RunPod Roundup 5 - Visual/Language Comprehension, Code-Focused LLMs, and Bias Detection


Welcome to the Runpod Roundup for the week ending August 26, 2023. In this issue, we'll be discussing the newest advancements in AI models over the past week, with a focus on new offerings that you can run in a RunPod instance right this second. In this issue, we'll be looking at large language model evaluation, vector search, and 3D scene reconstruction.
Alibaba Research's Visual Qwen (Qwen-VL Series) - Vision-Language Models To Understand Both Text and Images
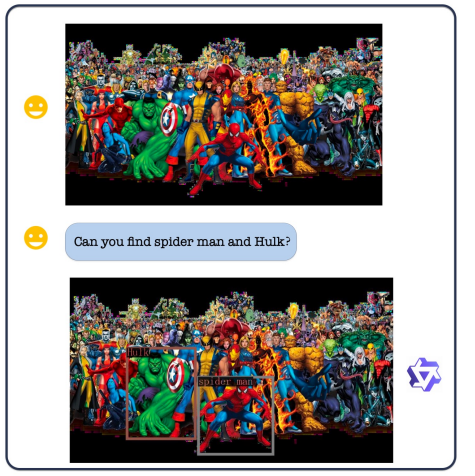
Following the release of its Chinese-language Qwen LLM, Alibaba Research has released a new format of the model that can digest and understand images and provide summaries, identification, conversations, and more. For example, when given an image containing several different superheroes, Qwen-VL will be able to identify specific individuals in the lineup. The Chat model is especially robust and can compose stories, produce images, and ingest multiple images for consideration in a single prompt. You can grab the Qwen-VL model from their Huggingface repo here.
Meta Releases Code Llama, Its Code-Focused Large Language Model
Meta has now added to its open-source Llama-2 based offerings with Code Llama, an LLM tuned specifically around generating code as well as summarizing it in natural language. The model comes in both a general as well as a Python-specific flavor, along with an instruct model tuned for natural language instructions. If you've ever used ChatGPT to help you diagnose coding problems, this might very well be a far more economical alternative, especially since the smaller 7 and 13b versions can easily be run in even the smallest GPU specs on RunPod. Check out Meta's press release on the model here.
FACET Dataset Helps Evaluate the Fairness of Computer Vision Models
Concerned about potential biases in your datasets? Looks like Meta has you covered there, too, as they have just released a new benchmark for sussing out potential biases in computer vision models. Bias has long been an insidious problem in AI, as models are only as good as the data they are trained on, and data collection and training resources are also finite so it is easy for that bias to unknowingly creep in. You can read more about their benchmark and applications here.
Questions?
Feel free to reach out to RunPod directly if you have any questions about these latest developments, and we'll see what we can do for you!