Use RunPod Serverless To Run Very Large Language Models Securely and Privately


As discussed previously, a human interacting with a chatbot is one of the prime use cases for RunPod serverless functions. Because the vast majority of the elapsed time is on the human's end, where they are reading, procesisng, and responding, the GPU sits idle for the vast majority of the interaction. Imagine that you are a large organization that needs to provide an internal chatbot for their users, and you handle very sensitive inquiries and need to tightly control where those queries go, along with data provided during the interaction. There are reasons why you would want to avoid pushing this data out onto the Internet, or putting it into the hands of third parties that may end up using it for their own goals.
Problem Statement - Why Closed Models May Not Work For You
While running a large closed source model has certain usability and convenience benefits, you'll quickly run into potential roadblocks for enterprise use, some of which might end up being dealbreakers. What if you deal with trade secrets or other information that you don't want to see the light of day? Even if you trust the LLM platform to handle your input and output responsibly, it is still a black box that you cannot monitor the way you can a RunPod instance.
There are several reasons why it's more beneficial to use a open source system:
- Having access to the actual model weights allows you to more easily create and fine-tune new models.
- It is far more cost effective per token to run a model of this size on RunPod.
- While closed-source LLM providers still allow you to maintain ownership of your output text, they still maintain the right to use your text for training and refining their own services, leading to potential privacy concerns, especially if you work with sensitive data.
- The largest closed-source competitors (Anthropic, OpenAI, et al) have strict policies on what you can and cannot do with their services, to the point of potentially terminating your use of their service or even initiating legal action. You can review the RunPod ToS here for comparison, but suffice it to say that our terms are far more permissive and are only focused on preventing illegal or fraudulent use.
The stated goal of RunPod is to democratize AI - and part of this means we handle your data securely and responsibly, while giving you the privacy to use the service as you see fit.
Resource Requirements
Using a model this large requires VRAM - and lots of it. You'll need to run the model with 8-bit or 4-bit quantization if you want to use NVidia cards, as they currently cap out at 80GB and RunPod maxes out at 8 cards, which isn't enough for the ~800GB before context load that a fp16 405b would require. This will most certainly change in the future as new hardware becomes available, but as of the writing of this article (August 2024) that is where the situation stands.
If you want to use 4-bit or 8-bit, you'll also need to contact us so we can enable your endpoint to use more than two 80GB cards in serverless. (Don't worry, it's a routine, quick ticket!)
You'll also need to set up a network volume large enough to hold the full weights of the model, so we recommend at least a 900gb volume just to ensure there is enough room in the volume for any overhead that might be required.
What 405B models are currently available?
Due to the resources required to train and create them, there are only a few 405b models available, but they do exist:
- The original Llama-3 base and instruct models
- NousResearch/Hermes-3-405b
- migtissera/Tess-405b
The Llama-3 and Hermes models have FP8 versions already configured to work with vLLM, so we would recommend using those for ease of configuration and implementation.
- NousResearch/Hermes-3-Llama-3.1-405B-FP8
- meta-llama/Meta-Llama-3.1-405B-Instruct-FP8
- meta-llama/Meta-Llama-3.1-405B-Instruct
Honorable mention: There's also Mistral-Large, which performs comparably despite only being about 120b.
How to get up and running
First, you'll need to set up a network volume to hold a model this large, without question. We highly recommend selecting a data center with A100/H100 availability.
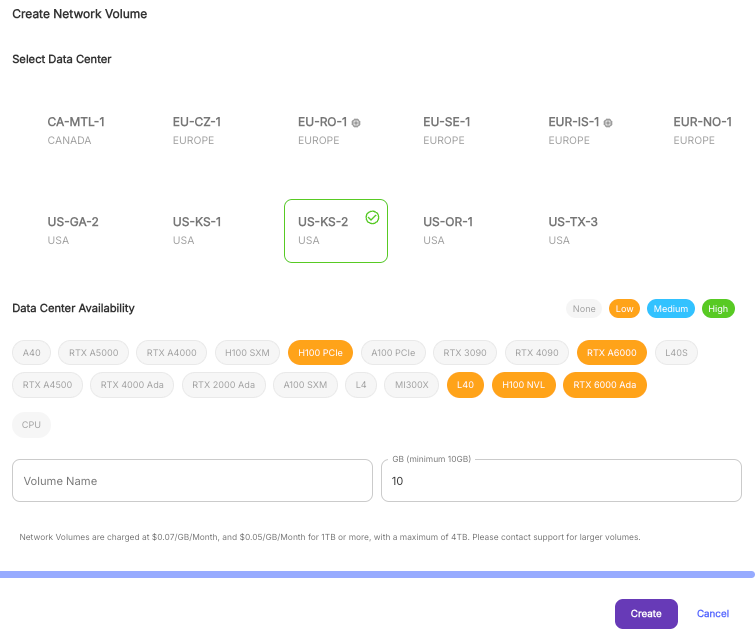
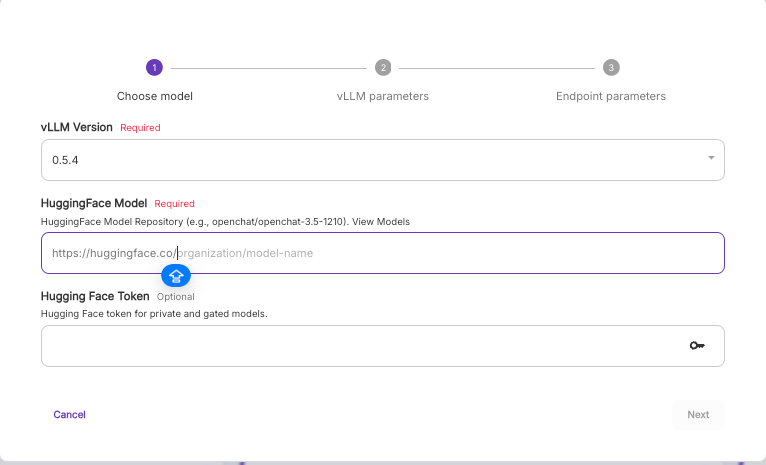
Next, you'll need to set up an endpoint, preferably a vLLM Quick Deploy template if you're just trying to get up and running with as little configuration as possible. Note that if you're using one of the gated (Meta) models above you'll also need to include your HF token. Everything else under vLLM Parameters can be left as is unless you have a specific need to change them.
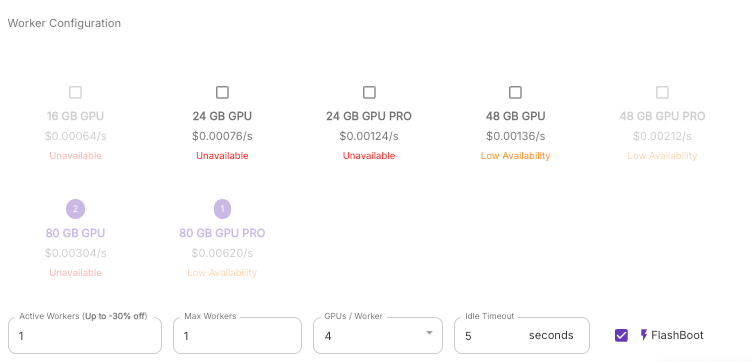
Under the worker configuration, you'll need to set some very specific fields:
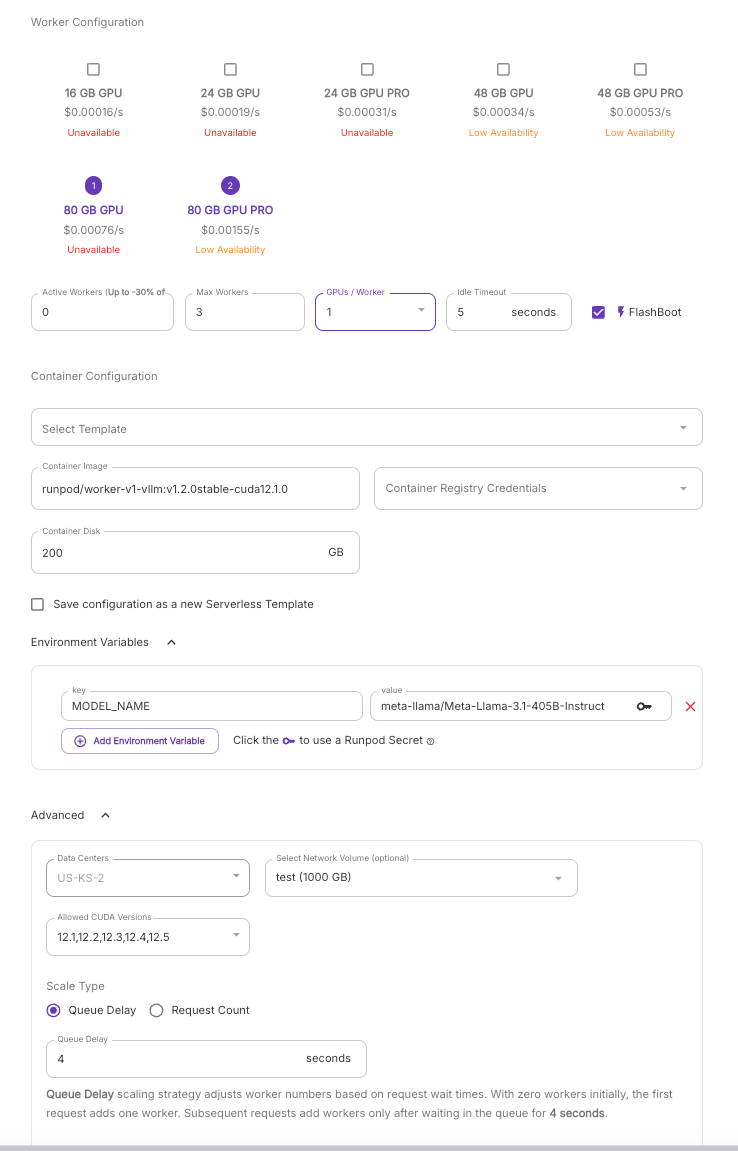
- MODEL_NAME under Environment Variables - should be prepopulated, but ensure that it is corect.
- Network Volume - you'll need to attach your network volume here.
- GPU Type - Select the 80 GB models only.
Once the endpoint is created, take note of the endpoint ID:
Contact our support team with that endpoint ID and let us know that you need your GPUs per worker increased to 8 for 80GB cards and we can increase it for you. Once that has been done, you can go back into GPU/Workers and change it to however many you need.
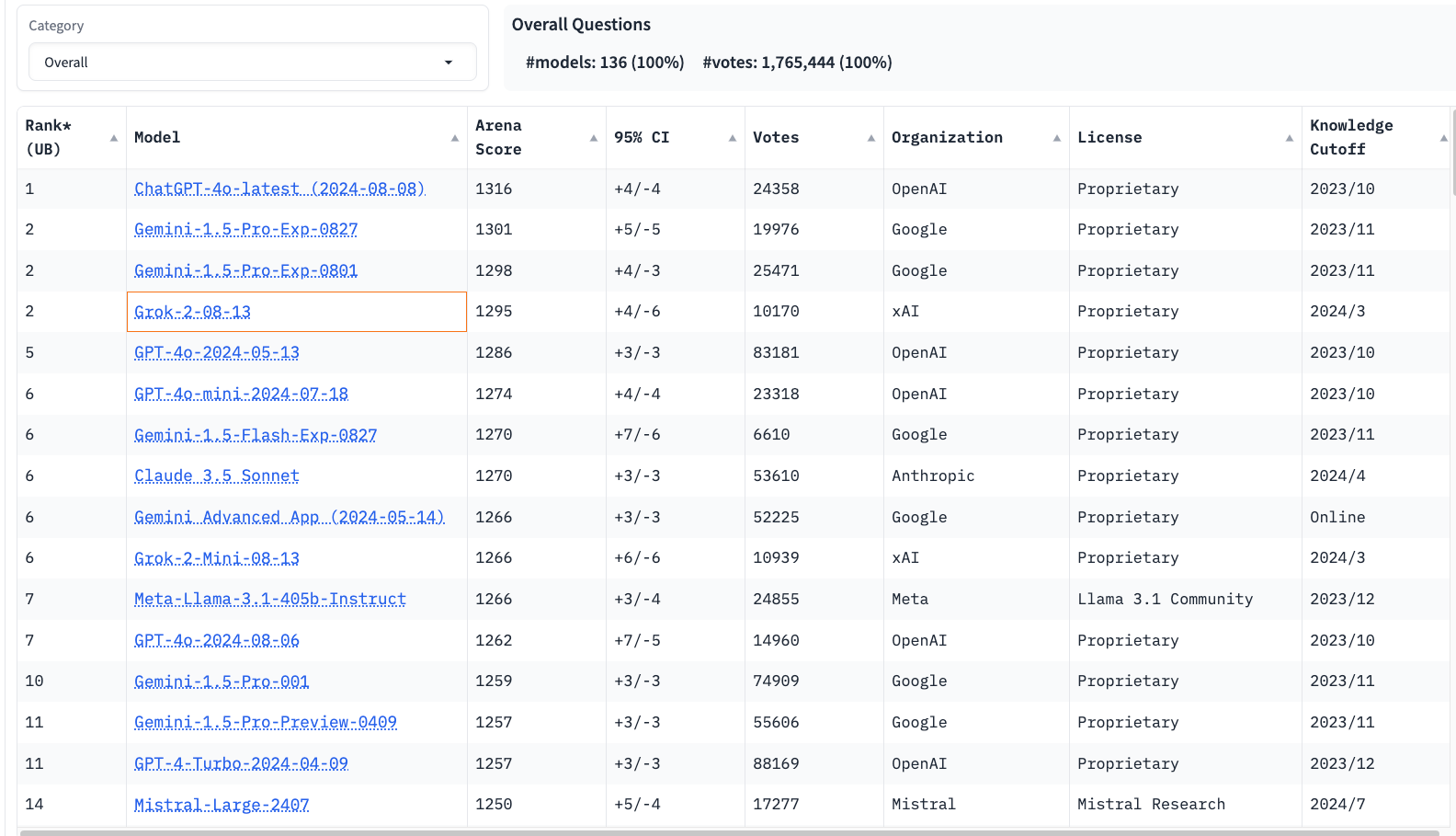
How well do these large models perform?
As of the writing of this article, Llama 405b and Mistral Large are the only open source models on the top page of LMSys Chatbot Arena that can be run locally in an environment such as RunPod. If you are looking for the highest performing model for your spend, you'll want to start your experimentation with these two.
At our current serverless prices, an H100 running at $0.00155 per second, times four cards, times ten seconds for a request, would cost you about $0.06 to fulfill that request. Compare this to running an 8k token request through the Claude Opus API, which could run you $0.20-$0.30, and what you'll be saving on RunPod really comes into stark focus.
Conclusion
Running the largest models around is now a feasible activity on RunPod as we continue to add supply and enhance our serverless architecture. All you need to do to get started is to create an endpoint and let our support team know so we can increase your maximum GPUs per worker. You can get started with the process today by letting us know here.
Feel free to share your experiences and use cases on our Discord as well! What do you think are the most applicable use cases for these large models in serverless?