Announcing Global Networking For Cross-Data Center Communication


RunPod is pleased to announce its launch of our Global Networking feature, which allows for cross-data center communication between pods. When a pod with the feature is deployed, your pods can communicate with each other over a virtual internal network facilitated by RunPod. This means that you can have pods talk to each other without opening TCP or HTTP ports to the Internet, as well as share data and run client-server apps over multiple pods in real time.
This feature is currently live for the following data centers, with a 100mbps link limit to start, with new expansions planned in the near future. 'CA-MTL-3', 'US-GA-1', 'US-GA-2', 'US-KS-2'
How to start
You can enable Global Networking in your pod by checking the Global Networking checkbox under the Instance Pricing option while deploying your pod.
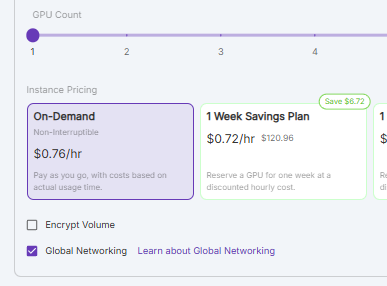
When the pod is created, it will assign a virtual Global Network Hostname that can be communicated with via any other Secure Cloud pods that were also created with Global Networking, regardless of which data center they reside in.
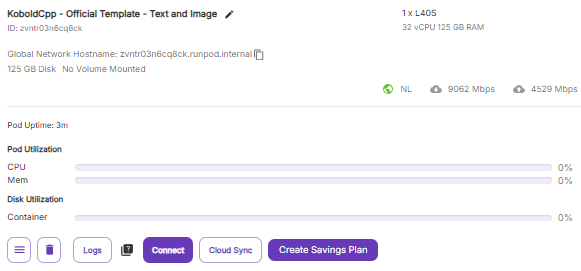
As a quick test and demonstration, communication between pods can be tested with ping (run apt-get update, apt-get install iputils-ping if it's not already set up in your pod.)
root@231f5907a67c:/# ping 8wfunnt6l6aoeb.runpod.internal
PING 8wfunnt6l6aoeb.runpod.internal (10.1.58.249) 56(84) bytes of data.
64 bytes from 10.1.58.249 (10.1.58.249): icmp_seq=1 ttl=64 time=319 ms
64 bytes from 10.1.58.249 (10.1.58.249): icmp_seq=2 ttl=64 time=144 ms
64 bytes from 10.1.58.249 (10.1.58.249): icmp_seq=3 ttl=64 time=143 ms
64 bytes from 10.1.58.249 (10.1.58.249): icmp_seq=5 ttl=64 time=143 msCode Demonstration
Here's a quick proof of concept of how to accomplish this in Python. Run this script in both pods that you want to test the feature in:
import os
import torch
import torch.distributed as dist
import time
import socket
import datetime
def check_connection(host, port):
"""Test if we can connect to the master address."""
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(2)
result = sock.connect_ex((host, port))
sock.close()
return result == 0
except Exception as e:
return False
def setup(rank, world_size, master_addr, master_port=29400, timeout=60):
"""Initialize the distributed environment with timeout and connection checking."""
cleanup()
print(f"\nInitializing process group...")
print(f"My rank: {rank} (rank 0 = master node)")
print(f"World size: {world_size}")
print(f"Master address: {master_addr}:{master_port}")
# Only check connection if we're not the master
if rank != 0:
if not check_connection(master_addr, master_port):
print(f"Warning: Cannot connect to master at {master_addr}:{master_port}")
print("This is normal if master hasn't started yet - will keep trying...")
else:
print("I am the master node - starting distributed process...")
os.environ['MASTER_ADDR'] = master_addr
os.environ['MASTER_PORT'] = str(master_port)
# Initialize with timeout
start_time = time.time()
print(f"Attempting to initialize process group (will timeout after {timeout} seconds)...")
try:
# Initialize process group with timeout
dist.init_process_group(
backend="nccl",
init_method=f"tcp://{master_addr}:{master_port}",
world_size=world_size,
rank=rank,
timeout=datetime.timedelta(seconds=timeout)
)
print(f"Successfully initialized process group for rank {rank}!")
print(f"Process group info:")
print(f"- Backend: {dist.get_backend()}")
print(f"- World size: {dist.get_world_size()}")
print(f"- Rank: {dist.get_rank()}")
return True
except Exception as e:
print(f"Error during initialization: {str(e)}")
return False
def cleanup():
"""Clean up the distributed environment."""
if dist.is_initialized():
print("Cleaning up existing process group...")
dist.destroy_process_group()
time.sleep(1)
def run_simple_test():
"""Run a very simple test that doesn't require distributed setup."""
print("\nRunning local GPU test...")
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"Number of GPUs: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("No CUDA GPUs available!")
def run_test(rank, world_size, master_addr, master_port=29400, timeout=60):
"""Run test with better debugging."""
try:
# First run local GPU test
run_simple_test()
# Try to set up distributed
if not setup(rank, world_size, master_addr, master_port, timeout):
print("Failed to initialize distributed setup")
return
print("\nStarting distributed test...")
# Create a simple tensor on GPU
tensor = torch.zeros(1).cuda(rank)
# Simple all-reduce operation
if rank == 0:
tensor += 1
print("Master node: Setting tensor to 1")
print(f"Rank {rank}: Before all_reduce(), tensor = {tensor}")
# All processes participate in all-reduce
print(f"Rank {rank}: Attempting all_reduce operation...")
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"Rank {rank}: After all_reduce(), tensor = {tensor}")
print(f"Rank {rank}: Test completed successfully!")
except Exception as e:
print(f"Error occurred: {str(e)}")
raise
finally:
cleanup()
# Helper function to get basic network info
def print_network_info():
hostname = socket.gethostname()
try:
local_ip = socket.gethostbyname(hostname)
print(f"\nNetwork Information:")
print(f"Hostname: {hostname}")
print(f"Local IP: {local_ip}")
# Try to resolve master hostname
try:
master_ip = socket.gethostbyname('8wfunnt6l6aoeb.runpod.internal')
print(f"Master hostname resolves to: {master_ip}")
except:
print("Could not resolve master hostname")
except Exception as e:
print(f"Could not get network info: {str(e)}")
# Print network info first
print_network_info()
run_test(rank=0, world_size=2, master_addr='8wfunnt6l6aoeb.runpod.internal')Change the bottom line to rank 0 for your 'master' node, and then rank 1 for your 'worker' node. Set the master_ip and master_addr to be the Global Networking hostname for both pods.
run_test(rank=0, world_size=2, master_addr='8wfunnt6l6aoeb.runpod.internal')You should see the following to show that it was successful.
Network Information:
Hostname: 231f5907a67c
Local IP: 192.168.64.2
Master hostname resolves to: 10.1.58.249
Running local GPU test...
PyTorch version: 2.1.0+cu118
CUDA available: True
Number of GPUs: 1
GPU 0: NVIDIA RTX A6000
Initializing process group...
My rank: 1 (rank 0 = master node)
World size: 2
Master address: 8wfunnt6l6aoeb.runpod.internal:29400
Attempting to initialize process group (will timeout after 60 seconds)...
Successfully initialized process group for rank 1!
Process group info:
- Backend: nccl
- World size: 2
- Rank: 1This is just merely an example, of course, and you could build any number of applications that utilize resources on more than one pod. If you want to share files between pods, you could utilize something like NFS to do this at the operating system level on one pod:
# Install NFS server
apt-get install nfs-kernel-server # (Ubuntu/Debian)
# Export the directory
echo "/path/to/volume *(rw,sync,no_subtree_check)" >> /etc/exports
exportfs -a
systemctl restart nfs-serverOn the other:
# Install NFS client
apt-get install nfs-common # (Ubuntu/Debian)
# Mount the volume
mount 8wfunnt6l6aoeb.runpod.internal:/path/to/volume /local/mount/pointRemember, all pods enabled with Global Networking have internal TCP/IP connectivity that is not exposed to the outside world, and communicate on the *.runpod.internal network. Although you are certainly free to open up ports as needed for your use case, no open ports are required for pods to talk to each other with Global Networking. Another option would be to set up a file server internally to share files, and with no exposed TCP or HTTP ports you can feel confident that this server has no link to the wider Internet.
Conclusion
This feature has been a long time coming, and we are thrilled to finally launch it, especially since we realize that previously being locked to a specific data center for a network volume can feel extremely limiting.
If you have any questions on how to best utilize this feature, please reach out to our support team or Discord for further guidance!