Train Your Own Video LoRAs with diffusion-pipe


You can now train your own LoRAs for Flux, Hunyuan Video, and LTX Video with tdrussells' diffusion-pipe, a training script for video diffusion models. Let's run through an example of how this is done with Hunyuan Video.
Start Up a Pod
First, start up a pod with at least 48GB of VRAM. For smaller datasets (a couple of videos) this will do, but for anything larger you'll need 80GB. Bear in mind that the package will split videos into chunks to match the training length, so even a few videos can easily represent a fairly comprehensive dataset. I recommend using the Better Comfy template as a base as this will let us most easily test our model after training the LoRA. This will also give us access to VSCode so we can send and receive files and run the training process without worrying about our web terminal session being disconnected and killing the run. You can access VSCode by connecting to port 7777, going into the Command Palette and then starting your terminal there.

Clone the repo into your workspace folder per its instructions:
git clone --recurse-submodules https://github.com/tdrussell/diffusion-pipe
pip install -r requirements.txtInstall git lfs as well per the instructions:
apt-get update
apt-get install git
apt-get install git-lfs
git lfs installCreate a models folder in your workspace folder, and then pull the video transformers and vae files in:
mkdir models
cd models
wget https://huggingface.co/Kijai/HunyuanVideo_comfy/resolve/main/hunyuan_video_720_cfgdistill_bf16.safetensors
wget https://huggingface.co/Kijai/HunyuanVideo_comfy/resolve/main/hunyuan_video_vae_bf16.safetensorsClone the LLM and CLIP model into the same folder:
git clone https://huggingface.co/Kijai/llava-llama-3-8b-text-encoder-tokenizer/
git clone https://huggingface.co/openai/clip-vit-large-patch14Setting up a training run
Now that that's all set, we're finally ready to configure our training run.
In your VSCode go to your /workspace/diffusion-pipe/examples folder and let's edit the hunyuan_video.toml file to point our config at the models we downloaded:
transformer_path = '/workspace/models/hunyuan_video_720_cfgdistill_bf16.safetensors'
vae_path = '/workspace/models/hunyuan_video_vae_bf16.safetensors'
llm_path = '/workspace/models/llava-llama-3-8b-text-encoder-tokenizer'
clip_path = '/workspace/models/clip-vit-large-patch14'Create a /train/ folder in your workspace and upload your videos and text annotations. The format is uploading the videos with a specific name, and then the annotation goes in a text file with the same name as the video. e.g.:
video_1.mp4
video_1.txt: mytrain, a sunrise slowly peeking up over the horizonIt's generally useful to give the files a specific tag that doesn't clash with any tokens you might use in the prompt so you can call it without interfering with the output.
Update the output path in dataset.toml to go to your workspace folder, and the output directory in hunyuan_video.toml to point to the folder you want to save your trained LoRAs to.
path = '/workspace/train'output_dir = '/workspace/data/diffusion_pipe_training_runs/hunyuan_video_test'
Running your train
Run the following in the terminal to kick off your train:
NCCL_P2P_DISABLE="1" NCCL_IB_DISABLE="1" deepspeed --num_gpus=1 train.py --deepspeed --config examples/hunyuan_video.tomlYou can edit any parameters for training that you would like under the Training Settings but you should be able to get a functional train with the default settings. It will save the LoRA every two epochs by default.
Rendering Videos with your LoRA in ComfyUI
If you need help setting up the workflow in ComfyUI, we have a video for that here:
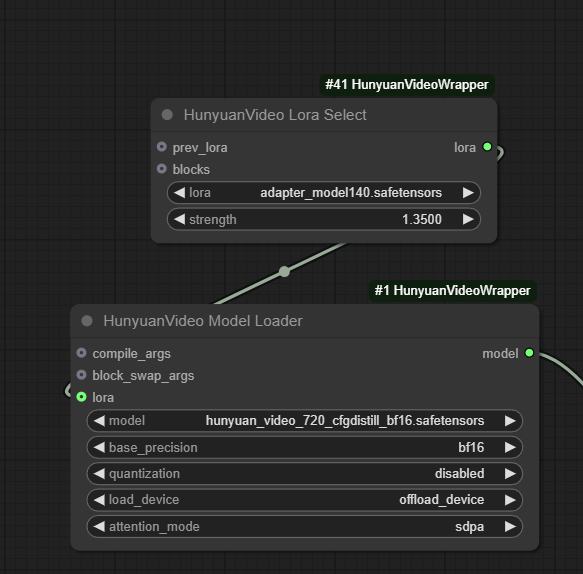
As the train continues, you can test them in another pod with the HunyuanVideo Lora Select node in ComfyUI after you upload the files to the /loras/ folder. If you're not seeing results yet, you can try increasing the strength to get a preview of how the training is going (though increasing to 2 or higher will get you increasingly severe artifacting.) It's recommended to set up two pods; one for the train and another to create videos with. You can download the LoRAs from your train pod locally and then upload them to your rendering pod with VSCode.
There are two major variables to play with:
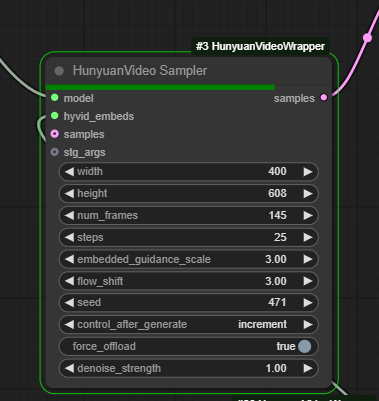
embedded_guidance_scale: Controls the amount of creativity in the model - lower values have the result resemble the training data more. Acts similar to CFG in Stable Diffusion.
flow_shift: This variable controls how much a given frame is able to deviate from the prior frame. Generally, higher flow shift will result in more dramatic movement because it will be given more leeway - setting flow shift to very low values will just give you an extremely blurry image because it won't be able to denoise anything. However, a very high value may not necessarily result in dramatic movement overall - e.g. in the case of a person doing a pose, it may trigger a sharp limb movement at the start that would have not passed a lower value, but the presence of that now sharper movement may lead the model down an overall more sedentary path. Think of this as a gate that allows more dramatic movement through, but not a guarantee of such. If you're looking for photorealism you'll probably want this value to be lower (2-4) as the higher value you go with the more likely you'll run into an artificial, shiny look as that requires sharper changes in pixel values. This is a value that needs a lot of experimentation, though, as it can differ wildly from prompt to prompt and even seed to seed, so doing several generations at different value steps can help a lot.
Guidance scale and flow shift have enormous amounts of interplay and can drastically change how an image looks even with small changes. You'll definitely want to keep track of good seeds that have the result you're looking for and play with these two values to perfect the look you want.
Conclusion
Although the process seems a bit intimidating, once you run through the process a few times it'll become like second nature. If you have any questions, feel free to ask on our Discord!