RTX 5090 LLM Benchmarks for AI: Is It the Best GPU for ML?


The AI landscape demands ever-increasing performance for demanding workloads, especially for large language model (LLM) inference. Today, we're excited to showcase how the NVIDIA RTX 5090 is reshaping what's possible in AI compute with breakthrough performance that outpaces even specialized data center hardware.
Benchmark Showdown: RTX 5090 vs. Professional & Data Center GPUs
We recently conducted comprehensive benchmarks comparing the consumer-grade RTX 5090 against both the professional RTX 6000 Ada Generation and the data center-focused NVIDIA A100 80GB PCIe. The results were nothing short of remarkable. We tested Qwen2.5-Coder-7B-Instruct in this benchmark.
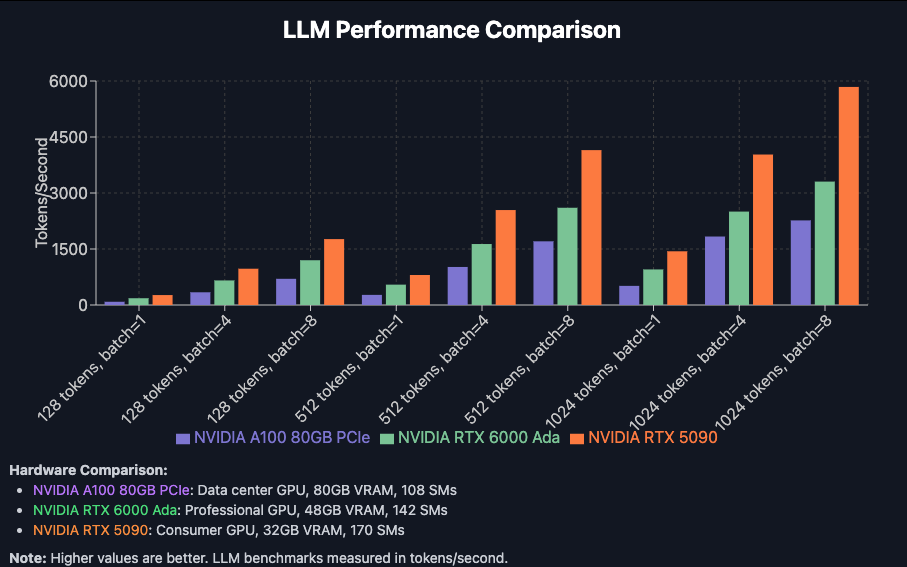
Our testing revealed that despite having less VRAM than both the A100 (80GB) and RTX 6000 Ada (48GB), the RTX 5090 with its 32GB of memory consistently delivered superior performance across all token lengths and batch sizes. At 1024 tokens with batch size 8, the RTX 5090 achieved a staggering 5,841 tokens/second – outperforming the A100 by 2.6x. This pattern held consistent across other configurations as well, with the consumer GPU consistently processing tokens faster than its more expensive counterparts.
To put the pricing in perspective, the 5090 costs $0.89/hr in Secure Cloud, compared to the $0.77/hr for the RTX 6000 Ada, and $1.64/hr for the A100. But aside from the standpoint of VRAM (the 5090 has the least, at 32GB) it handily outperforms both of them. If you are serving a model on an A100 though you could simply rent a 2x 5090 pod for about the same price and likely get double the token throughput - so for LLMs, at least, it appears there is a new sheriff in town.
I had trouble believing the results because someone else on my team had run his own benchmarks and gotten similar numbers - and I knew he knew his stuff, yet the numbers seemed totally out of pocket. So I wrote my own benchmarking code to test which actually logged the token output, just to be sure it wasn't outputting garbage, and sure enough, it was all on the level.
If you'd like to review my process, I've put my quick and dirty benchmark code up for review on Github. But the pseudocode runs something like this:
LLM_BENCHMARK:
Initialize model and tokenizer for given model ID
For each sequence length configuration:
For each batch size configuration:
Create sample input text of appropriate length
Tokenize text and replicate for batch size
Run warm-up inference pass (not timed)
For each benchmark sample:
Record start time
Run model inference to generate output tokens
Record end time
Calculate tokens processed per second
Save generated text for verification
Calculate average performance metrics
Store results for this configuration
Return complete benchmark resultsWhat Makes the RTX 5090 an LLM Powerhouse?
The RTX 5090's exceptional performance stems from NVIDIA's latest Blackwell architecture, which brings significant improvements specifically designed for AI workloads. With 170 Streaming Multiprocessors – compared to the RTX 6000 Ada's 142 and A100's 108 – the RTX 5090 enables more parallel processing power. While data center GPUs prioritize reliability and multi-tenancy features, the RTX 5090 channels its resources toward delivering maximum computational throughput, making it ideal for high-performance inference tasks.
The RTX 5090 truly shines when serving smaller models at scale. Our detailed testing with popular lightweight models reveals astonishing capabilities. The Qwen2-0.5B model delivers up to 65,000 tokens/second and 250+ requests/second with 1024 concurrent prompts, while Phi-3-mini-4k-instruct achieves 6,400 tokens/second at the same concurrency level. This represents an order of magnitude improvement over previous generation hardware for small model serving, making the RTX 5090 the ideal choice for high-throughput applications like chatbots, API endpoints, and real-time services. As stated, the only disadvantage is the lower VRAM - but you can just add additional GPUs as needed.
Real-World Applications
The exceptional performance of the RTX 5090 opens new possibilities across numerous AI applications. Customer service operations can now handle thousands of concurrent conversations with minimal latency. Content platforms can deliver generated text, summaries, and creative content at unprecedented scale. Data-intensive businesses can process and respond to information streams with AI-powered insights instantly. Companies running multiple specialized models can now consolidate them onto a single GPU, reducing complexity and costs. Remember that one of the most reliable indicators of customer dissatisfaction with a service is a slow response speed - and chatbots are by no mean immune to this.
Are RTX 5090s right for you?
At the heart of the RTX 5090's exceptional performance lies its impressive array of 170 Streaming Multiprocessors (SMs). These computational building blocks are the workhorses of GPU architecture, handling the parallel processing tasks crucial for AI workloads. Each SM contains thousands of CUDA cores, Tensor cores for accelerated AI operations, and shared memory that enables efficient data exchange. What makes the RTX 5090 truly revolutionary is not just the raw SM count, but the cost-efficiency it delivers. You can see the number of streaming modules you get per dollar per hour (Secure Cloud prices):
| GPU Model | SMs | Hourly Rate | SMs per Dollar/Hour |
|---|---|---|---|
| RTX 5090 | 170 | $0.89 | 191.0 |
| RTX 4090 | 128 | $0.69 | 185.5 |
| H200 | 132 | $3.99 | 33.1 |
| H100 | 132 | $2.99 | 44.1 |
| L40S | 142 | $0.86 | 165.1 |
| L40 | 142 | $0.99 | 143.4 |
| A40 | 84 | $0.44 | 190.9 |
| A100 PCIe | 108 | $1.64 | 65.9 |
While streaming modules are not the only measure of performance for a GPU, it goes to show how important it is when you need ludicrous numbers of tokens per second. So if you need high levels of throughput, it really does appear that the 5090 is the new state of the art for this specific purpose.
Questions? Feel free to pop into our Discord and ask away!