SuperHot 8k Token Context Models Are Here For Text Generation


Esteemed contributor TheBloke has done it again, and textgen enjoyers everywhere now have another avenue to further increase their AI storytelling partner's retention of what is occurring during a scene. Available on his GitHub are quantizations of several well known models, including but not limited to the following:
WizardLM (7B, 13B, 33b)
Vicuna (7B, 13B, 33B)
Manticore (13B)
Airboros (7B, 13B, 33B)
Tulu (7B)
Selfee (7B, 13B)
Koala (13B)
Why is increased context important?
As someone that has written with human partners for much of my life, I've found that one of the most jarring aspects of switching to an AI model is how easily it forgets critical details after they pass out of the context window. While humans have effectively an unlimited context window (since they can review any length of a log to remind themselves) that's unfortunately not an option with LLMs with the way that we currently know them. For example, details critical to a scene such as a character's body positioning, what they're wearing, and so on can easily be forgotten, forcing the AI to guess and potentially breaking immersion when it's incorrect. While there are ways to alleviate this such as using the character sheet to hold persistent information or constantly drip-feeding contextual reminders in your poses, the truth is that a 2k token context limit is just not a lot, especially since you need to devote at least a third of that to the Character page to have a properly fleshed out bot. That effectively gives you about ten to fifteen full paragraphs of text within your text log before it's going to need reminders.
When sitting down to write a character, I've gotten great results by devoting two full paragraphs to their personality (such as motivations, occupation, and history) and two to their appearance (physical attributes, clothing, etc.). When combined with a hearty intro prompt along with a few snippets of example dialogue, I usually have about 800 tokens used right out of the bat. Having 8k of context means that I can now write entire additional paragraphs about the character's history which can further inform the model's use of the character sheet while still enjoying a much greater context window for events actually occurring in the story. We'll get into how to effectively use the additional context in a character sheet in the next article.
(For reference, even the mighty ChatGPT only had a 4k context limit until a couple of months ago, to really drive home how big news an 8k limit is!)
How to get started
If you've been using any of the major model lines such as Pygmalion or WizardLM, chances are there is now a SuperHOT version of it available. Searching Huggingface for SuperHOT will bring up all variations available, so it's just a matter of picking your favorite and downloading it using the Models page within your pod.
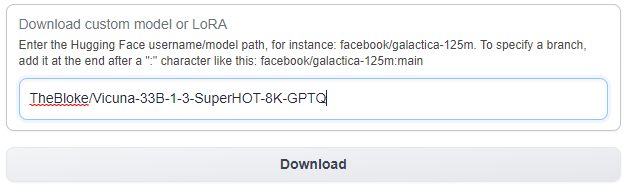
Important: Be sure to check the main model page for any additional instructions required to configure the model. If you are using a Llama model, for example, these models will run into problems past 2k tokens of context if you leave them on the default settings. For most of the Llama models, you'll need to use ExLlama as the loader and manually increase the max_seq_len and compess_pos_emb variables as shown below.
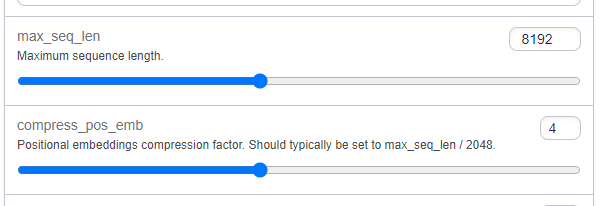
You'll also need to ensure that the context window is also increased appropriately (though the latest version of Oobabooga should set this automatically.)

Questions?
Feel free to reach out on our Discord if you have any questions!