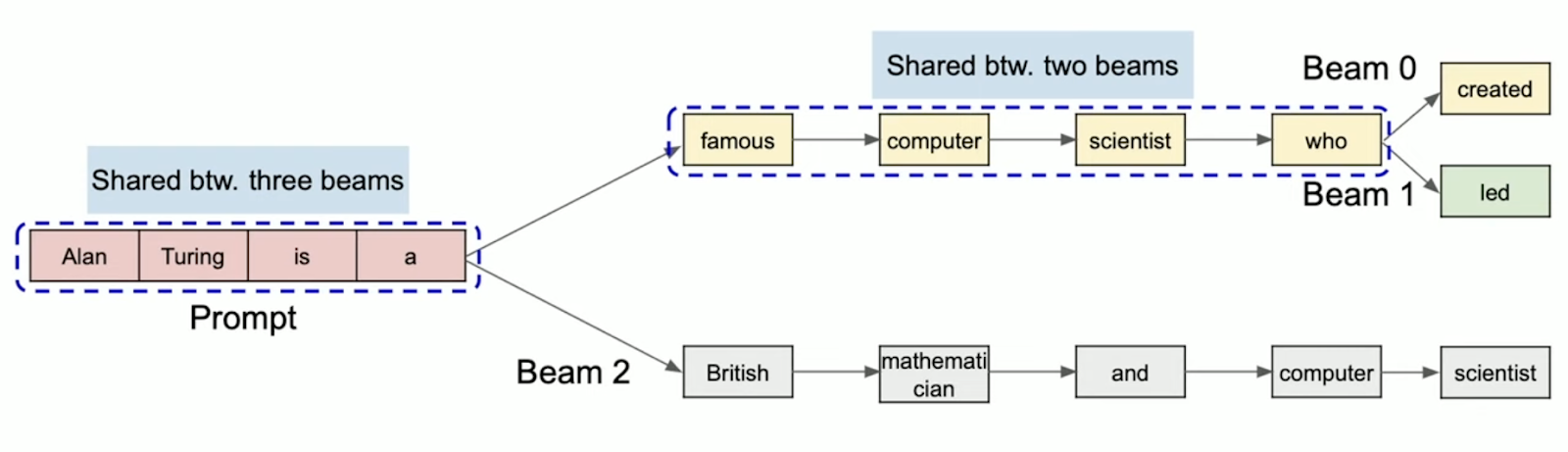
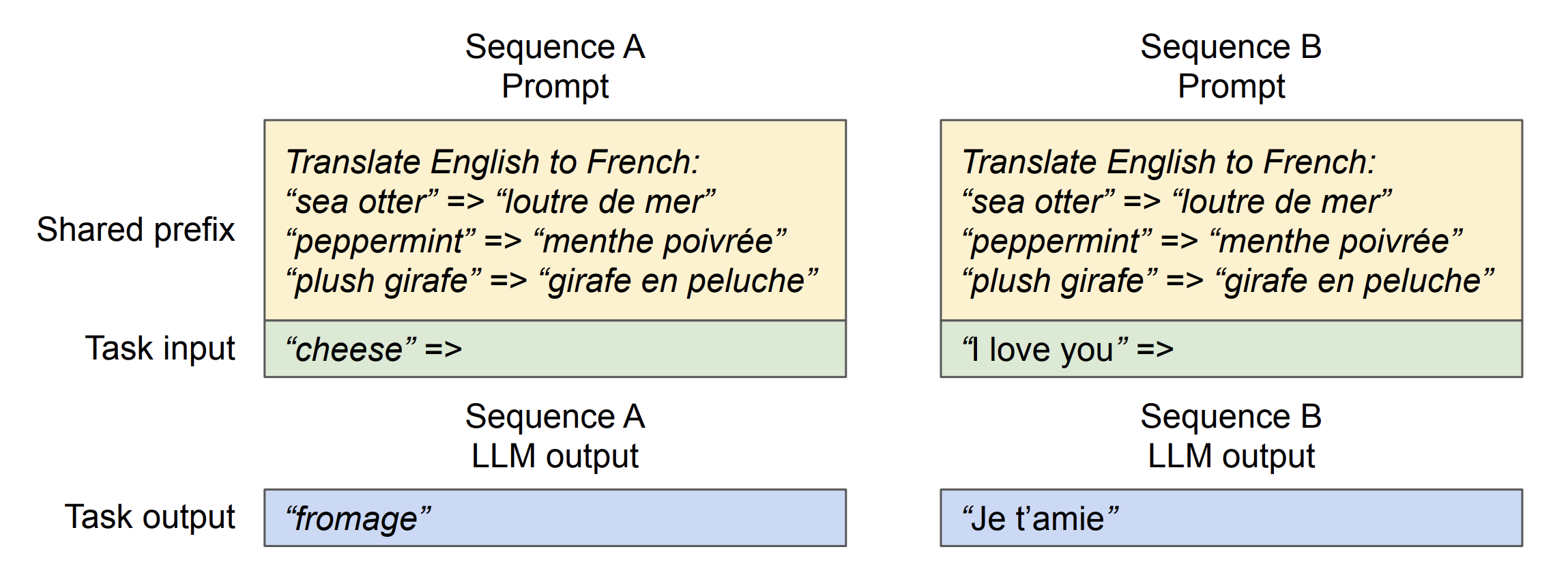
- Shared Prefix: Shared Prefix allows multiple users to start their requests with a common set of instructions or examples, known as a system prompt. This common starting point is pre-stored by vLLM to save computation time, enhancing efficiency and accuracy for subsequent tasks.
- Mixed Decoding Methods: allow vLLM to efficiently manage requests that utilize various decoding strategies, such as greedy decoding, beam search, and top-k sampling. By optimizing memory sharing, vLLM can handle these diverse preferences concurrently within its system architecture, significantly enhancing throughput and system flexibility without the need for simultaneous decoding within a single request.
Other Performance Optimizations Enabled by vLLM—Quantization, Prefix Cashing & Speculative Decoding
vLLM implements several other techniques to increase performance:
Quantization
8-bit quantization reduces the precision of the model's numerical data from the standard 32 bits to just 8 bits. Applying this technique to a large model like Llama 13B, for example, which initially requires 52 GB in a 32-bit format (13b*32 bits = 13b*4 bytes = 52GB), would now only need 13 GB post-quantization.
This reduction in size allows models to fit better in memory, enabling a model like Llama 13B to run on a single 24 GB VRAM GPU. The process usually comes at the expense of some performance loss, but the tradeoff is worth the performance bump for many LLM inference use cases.
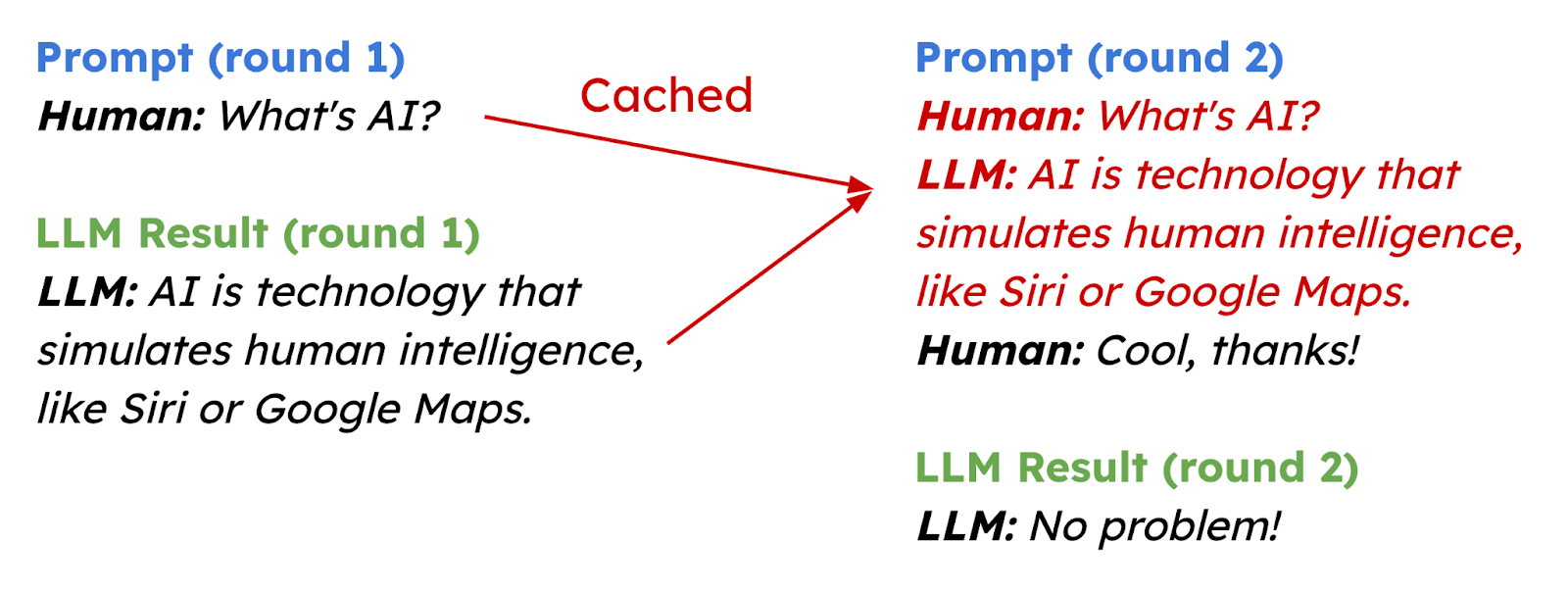
Automatic Prefix Caching
Improves efficiency by caching repeated computation across different inference requests, particularly beneficial in scenarios with repeated prompts, including multi-round conversations.
Speculative Decoding
Speculative decoding is when a smaller model is used to predict the output of a larger model, thus inferring responses more quickly and potentially doubling decoding speeds.
Multi-LoRA Support
Facilitates using Low-Rank Adaptation (LoRA) to manage multiple model adaptations efficiently. This allows a single base model to be used with various adapters, optimizing memory usage and computational efficiency across different tasks. An adapter, in this context, is a small, lower-rank matrix that fine-tunes the model on specific tasks without extensive retraining, enhancing versatility and resource efficiency.
How does vLLM Compare With Other Inference Engines?
vLLM vs. TGI and Hugging Face Transformers
The Berkeley researchers behind vLLM compared the throughput of LLaMA-7B on an NVIDIA A10G GPU and LLaMA-13B on an NVIDIA A100 GPU (40 GB). vLLM achieves 24x higher throughput compared with HuggingFace Transformers (HF) and a 3.5x higher throughput compared with HuggingFace Text Generation Inference (TGI).
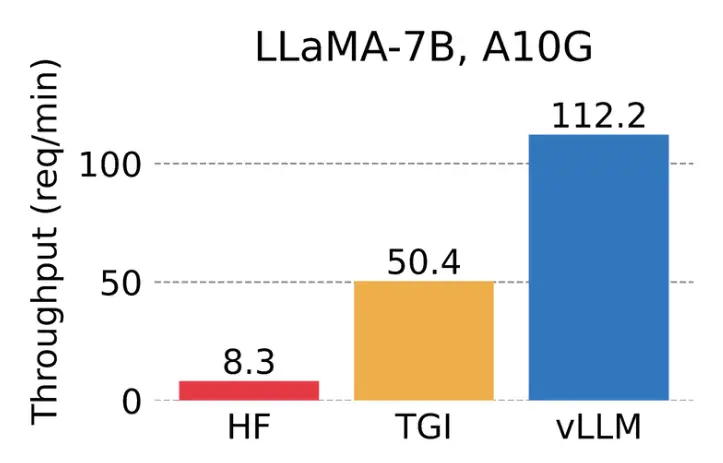
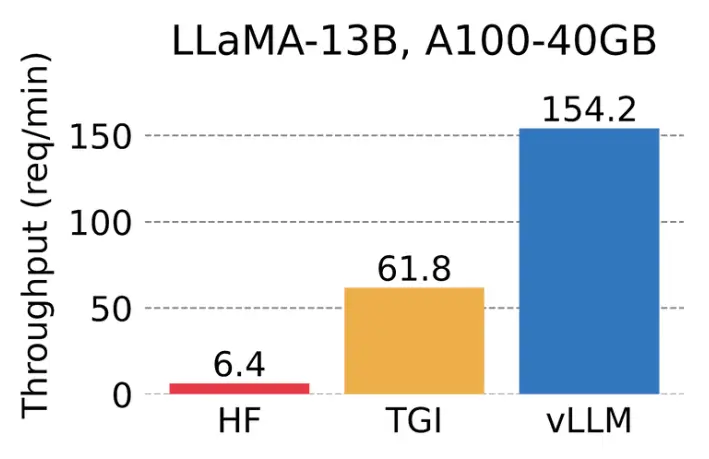
Graph showing the serving throughput when each request asks for one output completion. vLLM achieves 14x - 24x higher throughput than Hugging Face Transformers (HF) and 2.2x - 2.5x higher throughput than HuggingFace Text Generation Inference (TGI). (Source).
vLLM vs. TensorRT-LLM
A direct performance comparison with TensorRT-LLM is difficult as the effectiveness of each can vary based on the model configuration, quantization precision, and specific hardware used. For instance, while vLLM demonstrates robust performance with AWQ quantization, TensorRT-LLM can leverage fp8 precision, optimized for NVIDIA's latest H100 GPUs, to enhance performance.
That said, we can compare the setup time and complexity of these two inference engines:
- vLLM: streamlined setup – simply install the Python package using pip and define the model you want to use. vLLM is also OpenAI-compatible, making it easier to integrate into your existing infrastructure. While vLLM simplifies the setup process with its straightforward installation and OpenAI-compatible API, its user-friendly approach extends beyond just installation. vLLM also excels in versatility, supporting many models to cater to various application needs.
pip install vllm
llm = LLM(model="meta-llama/Meta-Llama-3-70B") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.
- TensorRT-LLM: Setting up TensorRT-LLM involves a multistep process requiring familiarity with NVIDIA's software stack, Docker, and detailed configuration settings. This setup includes compiling models into TensorRT engines and configuring the NVIDIA Triton Inference Server for deployment, which may pose a steep learning curve for inexperienced developers.
What models does vLLM support?
vLLM supports the most popular open-source LLMs on HuggingFace, including:
- Classic Transformer LLMs (e.g., Llama, GPT-2, GPT-J)
- Mixture-of-Expert LLMs (e.g., Mixtral, Qwen2MoE)
- Multi-modal LLMs (e.g., LLaVA, GPT-NeoX, StableLM)
You can find a complete list here.
vLLM's Development & Popularity
Since July 2023, vLLM has rapidly gained over 20,000 GitHub stars and has a thriving community of 350+ open-source contributors.
Today, thousands of developers use vLLM to optimize their inference, and notable companies like AMD, AWS, Databricks, Dropbox, NVIDIA, and Roblox support it. The University of California, Berkeley, and the University of California, San Diego also directly support the project.
Deploying a vLLM API Endpoint with RunPod Serverless
With help from the vLLM team at Berkeley, RunPod has built vLLM support into their Serverless platform so you can spin up an API endpoint to host any vLLM-compatible model.
To get started, follow these steps:
- Create a RunPod account.
- Navigate to the Serverless dashboard. Under “Serverless vLLM”, click “Start”.
- Input your Hugging Face model. Both private and public models are supported, but you'll need to enter your Hugging Face access token (found here) if you are using a private model.
- Click “Next”. You are given the option to customize your vLLM model settings. For many models, this is not required to run them out of the box. But it may be required for your model if you're using a quantized version like GPTQ, for example, in which case you would need to specify the quantization type in the “Quantization” drop-down input.
- Select your GPU type. For testing purposes, I recommend 80GB (A100).
- Click “Deploy”, then test your endpoint! The "Requests" tab has a UI you can use to test your model, or you can do so via the API endpoints listed on your endpoint dashboard. It usually takes a few minutes for the model to download at first run, then once your worker is ready you should see TTFT (time to first token) latency of <250ms.
vLLM on RunPod enhances model efficiency and provides substantial cost savings, making it an excellent choice for startups scaling their LLM applications to millions of inference requests.
If you'd like to learn more about RunPod or speak with someone on the team, you can book a call from our Serverless page.
Recap – Why You Should Use vLLM
- Performance: vLLM achieves 24x higher throughput than HuggingFace Transformers (HF) and 3.5x higher throughput than HuggingFace Text Generation Inference (TGI).
- Compatibility: vLLM supports hundreds of LLMs and an ever-growing list of dozens of transformer architectures. vLLM is also GPU agnostic, working with NVIDIA and AMD GPUs, making it compatible with any GPU workload.
- Developer ecosystem: vLLM has a thriving community of 350+ contributors who constantly work to improve its performance, compatibility, and ease of use. Typically within a few days of a new breakthrough open-source model being released, it is vLLM compatible.
- Ease of use: vLLM is easy to install and get started with. With RunPod Serverless, you can deploy custom production-ready API endpoints for LLM inference in minutes.
- Customizability: vLLM is a versatile engine that supports OpenAI compatibility, quantization, automatic prefix caching, speculative decoding, and LoRAs.
Thanks for reading! If you want to try vLLM in a cloud GPU environment, check out RunPod Serverless.