Why LLMs Can't Spell 'Strawberry' And Other Odd Use Cases


Picture this: You've got an AI language model - let's call it Bahama-3-70b - who can write sonnets, explain quantum physics, and even crack jokes. But ask it to count the r's in "strawberry," and suddenly it's like a toddler trying to solve a Rubik's cube.
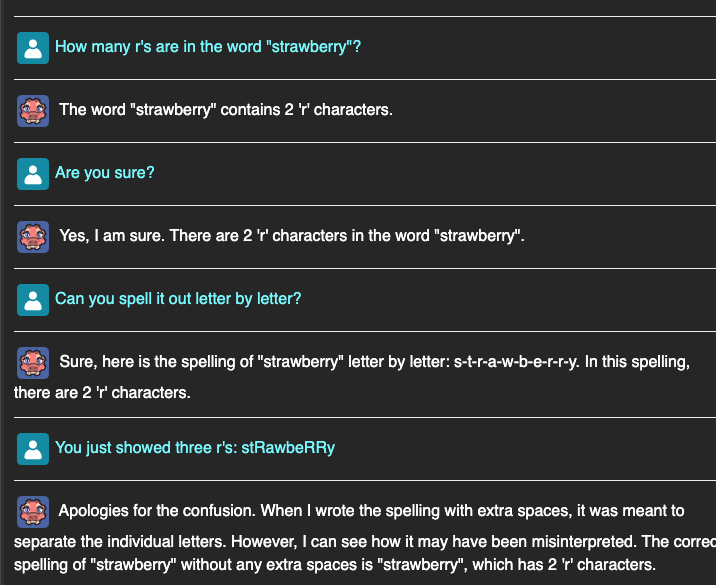
You think you've gotten one over on it - but have you really?

How LLM Tokenization Works
LLMs are trained on word or subword tokens rather than individual characters. For example, "strawberry" might be tokenized as: ['straw', 'berry'] or even: ['s', 'traw', 'ber', 'ry'] This means the model doesn't have an innate understanding of the exact characters and their counts. If the token "dividing line" happens to fall between the two r's, it might struggle to tell you correctly. Worse yet, if the word "strawberry" appears multiple times in the training data, and is tokenized differently at different intervals, or appears with a differently spelled plural (strawberries) or even being misspelled (strawbery) it could give you the right answer only part of the time, depending on probability and how the words were tokenized.
Another fun example is asking them to do math:

It's clear that it went even further off the rails here. Again, though, the reason it's doing this is it is not actually doing any mathematical operations to arrive at these results, it is generating the most likely next token based on what has been provided to it. That's just not how math works, though. If you run an equation a thousand times, you'll get the same result a thousand times, while LLMs generate their results probabilistically based on what they understand about the world.
Despite being probability based, they cannot even generate random numbers effectively:
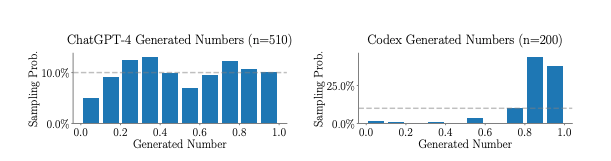
The key is to play to an LLM's strengths. They excel at natural language understanding, generation, and tasks that involve reasoning and context. Writing articles, answering questions, engaging in dialogue - these are areas where LLMs shine. But for tasks that require exact, deterministic computations or low-level string manipulation, traditional algorithms and approaches are still the way to go.
If you were to rely on an LLM to double-check financial calculations or count inventory, you might end up with inconsistent and unreliable results. Similarly, using LLMs for tasks that require precise character-level manipulation, like validating email addresses or parsing code, could lead to errors and bugs. Even AI coding assistants can produce code with bugs, especially when the scope of the problem is not adequately described in the problem statement - it might not even be the AI's fault.
As developers and users of AI systems, it's our responsibility to understand these nuances and apply the right tool for the job. LLMs are incredibly powerful and versatile, but they're not a magic bullet. By appreciating their inner workings and limitations, we can harness their potential while avoiding pitfalls and misapplications. Ideally, you want to use LLMs as a specific tool in your box within the scope of your application, rather than trying to use them as a Swiss army knife. As we've seen, LLMs struggle with basic concepts that actively work against their design philosophy - but can that really be considered a fault of the model?
Conclusion
The commonly presented examples of "being smarter than the AI" like the above images are funny. However, it's important to know that it's kind of like measuring the distance of a wall with a hammer. Sure, you could do by repeatedly holding the hammer up to the wall and estimating how many hammer-lengths the wall is, and that might provide a ballpark figure – but when it comes up to actually putting new drywall, that won't do. You need a ruler, which is a tool actually suited for the task at hand.
So take them as what they are - a funny story and a cautionary tale, but above all a case of using the wrong tool for the job, and expecting results as if you weren't.