Spin up a Text Generation Pod with Vicuna And Experience a GPT-4 Rival


Why use Vicuna?
The primary benefit of Vicuna is that it has a level of performance rivaled only by ChatGPT and Google Bard. The model has been tested across a wide variety of scenarios, including Fermi problems, roleplay scenarios, and math tasks, and a framework graded by GPT-4 showed that it handily beat out other models such as LLaMa and Alpaca. (And given how much press GPT-4 has itself gotten recently, the fact that it's effectively given Vicuna its stamp of approval should really mean something.) Trained on 13 billion parameters, Vicuna is best able to work in natural language processing applications and is best suited to chatbots and the like, which makes it a prime model for anything that requires a human touch. You can see the results of GPT-4's evaluations of Vicuna on their website.
In my personal testing, I've also found Vicuna to be at least more resistant to hallucinations than iterations such as ChatGPT, which tends to overshare things that it may not really know much about and is still very open to confidently sharing things that it does not know as fact. Vicuna, on the other hand, is a bit more taciturn, but also can be more thoroughly trusted in its responses.
Unlike GPT-4 and Bard, the model is open source and can be run locally for free on any platform you choose - including RunPod! In addition, because it is open to the community, you can easily tweak its parameters to suit your needs.
How to Install Vicuna
First things first - spin up a pod with the "RunPod Text Generation UI" (oobabooga:1.0.0). You'll also want to bump up the container size to at least 25gb, since we'll be downloading and installing the Vicuna model once we get the pod up and running.
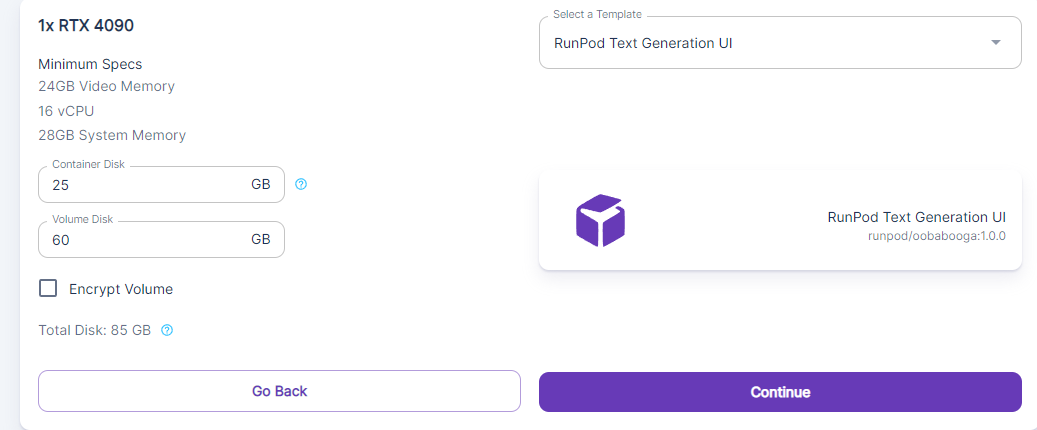
Once you've got the pod created, open Jupyter Notebook and open up the terminal. Enter the following in the terminal to download the Vicuna model.
cd text-generation-webui
python download-model.py HenryJJ/vincua-13b
This will download the Vincua model from Huggingface, which is the flavor I've chosen to demonstrate the install. (The main Vicuna model does not appear to be on the site, for some reason – only its deltas, so I chose another iteration to demonstrate a fresh install.) There's roughly 15gb of files involved, so it may take a few minutes. Because there are so many individuals in the community tweaking the model, there are many different potential Vicuna derivations to experiment with. Searching Huggingface for Vicuna should bring up a number of potential options to play with, allowing you to get acquainted before tweaking the model as needed.
Downloading the model to models/vincua-13b
Downloading file 1 of 9...
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 507/507 [00:00<00:00, 331kiB/s]
Downloading file 2 of 9...
100%|██████████████████████████████████████████████████████████████████████████████████████████████████| 137/137 [00:00<00:00, 81.1kiB/s]
Downloading file 3 of 9...
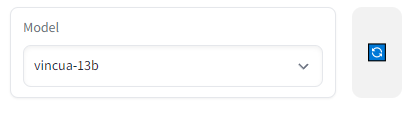
Once the model is downloaded, switch to the Vicuna model like so. Hit the blue Refresh icon to the right if it doesn't appear.
How to use Vicuna
As stated, Vicuna is great at anything involving natural language, which lends itself well to roleplay, question answering, and anything where you would need the "human touch."
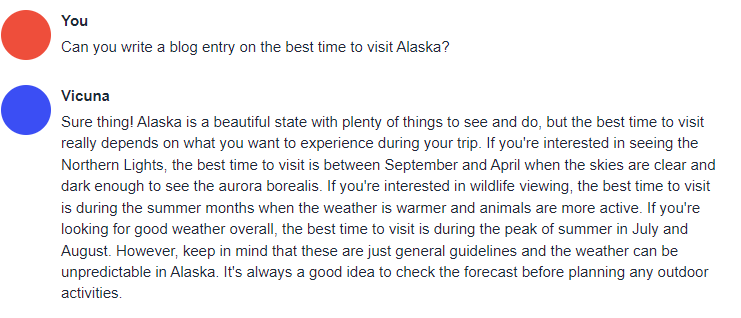
Have any questions about how to get Vicuna up and running? Hit us up on our Discord server!