Run Llama 3.1 405B with Ollama: A Step-by-Step Guide


Meta’s recent release of the Llama 3.1 405B model has made waves in the AI community. This groundbreaking open-source model not only matches but even surpasses the performance of leading closed-source models. With impressive scores on reasoning tasks (96.9 on ARC Challenge and 96.8 on GSM8K) and code generation (89.0 on the HumanEval benchmark), Llama 3.1 is a game-changer.
Follow this guide to lean how to deploy the model on RunPod using Ollama, a powerful and user-friendly platform for running LLMs. Plus, we’ll show you how to test it in a ChatGPT-like WebUI chat interface with just one Docker command.
Why Use Llama 3.1 405B?
Llama 3.1 is groundbreaking for three main reasons:
- Exceptional Performance: With 405 billion parameters, it outperforms most models, including GPT-4o, in crucial benchmarks like math and multilingual tasks.
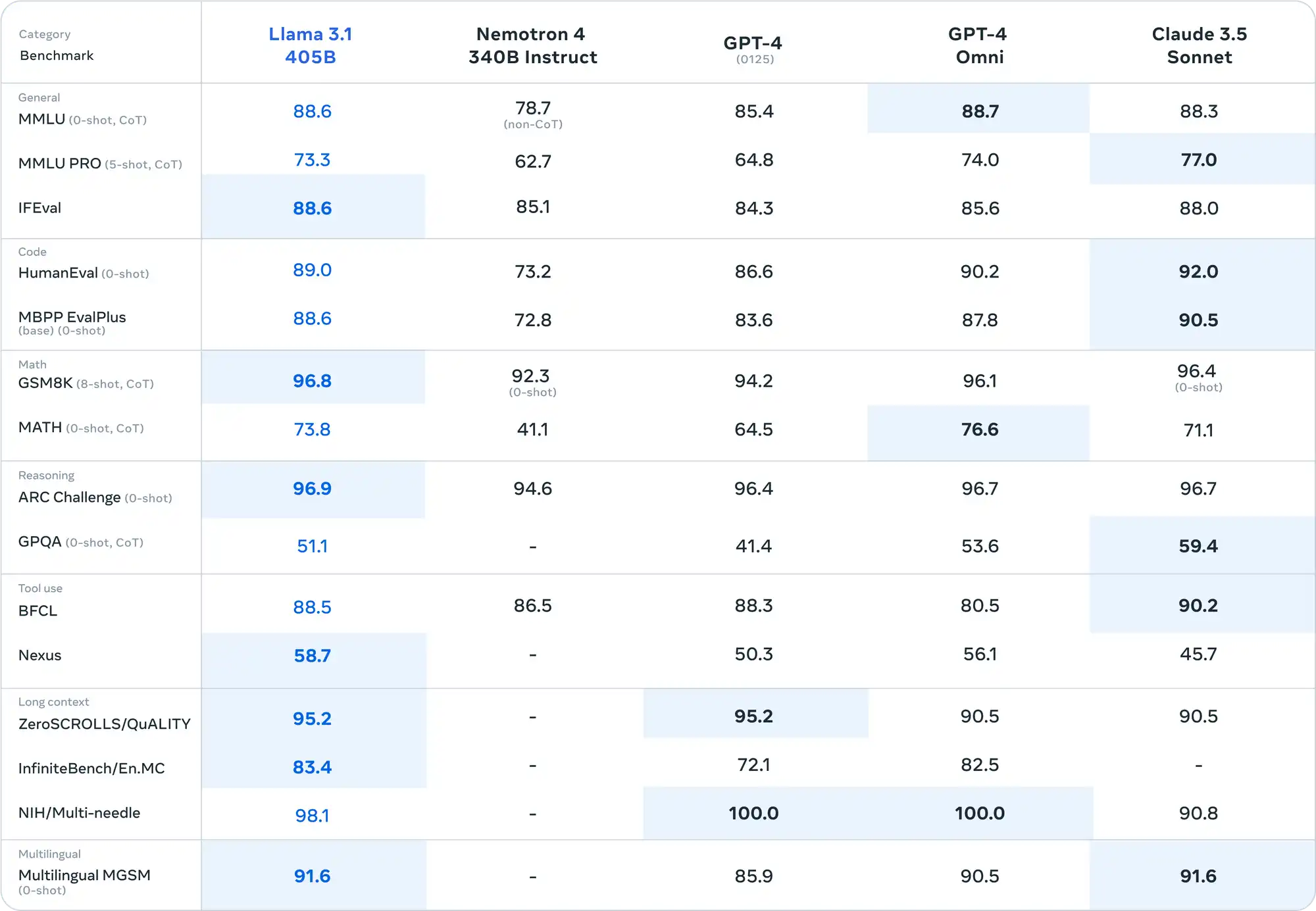
- Customizable: Offers an open-source alternative with top-tier capabilities, providing enhanced accessibility and customization for unique use cases.
- Cost-effective: Running your own model on services like RunPod can be much cheaper than many large closed-model APIs.
For more details on Llama 3.1, check out Meta’s blog.
Step-by-Step Guide to Deploy Llama 3.1 405B on RunPod
Prerequisites
1) Create your RunPod account and add at least $10 to rent your GPU.
2) Install docker.
1. Create and Configure your GPU Pod
1) Head to Pods and click Deploy.
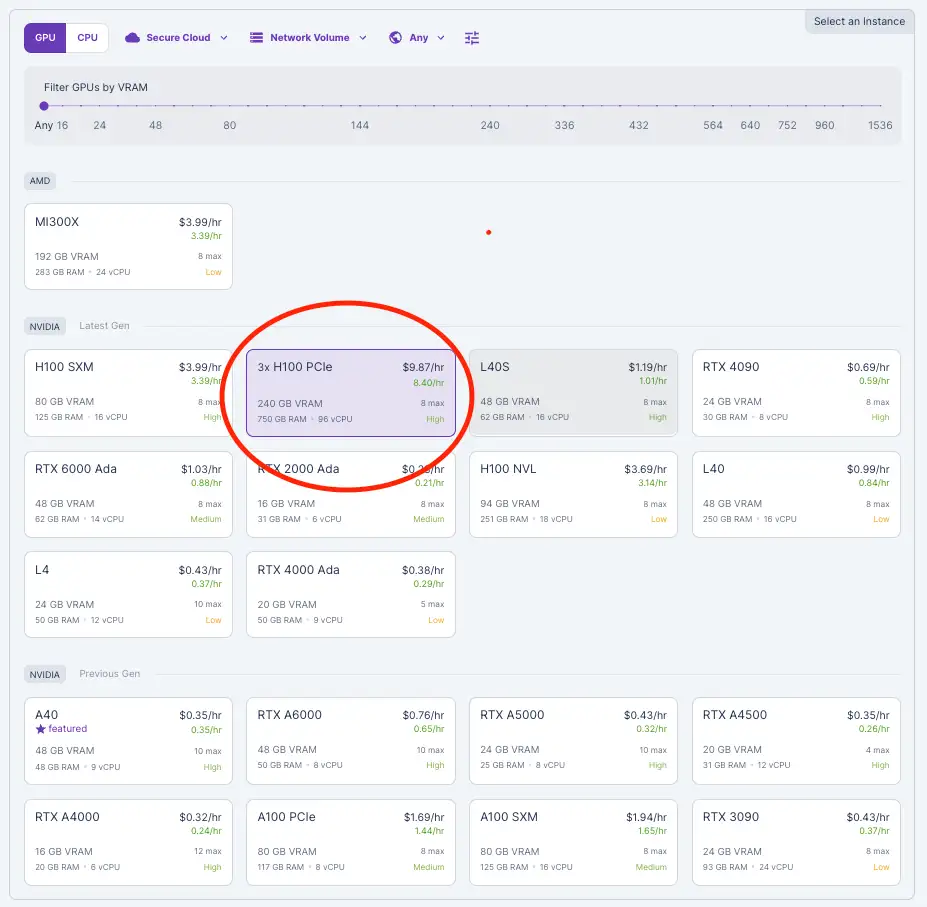
2) Select H100 PCIe and choose 3 GPUs to provide 240GB of VRAM (80GB each). The Llama 3.1 405B model is 4-bit quantized, so we need at least 240GB in VRAM. For more details, check our blog on picking the right VRAM.
3) Slide the GPU count to 3.
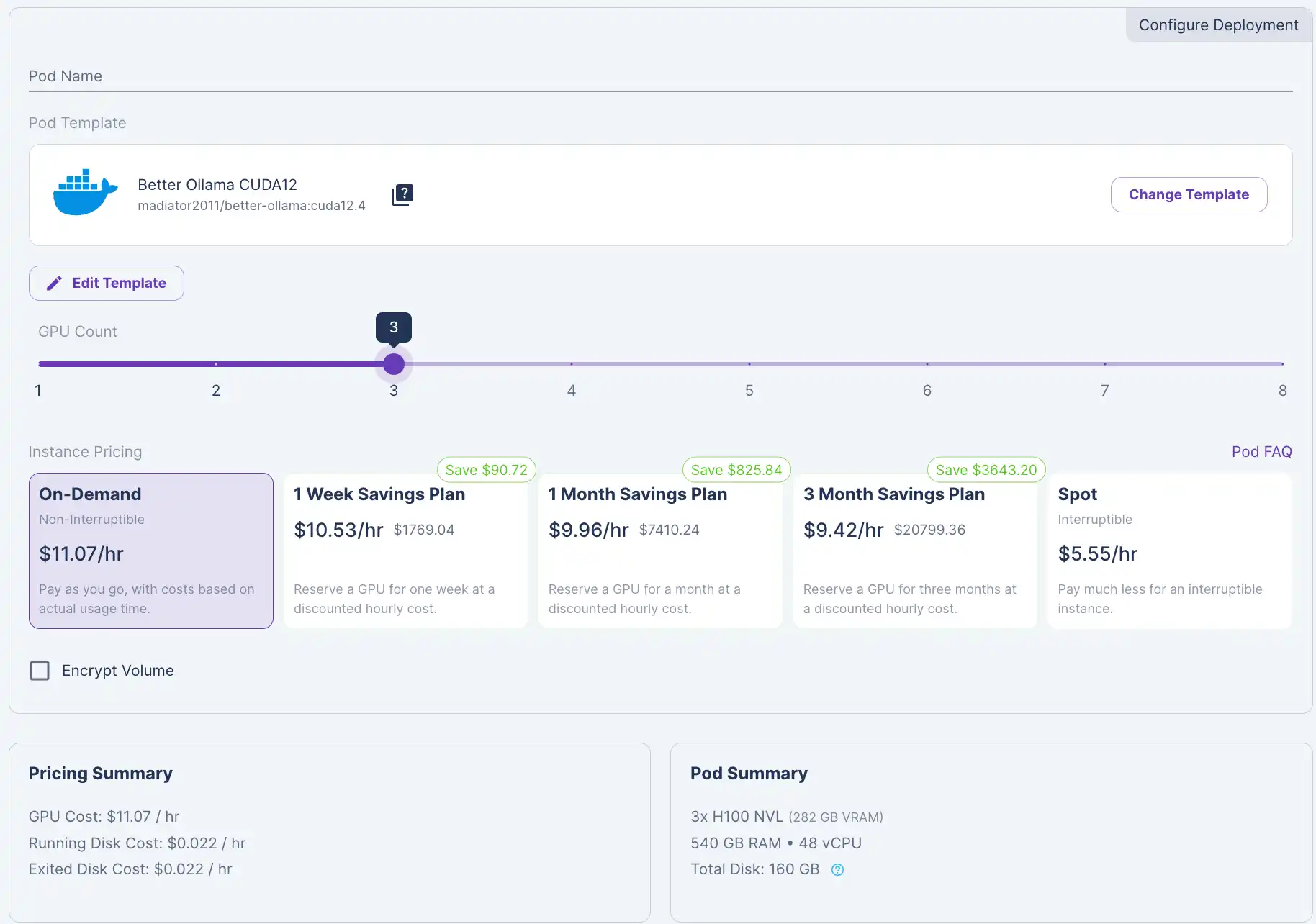
4) Click Change Template to "Better Ollama CUDA 12".
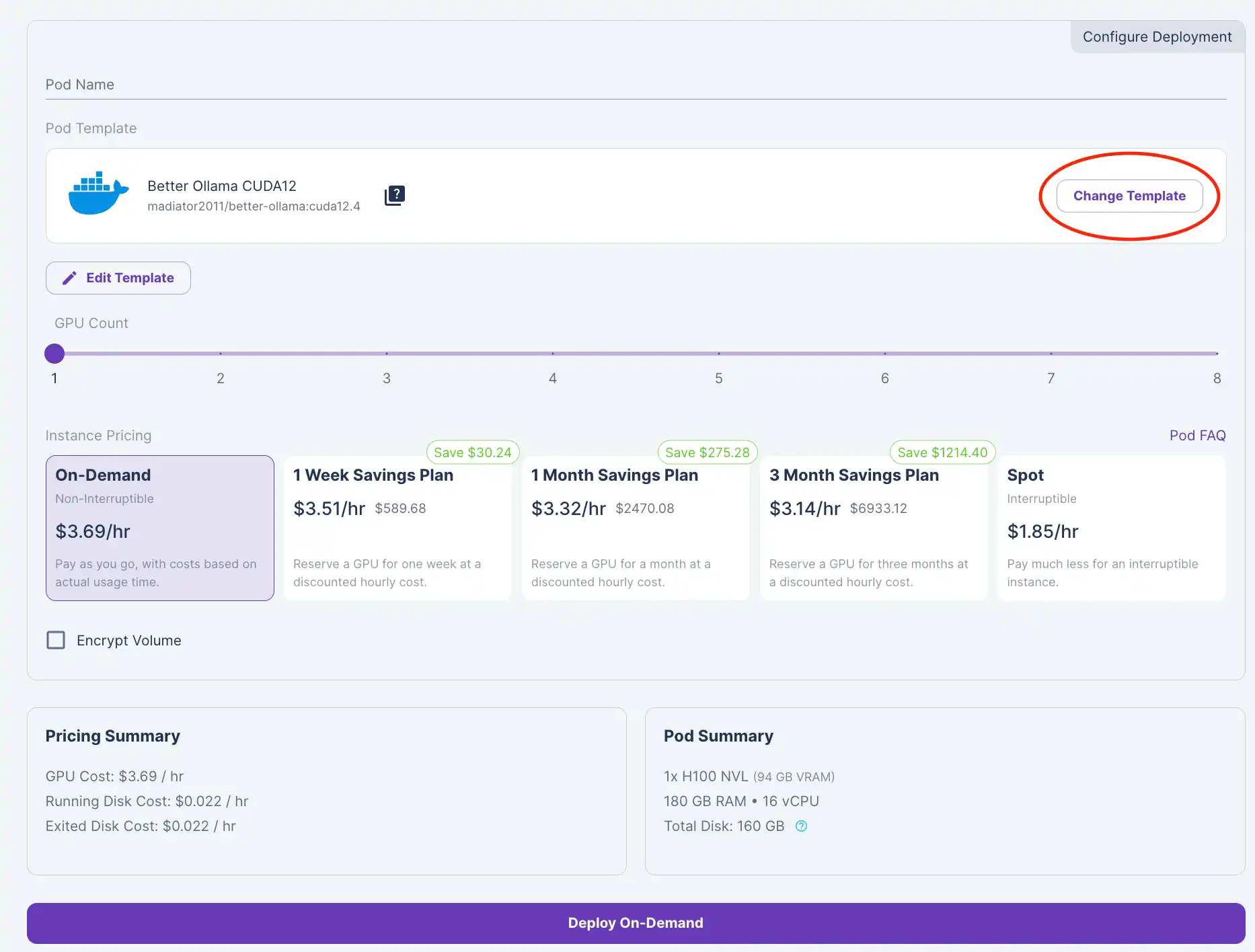
5) Click Edit Template and edit the Container Disk and set it to 250 GB to account for storing the model.
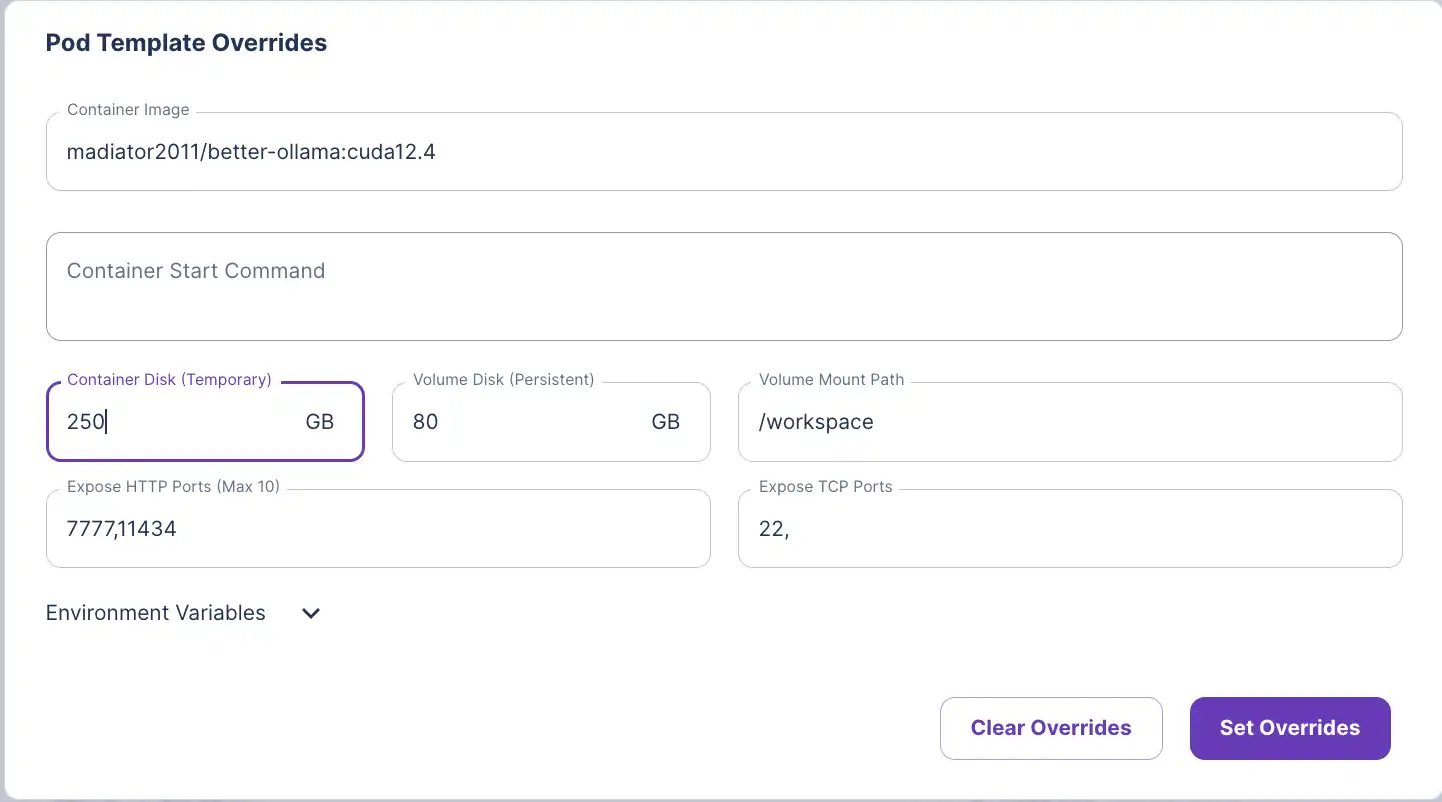
6) Click Set Overrides and Deploy.
7) Find your pod and click Connect.
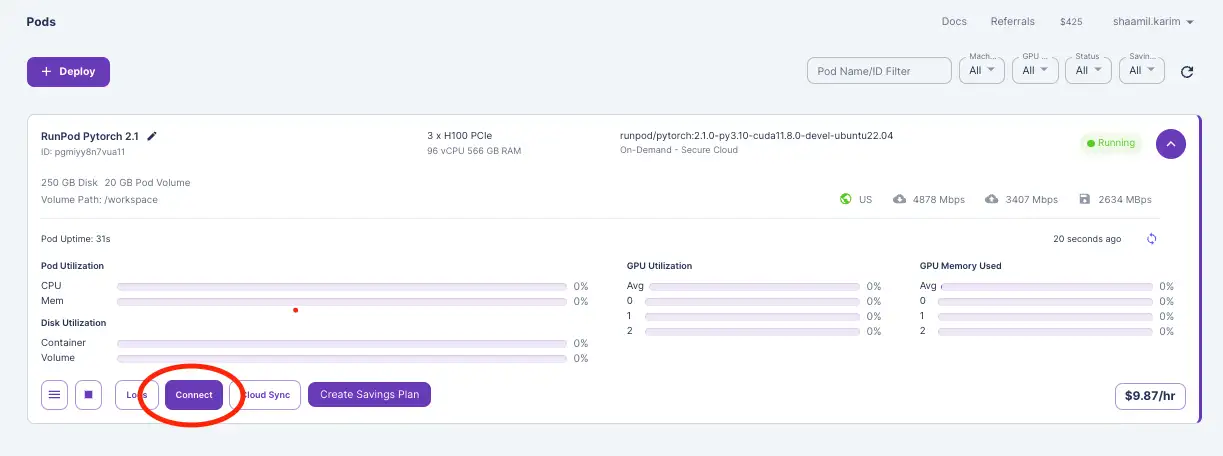
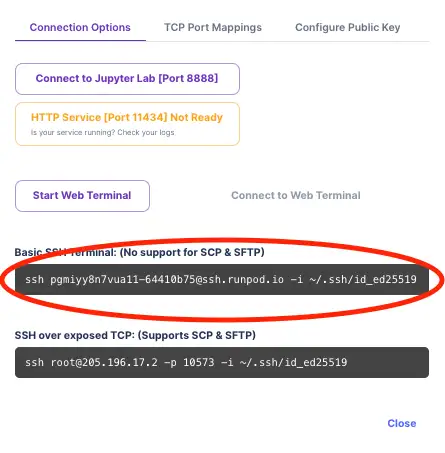
8) Copy your SSH command.
2. Download Ollama and Llama 3.1 405B
1) Open your terminal and run the SSH command copied above.
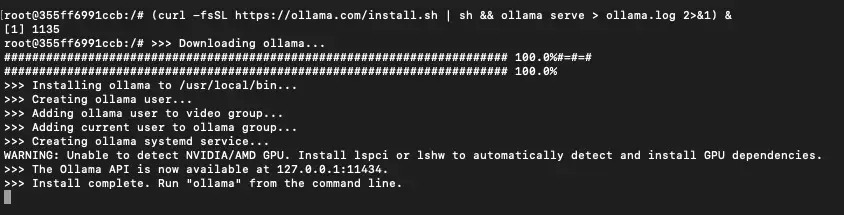
2) Once you’re connected via SSH, run this command in your terminal:
(curl -fsSL <https://ollama.com/install.sh> | sh && ollama serve > ollama.log 2>&1) &
This command fetches the Ollama installation script and executes it, setting up Ollama on your Pod. The ollama serve code starts the Ollama server and initializes it for serving AI models.
3) Download the Llama 3.1 405B model (head up, it may take a while):
ollama run llama3.1:405b
Start chatting with your model from the terminal. Let’s make it more interactive with a WebUI.
3. Running Llama 3.1 405B with Open WebUI’s chat interface
1) Open a new terminal window.
2) Run the following command, replacing {POD-ID} with your pod ID:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://{POD-ID}-11434.proxy.runpod.net/ -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
example:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=:<https://pgmiyy8n7vua11-11434.proxy.runpod.net> -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
3) Once the above is done, go to http://localhost:3000/ and sign up for Open WebUI.
4) Click Select a model and choose the model we downloaded.
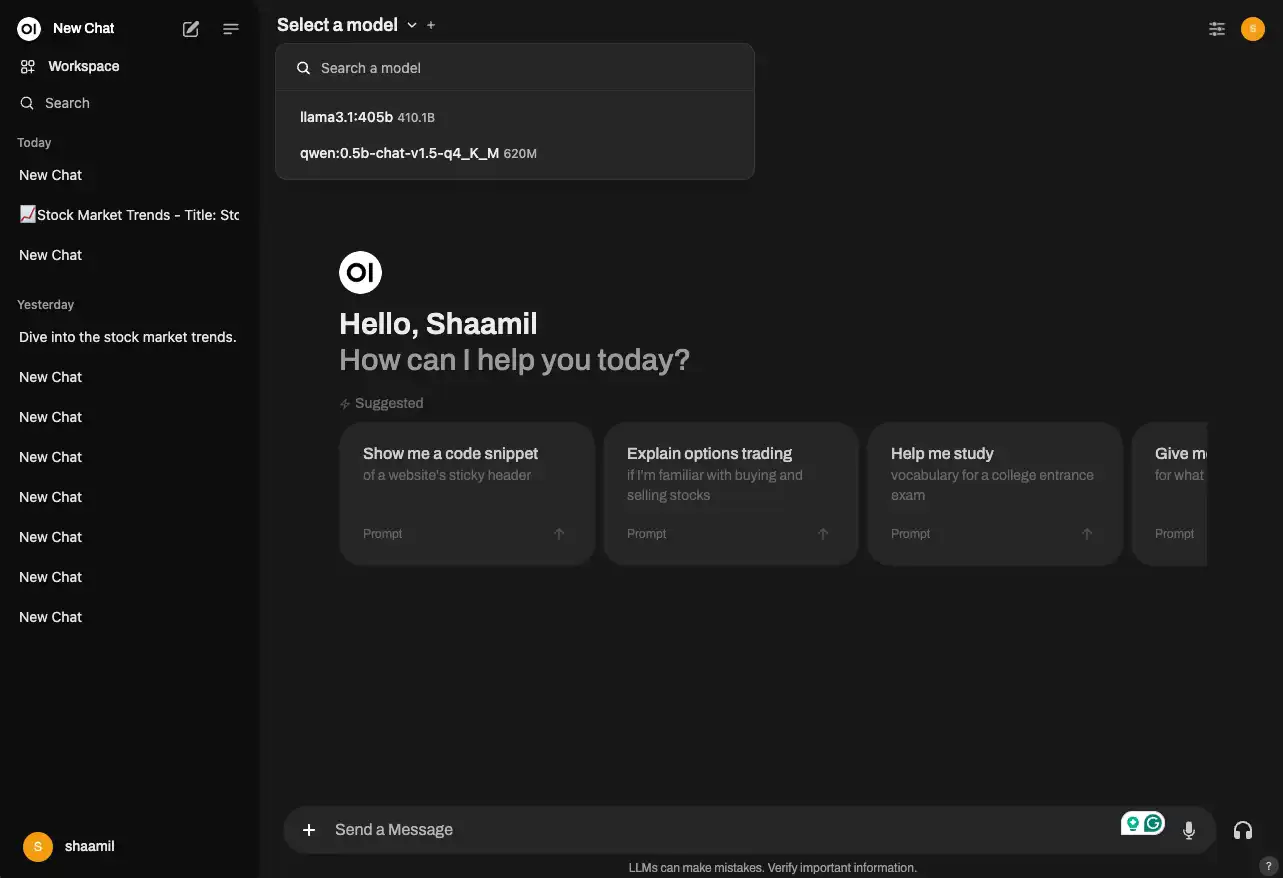
Done! You now have a chat interface to chat with your Llama 405b model using Ollama on RunPod.
Troubleshooting
- If the docker command doesn’t run, make sure the desktop app is up and running. You can also track your docker container and the logs from the Containers list.
- If you’re having issues with the Open WebUI interface, make sure you can chat with the model through the terminal like in Step 2.3 to isolate the issue. Check out Open WebUI’s docs for more help or leave a comment on this blog.
If you’re still facing issues, comment below on this blog for help, or follow Runpod’s docs or Open WebUI’s docs.
Conclusion
To recap, you first get your Pod configured on RunPod, SSH into your server through your terminal, download Ollama and run the Llama 3.1 405b model through the SSH terminal, and run your docker command to start the chat interface on a separate terminal tab.
You now have a taste for the speed and power of running the Llama 3.1 405B model with Ollama on RunPod. By leveraging RunPod’s scalable GPU resources and Ollama’s efficient deployment tools, you can harness the full potential of this cutting-edge model for your projects. Whether you are fine-tuning, conducting research, or developing applications, this setup provides the performance and accessibility needed to push the boundaries of what is possible with AI. Check out our blog on Fine-tuning vs RAG to decide the right option to customize your setup.
Sign up for our RunPod blog for more tutorials and informational content on cutting-edge developments in AI. Add a comment on what you’d like to see next in our blogs!