Run Llama 3.1 with vLLM on RunPod Serverless


In this blog, you'll learn:
- About RunPod's latest vLLM worker for the newest models
- Why vLLM is an excellent choice for running Meta's Llama 3.1
- A step-by-step guide to get Meta Llama 3.1's 8b-instruct version up and running on RunPod Serverless with the quick deploy vLLM worker.
Introduction to Llama 3.1 and vLLM
Meta Llama 3.1 is the latest iteration of Meta's powerful open-source language model. It offers improved performance and capabilities compared to its predecessors. While not as large as its 405B counterpart, the 8B instruct version provides a balance of capability and efficiency that's ideal for many use cases. Compared to their predecessors, the Meta Llama 3.1 models perform exceptionally well in benchmark tests:
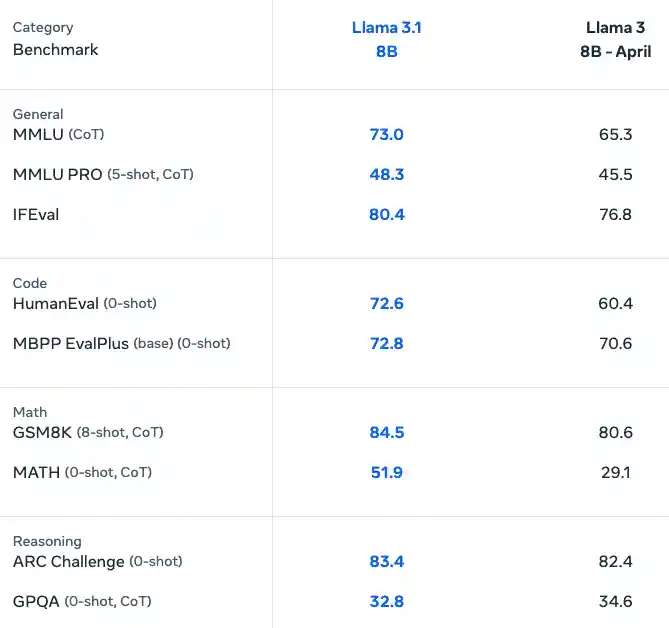
Why use vLLM for Llama 3.1?
To run our Meta Llama 3.1 model, we'll leverage vLLM, an advanced inference engine designed to enhance the performance of large language models dramatically. Here are some of the reasons vLLM is a superior option:
- Unmatched Speed: vLLM significantly outpaces other frameworks, offering 24 times the throughput of HuggingFace Transformers and 3.5 times that of HuggingFace Text Generation Inference (TGI).
- Wide-ranging Model Support: vLLM is compatible with a vast array of language models and continuously expands its support for various transformer architectures. Its GPU-agnostic design allows seamless operation on both NVIDIA and AMD hardware, adapting to diverse computational environments.
- Robust Community Backing: With over 350 active contributors, vLLM benefits from a dynamic ecosystem of developers. This community ensures rapid improvements in performance, compatibility, and user experience. New breakthrough open-source models are typically integrated within days of their release.
- User-Friendly Setup: Getting started with vLLM is straightforward with RunPod's quick deploy option.
The key to vLLM's impressive performance lies in its innovative memory management technique known as PagedAttention. This algorithm optimizes how the model's attention mechanism interacts with system memory, resulting in significant speed improvements. If you're interested in delving deeper into the inner workings of PagedAttention, check out our detailed blog post dedicated to vLLM.
Now let's dive into how you can start running vLLM in less than a few minutes.
How to deploy Llama 3.1 8b with vLLM on RunPod Serverless
Follow the step-by-step guide below with screenshots to run inference on the Meta Llama 3.1 8b instruct model with vLLM in less than a few minutes. Please note that this guide can apply to any open large language model so feel free to experiment with other Llama or open-source large language models by swapping in their hugging face link and model name in the code.
Pre-requisites:
- Create a RunPod account here. Heads up, you'll need to load your account with funds to get started.
- Pick your Hugging Face model and have your Hugging Face API access token (found here) ready if needed.
Quick Deploy Llama 3.1 vLLM and test with RunPod Web UI
- Navigate to the Serverless tab here in your RunPod console and hit the Start button on the Serverless vLLM card under Quick Deploy. This will automatically install vllm and run it for you as an endpoint.
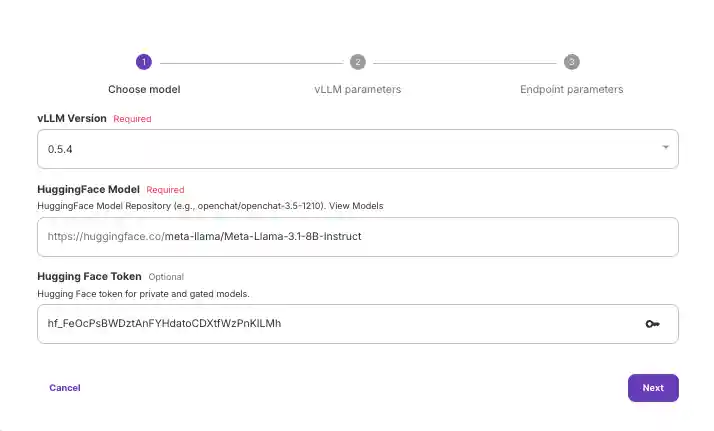
- Input your Hugging Face model along with the access token that you can get from your Hugging Face account (found here).
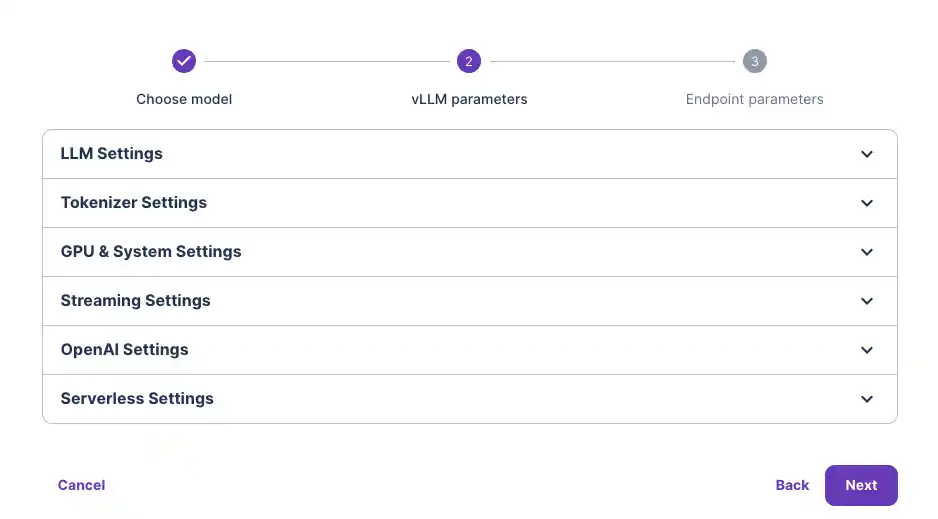
- You are given the option to customize your vLLM model settings. For most models, this is not required to get them running out of the box. But it may be required for your model if you're using a quantized version like GPTQ, for example, in which case you would need to specify the quantization type in the “Quantization” drop-down input. For now, our defaults should be fine.
- Select the GPU type you would like to use. For a guide to selecting the right GPU VRAM for your LLM, checkout our blog: Understanding VRAM and how Much Your LLM Needs. To account for the 8b model storage, torch reserved space for kernels, etc we go with the 48gb GPU. We won't need multiple GPUs. Click Deploy.
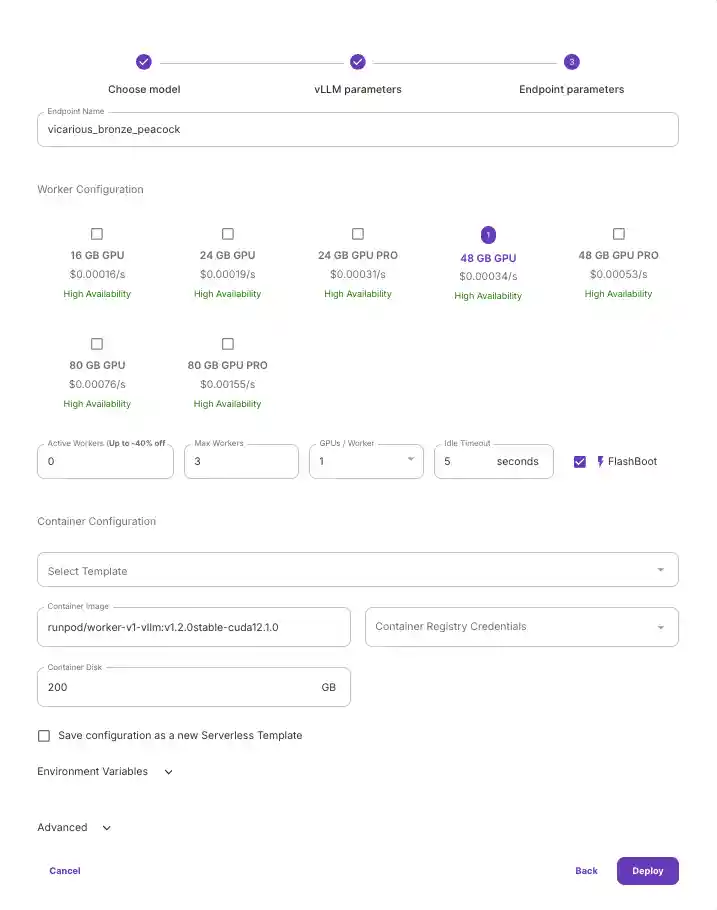
Note: If we were to quantize our model or limit the context window, we could opt for a smaller GPU.
- Now that you’ve deployed your model, let’s navigate to the “Requests” tab and test that our model is working.
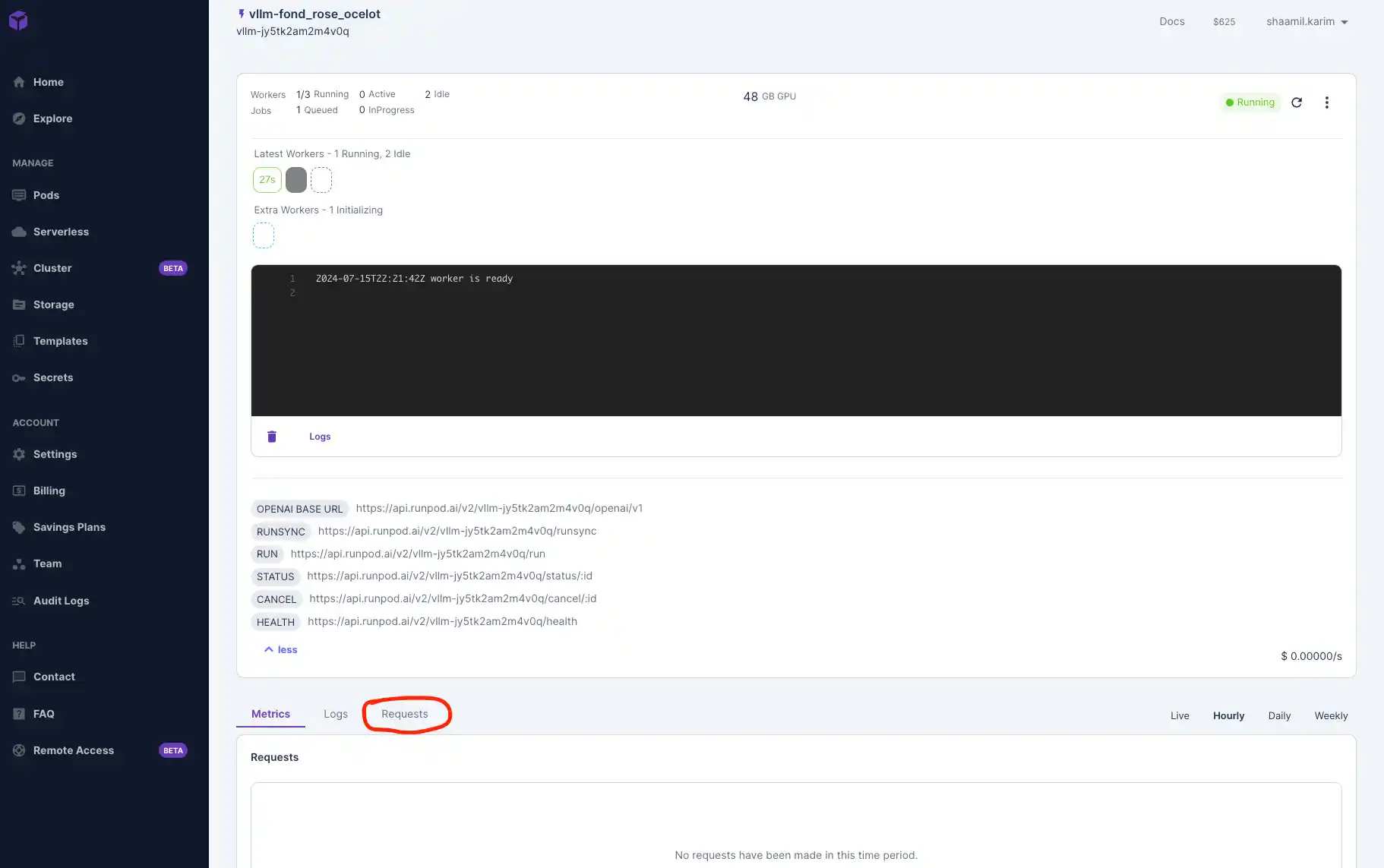
- Use the placeholder prompt or input a custom one and hit Run!
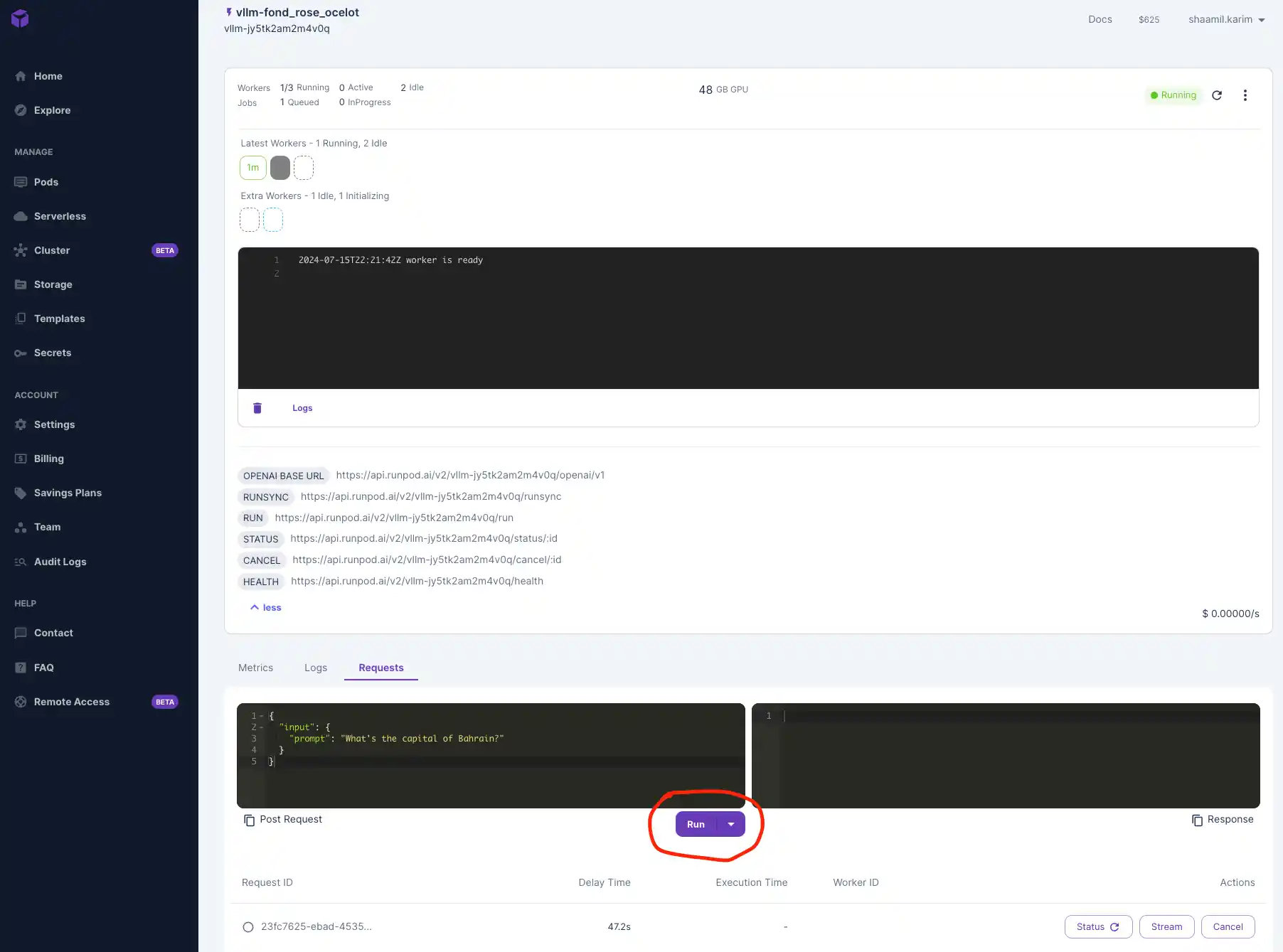
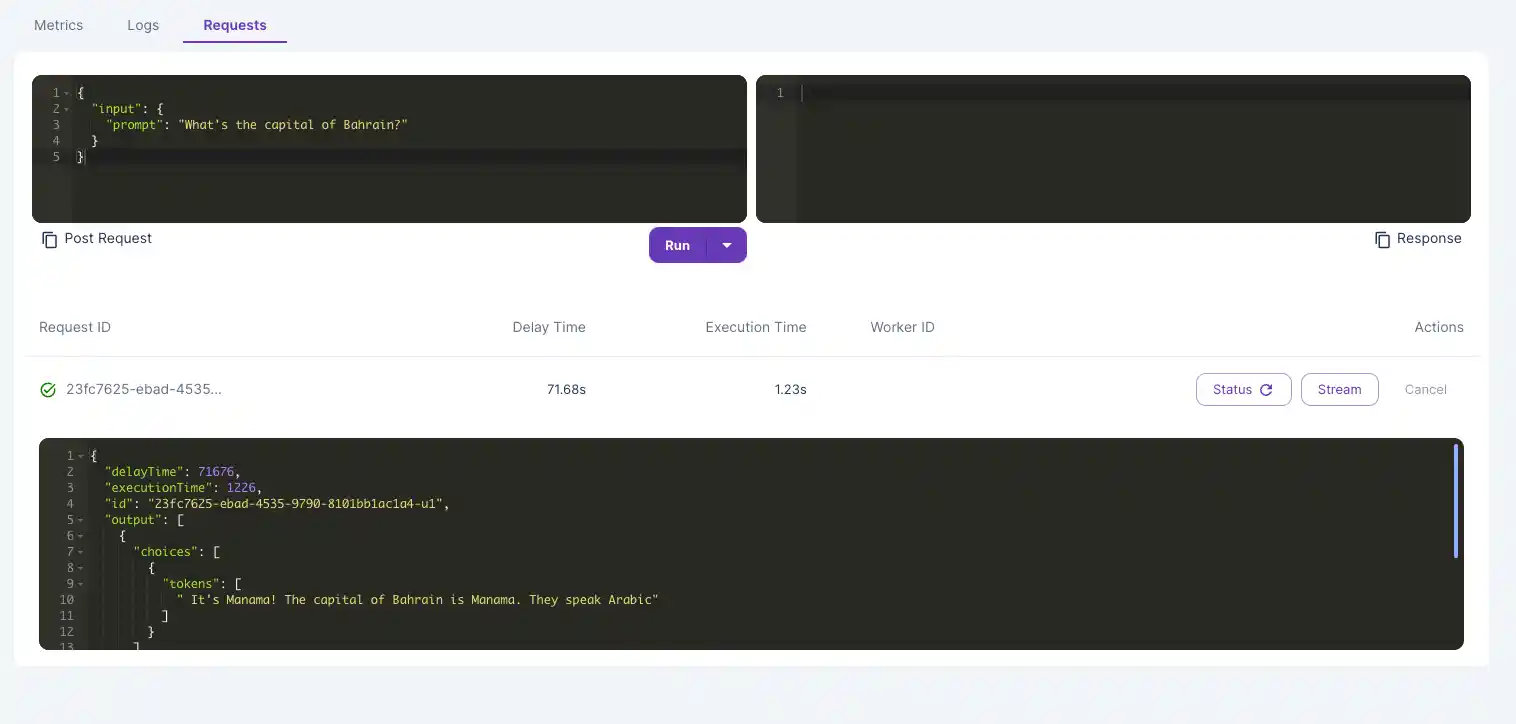
- After your model is done running, you’ll see your outputs below the Run button.
Connect to your serverless endpoint and test externally
We'll be using Google Colab to test out our model by connecting to the serverless endpoint. Colab which provides a free, cloud-based Jupyter notebook environment that we can leverage to interact with RunPod's serverless infrastructure, allowing us to easily send requests, manage deployments, and analyze results without the need for local setup or resource constraints.
The vLLM Worker is compatible with OpenAI's API, so we will interact with our vLLM Worker as you would with OpenAI's API. We'll also be using While Colab is a popular choice, you're not limited to it – you can also use other development environments like Visual Studio Code (VSCode) with appropriate extensions, or any IDE that can make HTTP requests.
- Go to colab.google and click on New Notebook. You'll see the page below.
- Run the following pip install command to install the OpenAI libraries needed to chat with our model.
pip install openai
- Once installed, paste the following code and add your api_key and base_url. Follow along to see how get your API key and Base URL. Follow along to find out where to get your API key and Base URL.
import os
from openai import OpenAI
# Set the API key
api_key = "YOUR API KEY HERE"
# Initialize the OpenAI client
client = OpenAI(
api_key="YOUR API KEY HERE",
base_url="YOUR BASE URL HERE",
)
messages = [{"role": "assistant", "content": "Hello, I'm your assistant. How can I help you today?"}]
while True:
# Display the chat history
for message in messages:
print(f"{message['role'].capitalize()}: {message['content']}")
# Get user input
prompt = input("User: ")
messages.append({"role": "user", "content": prompt})
# Get assistant's response
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct",
messages=messages,
temperature=0.7,
top_p=0.8,
max_tokens=100,
).choices[0].message.content
# Add the assistant's response to the conversation
messages.append({"role": "assistant", "content": response})
- Get your API key by navigating to Settings in your RunPod console.
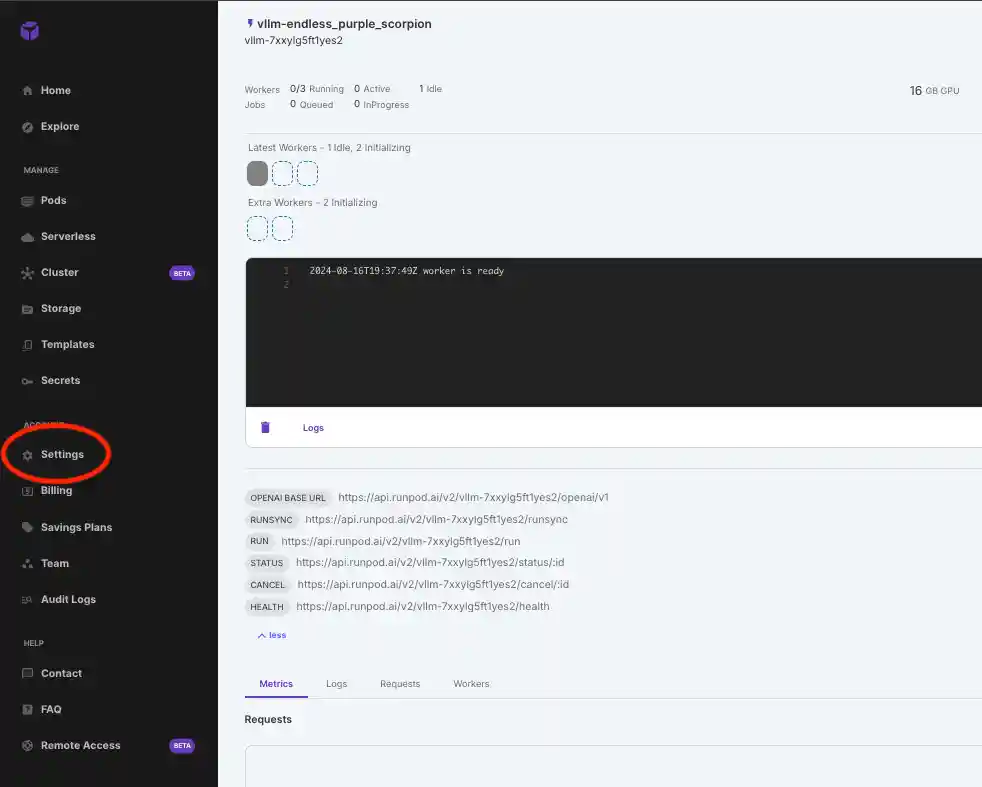
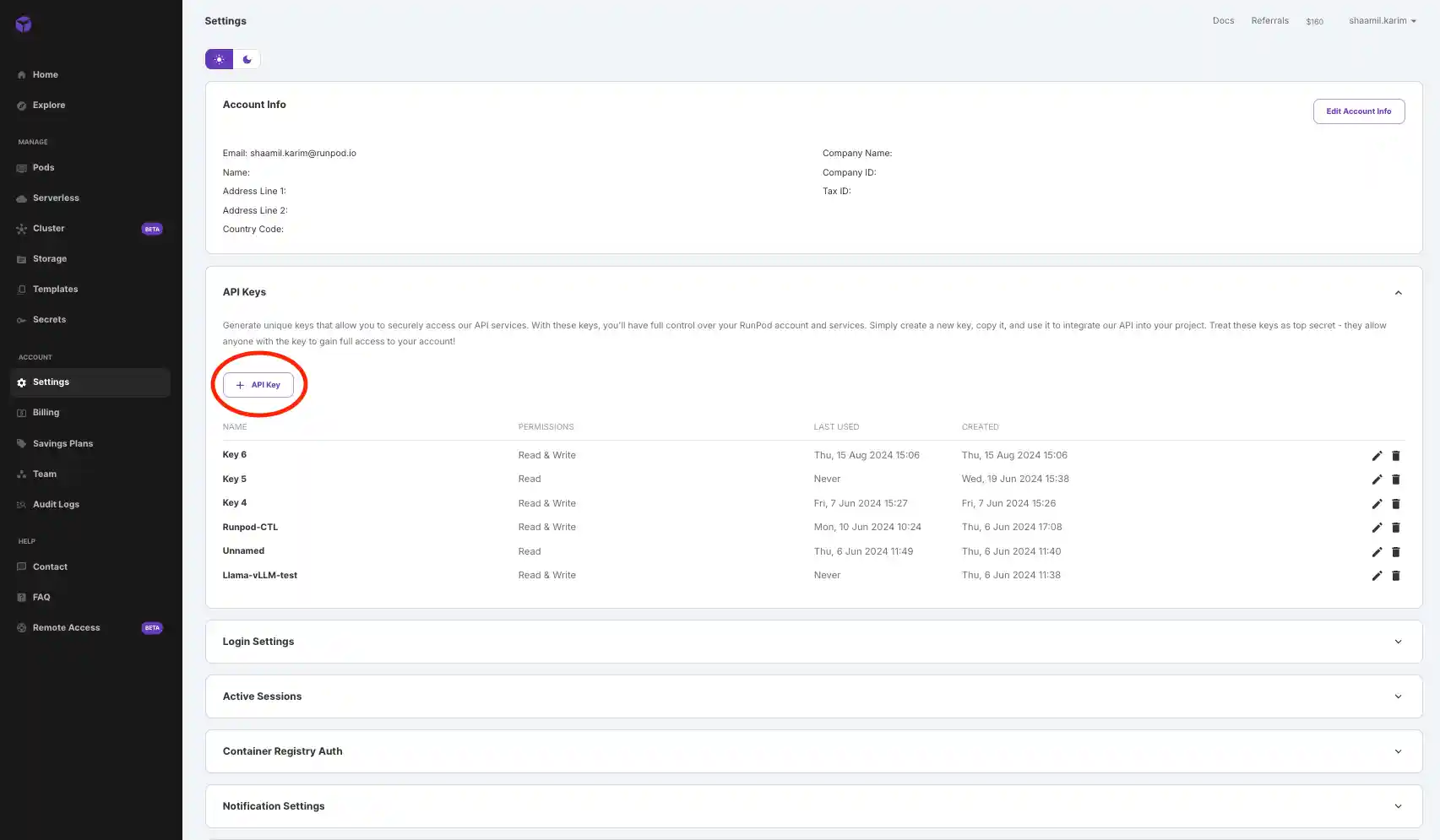
5. Click on API Keys and create your API key. Read permissions should be enough for this use case. Copy your API key and now paste it in the code.
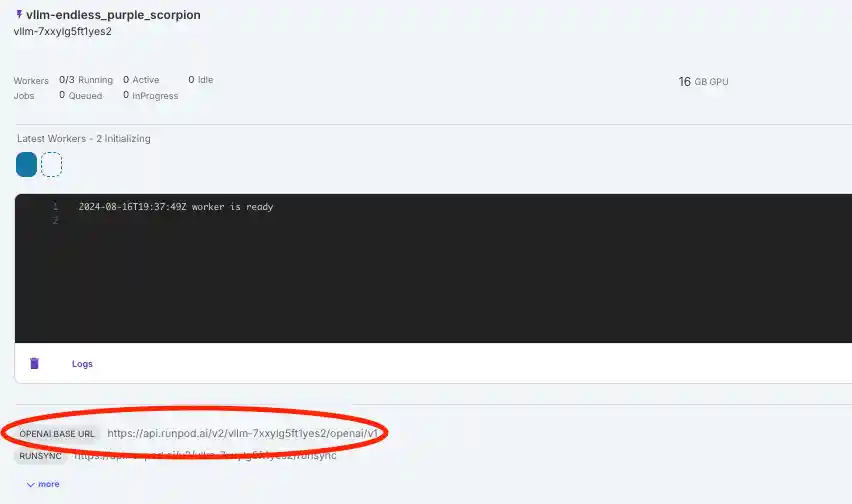
- Get your Base URL from below the logs on your Serverless endpoint page and paste it in the above code.
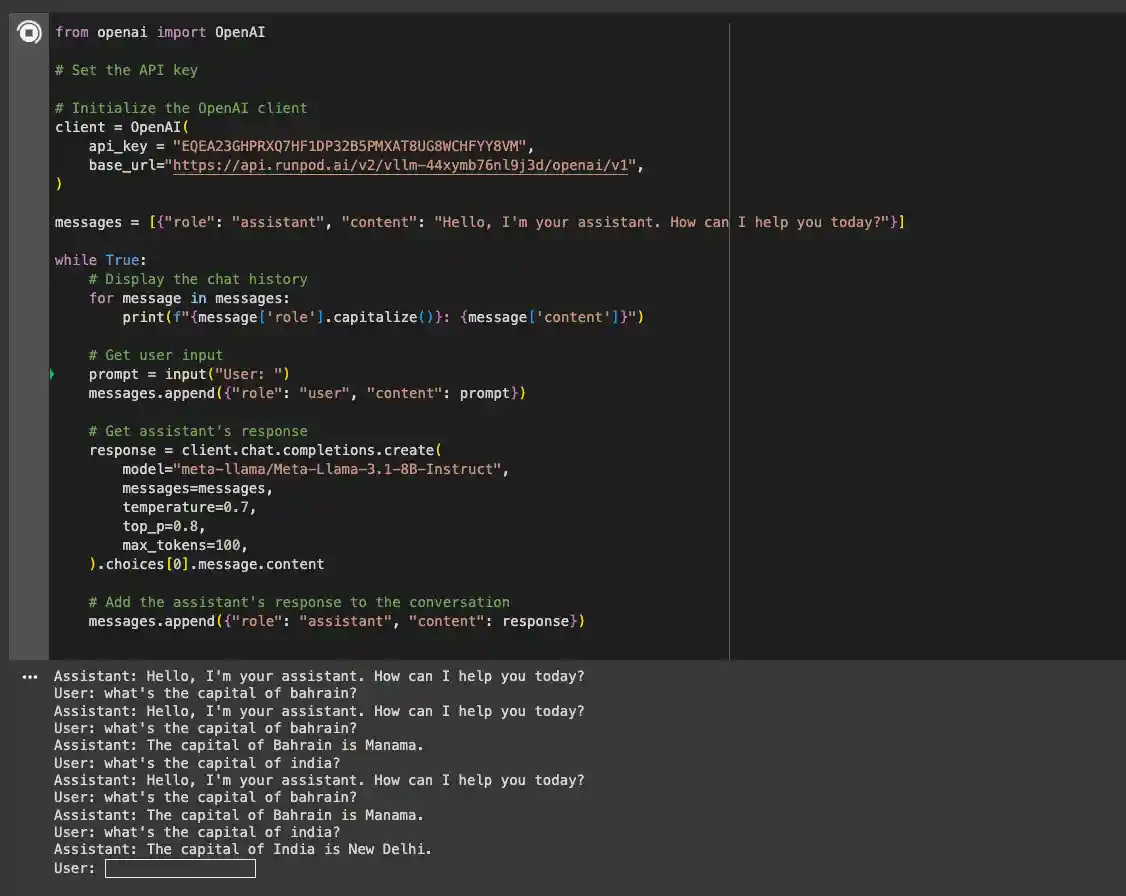
After running the above code, you should be able to chat with your model like below! The code below has its own API key and Base URL which have been deprecated now (obviously). Your first new token will take a few minutes to output but will run smoothly for every other token or request afterwards.
Troubleshooting
When sending a request to your LLM for the first time, your endpoint needs to download the model and load the weights. If the output status remains "in queue" for more than 5-10 minutes, read below!
- If you get a 500 error code, try increasing the VRAM size for your GPU.
- If your model is gated (ex. Llama), first make sure you have access, then paste your access token from your hugging face profile settings when creating your endpoint.
Comment below for more help!
Conclusion
In this blog, we've delved into the exciting capabilities of Llama 3.1, with a particular focus on its efficient 8B instruct version. We've explored the benefits of this model, highlighting its balance of performance and efficiency that makes it ideal for a wide range of applications. We've also discussed why vLLM is the perfect companion for running Llama 3.1, offering unparalleled speed and extensive model support.
By combining the power of the Meta Llama 3.1 8B instruct with the efficiency of vLLM on RunPod's serverless infrastructure, you're now equipped to leverage state-of-the-art language modeling capabilities for your projects. This powerful combination offers an excellent balance of performance, cost-effectiveness, and user-friendliness.
Get started now with our quick deploy option!