Stability.ai Releases Stable Diffusion 3.5 - What's New in the Latest Generation?


On October 22, Stability.AI released its latest version of Stable Diffusion, SD3.5 There are currently two versions out (Large and Large Turbo), with the former geared towards quality while the latter favoring efficiency. Next week, Medium will release, aimed at smaller GPU specs. You can quickly and easily run even the largest version on RunPod with just a few clicks - read on to get the scoop on what SD3.5 offers over prior versions as well as a quick start guide to begin your creative journey on the latest version.
What's new in the latest generation?
The release of SD3 was.. mixed, to put it lightly, as the model had seemed to take a step backwards in addressing the long-standing problems with anatomy expression in image generation. Fortunately, 3.5 seems to have made strides in righting the boat while being able to generate images up to 2mp in size. Based on my initial testing, it seems to generate photorealistic people and animals with just very minimal prompting. It does have limits (asking it to generate "black and white argentine tegu" generated some very not-tegu looking reptiles) but that is a job for training and fine-tuning, regardless. As a base model, it seems quite adept at generating immediately usable images with very basic prompting, without much indication of the flaws of the previous version.
Moreover, it seems to generate genuinely photorealistic images out of the box. Back in the day there were prompt hacks to try to coax the model into doing so (one of my favorites was including random camera makes and models in the prompt) but now it just does so without being necessarily being asked. Clearly, there has been an eye for quality in the images being fed into training in this latest iteration.



Quick Start
If you just want to immediately begin generating images in less than two minutes, then look no further - this is what you'll need to do. You'll be able to get it running on a pod immediately for well less than a dollar per hour.
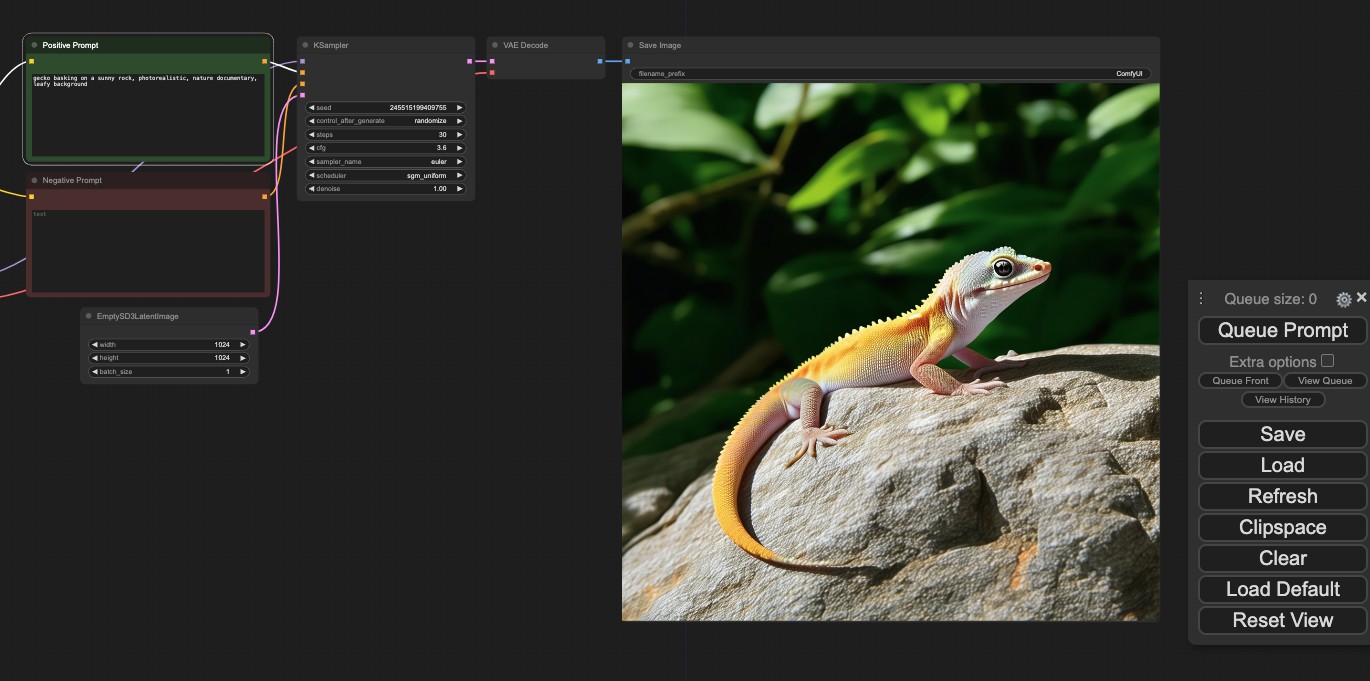
- Click here to navigate to the Stable Diffusion 3.5 Large template by Camenduru, and click Deploy.
- Select a GPU spec (ideally 24GB or larger for simplicity's sake) and click Deploy on Demand, and then go to My Pods. Because this is quite a large image (~20 GB) it will take some time to download.
- Once the pod is up and running, click Connect to access the ComfyUI screen.
- Download this workflow to your desktop, and then drag it into the ComfyUI window.
- Go to the Positive Prompt panel, enter your prompt, and then click Queue Prompt, and you will have your image.
Camenduru also has a serverless image available for use on RunPod. We will likely have a Quick Deploy serverless image coming in the very near future, but if you'd like to experiment on the cutting edge feel free to clone the repo and use our Serverless tutorials to create and push your own Docker image.
As this is a brand new base model, the community will be starting from scratch generating new checkpoints and finetunes of 3.5, but if history is anything to go by they will not be far behind. We would recommend watching the CivitAI models page filtered on SD 3.5 to see what the community comes up with in the coming days and weeks, and remember we also have the Better Launcher series that will let you save any number of checkpoints to a network drive for easy access.
Conclusion
The release of a base model is always momentous - fine-tuning a model is relatively accessible, but to train a model from scratch often requires organization-level resources and it always feels like Christmas when a brand new model drops. Although we at RunPod pride ourselves at being the development platform for all types of AI, our roots were built on AI art and we are always thrilled to share opportunities like this with you. A big thanks to Camenduru for the template and worker contributions and we invite you to share your experiences with the model on our Discord.