RAG vs. Fine-Tuning: Which Method is Best for Large Language Models (LLMs)?


Large Language Models (LLMs) have changed the way we interact with technology, powering everything from chatbots to content-generation tools. But these models often struggle with handling domain-specific prompts and new information that isn't included in their training data.
So, how can we make these powerful models more adaptable? Enter Retrieval-Augmented Generation (RAG) and fine-tuning. Both are valuable but operate very differently:
- RAG enhances an LLM's knowledge by fetching external information during inference, ensuring responses are current and contextually accurate.
- Fine-tuning involves retraining an existing LLM on a specific dataset, embedding specialized knowledge directly into the model.
Which one should you choose? Let’s dive in.
What is Retrieval-Augmented Generation (RAG)?
Definition and Explanation
Think of Retrieval-Augmented Generation (RAG) like an open-book test. Instead of memorizing everything, the model retrieves relevant information from external sources during inference to generate a response.
Example of RAG in Action
Imagine you’re chatting with a customer service bot about a new product you just bought. You ask, "How do I set up my new smart speaker?"
Here’s how RAG handles it:
- Question or Prompt: You start with a question. In this case, "How do I set up my new smart speaker?"
- Retrieval Mechanism: The model searches through a database or set of documents to find the most relevant information. It might look through the product manual, setup guides, or FAQs.
- Combine and Generate: The model uses the retrieved information along with its pre-trained knowledge to generate a response. It might say, "To set up your smart speaker, plug it into a power source, download the companion app, and follow the on-screen instructions."
With RAG, the chatbot doesn’t need to have all the specific setup details memorized. Instead, it pulls in the latest and most relevant information to give you an accurate and helpful response. This process is like an open-book test—minimal prep but longer response times compared to pre-trained knowledge.
What is Fine-Tuning?
Definition and Explanation
Fine-tuning is like preparing for a closed-book test. You start with a pre-trained model that has a broad understanding, and then you give it extra, specialized training so it becomes an expert in a specific area.
Example of Fine-Tuning in Action
Let’s say you’re building a chatbot for a healthcare app that needs to answer questions about medical conditions. You start with a pre-trained language model that’s good at general language understanding, but you want it to be an expert in healthcare.
Here’s how fine-tuning handles it:
- Start with a Pre-trained Model: You begin with a model that already knows a lot about language in general, ex: Llama 70B.
- Select Your Specific Dataset: You gather a bunch of medical texts, like doctor’s notes, medical journals, and health guides.
- Further Training: You train the model on this specific dataset. The model learns to recognize and understand medical terminology and the context in which it’s used.
Now, when someone asks the chatbot, "What are the symptoms of the flu?", the fine-tuned model responds with detailed, accurate information: "Common symptoms of the flu include fever, chills, muscle aches, cough, congestion, runny nose, headaches, and fatigue."
By fine-tuning the model with specific medical texts, it becomes really good at answering healthcare-related questions. It’s like going from a generalist to a specialist.
Different Types of Fine-Tuning
Fine-tuning isn’t a one-size-fits-all approach. Depending on your needs, you can choose different methods to refine your model. Each technique has its own strengths and use cases, making it important to pick the right one for your specific goals. Here’s a quick overview of the main types of fine-tuning you might encounter:
- Supervised Fine-Tuning (SFT): This method uses labeled input-output pairs to teach the model how to perform specific tasks. For example, if you want your model to respond to customer service inquiries, you’d provide it with examples of questions and the correct answers.
- Reinforcement Learning (RL): Think of this as a trial-and-error approach. The model learns by receiving feedback on its actions, which helps it improve over time. A well-known example is Reinforcement Learning from Human Feedback (RLHF), where the model is trained based on human evaluations of its responses.
- Unsupervised Fine-Tuning: This approach continues pre-training the model by predicting the next word or token in a sequence. It’s useful for instilling new knowledge into the model without needing labeled examples, like expanding the model’s general understanding of a new topic.
RAG vs. Fine-Tuning
Now that we understand RAG and fine-tuning, let’s compare them:
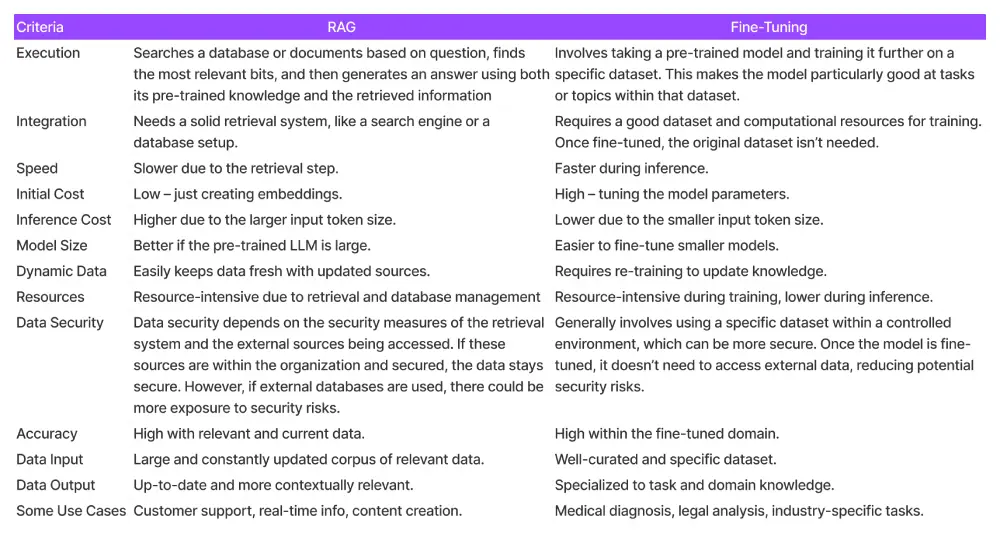
Choosing between RAG and fine-tuning depends on what you need. RAG is fantastic for tasks that require up-to-date information, keeping responses current and relevant. On the other hand, fine-tuning works well for specialized applications, making your model an expert in specific areas.
RAG Example Use Cases
- Customer Support: A chatbot that retrieves the latest policy changes or product details to provide accurate answers.
- Research: A system that pulls recent studies and data to provide a comprehensive overview of a topic.
- Personal Assistant: Chatbots gathering up-to-date information to ensure accuracy and timeliness.
Fine-Tuning Example Use Cases
- Domain-Specific Tasks: For example, a healthcare provider fine-tuning a model on medical records to assist in diagnosing diseases.
- NSFW Content Detection: Fine-tuning a model on NSFW datasets to better detect and classify inappropriate content.
- Customized Tone of Voice: Fine-tuning a model to output texts like Shakespeare or craft legal arguments like a lawyer.
RAG vs. Fine-Tuning Accuracy On Domain-Specific Knowledge
A paper published by Microsoft Research in January 2024 compared the performance of RAG, fine-tuning, and fine-tuning used in conjunction with RAG on the Massively Multilingual Language Understanding Evaluation (MMLU) benchmark. They looked at how accurate LLMs were in domains like anatomy, astronomy, college biology, college chemistry, and prehistory.
Here’s a quick look at how these methods stack up for informational accuracy:
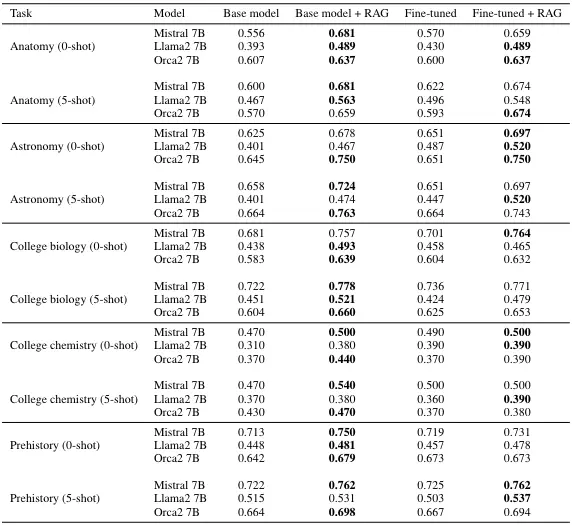
- RAG Performance: RAG always improves the base model’s accuracy. For example, in College Biology (0-shot), RAG significantly boosted accuracy compared to the base model.
- Fine-tuning Performance: Fine-tuning almost always infers more accurately than the base model. However, RAG generally outperforms fine-tuning. Fine-tuning only beats RAG in two instances, and even then, only by a slim margin.
- Combining fine-tuning and RAG: Sometimes, combining fine-tuning with RAG gives better results than using RAG alone. However, RAG still outperforms this combination in about 75% of cases.
While this study shows RAG often outperforms on informational accuracy, this is only one of many use cases. Fine-tuning could perform better than RAG at other tasks like sentiment analysis, NSFW content detection, and tone of voice curation.
RAFT: Using Fine-Tuning to Improve RAG
So far, we’ve explored RAG, fine-tuning, and even using RAG with fine-tuning to enhance language models. Each method has its own strengths, but what if we could combine them in a more integrated way?
A recent paper from a team at Berkeley introduces RAFT (Retrieval-Augmented Fine-Tuning), a novel approach that fine-tunes a model specifically to improve the retrieval and generative process of RAG. This creates a more powerful and adaptable language model, taking the best of both worlds to new heights.
What is RAFT?
RAFT, which stands for Retrieval-Augmented Fine-Tuning, is a novel approach developed by a research team at UC Berkeley to enhance the performance of large language models (LLMs) in domain-specific tasks. This method combines the strengths of Retrieval-Augmented Generation (RAG) and fine-tuning to create a more effective training strategy for LLMs.
How RAFT Works
The RAFT method involves preparing the training data in a way that mimics an "open-book" setting. Here's a simplified breakdown of the process:
- Question and Documents: Each training data point includes a question, a set of documents (both relevant and irrelevant), and a detailed answer derived from the relevant documents.
- Oracle and Distractor Documents: Documents are categorized as 'oracle' (relevant) and 'distractor' (irrelevant). The model is trained to generate answers by referencing the oracle documents while ignoring the distractors.
- Chain-of-Thought Reasoning: The model is encouraged to explain its answers in a detailed, step-by-step manner, which helps improve its reasoning capabilities.
Key Benefits
- Improved Accuracy: RAFT enhances the model's ability to reason and generate accurate answers by citing specific parts of the documents.
- Domain-Specific Adaptation: It is particularly effective for domain-specific tasks, improving performance across datasets like PubMed, HotpotQA, and Gorilla.
- Self-Critique: The approach includes mechanisms for the model to critique its own answers, promoting continuous learning and accuracy.
Differences between RAFT and Using RAG vs. Fine-Tuning Separately
- Integrated Training: Instead of training retrieval and generation independently, RAFT trains them together. This means that the model will get better at finding relevant documents for certain query prompt while plainly fine-tuning would only improve the generative part of this process.
- Combined Loss Function: RAFT uses a combined loss function that incorporates both retrieval and generation losses. This helps the model learn to retrieve documents that are most beneficial for generating accurate answers
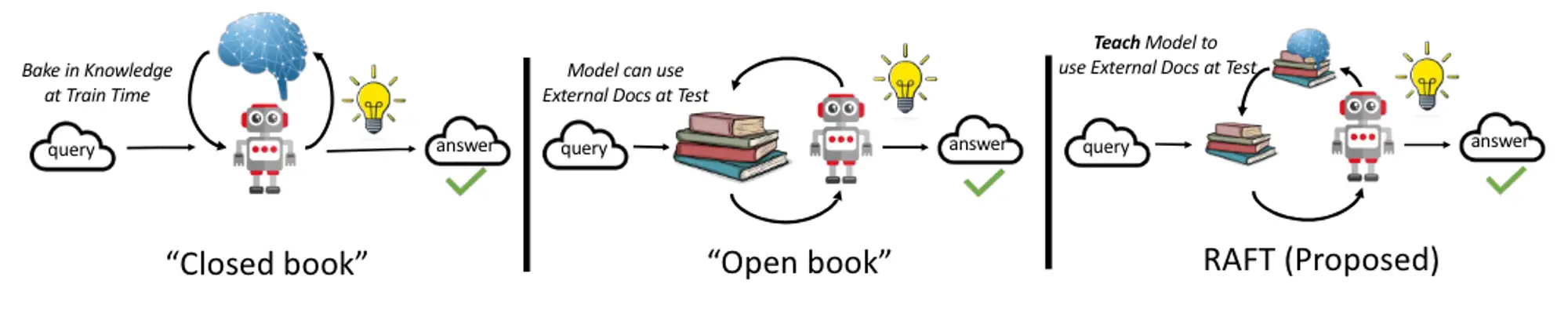
We can use our open-book and closed-book analogy to imagine what the combination of the two would look like below:
Research and Results
The RAFT approach has shown significant improvements over traditional fine-tuning and RAG methods, making it a promising technique for future LLM applications.
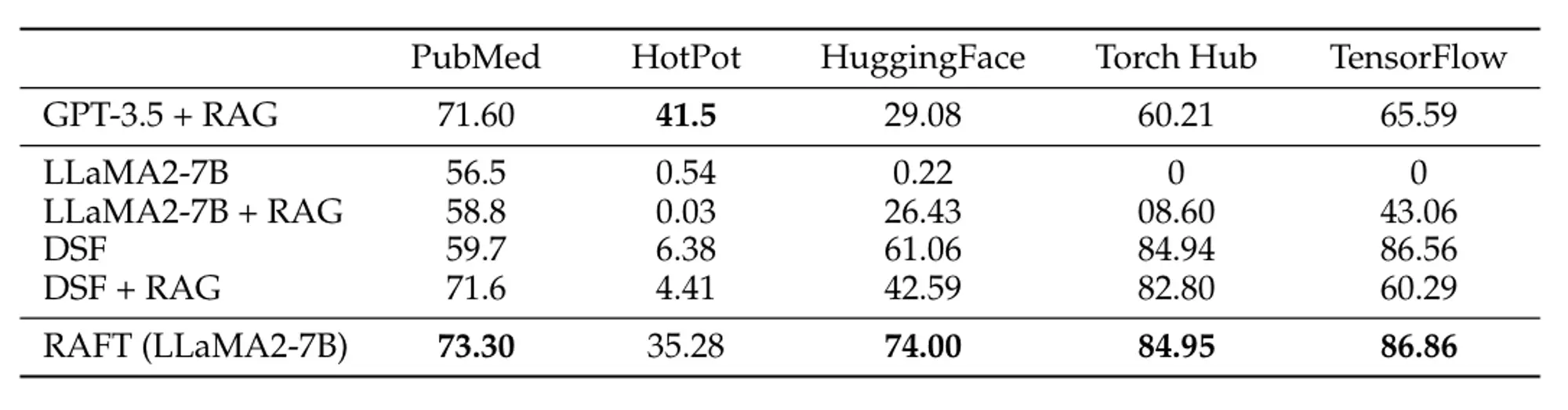
The paper’s results found that RAFT improves performance for all specialized domains across PubMed, HotPot, HuggingFace, Torch Hub, and Tensorflow Hub. We see comparison of their model, RAFT-7B (Fine-tuned Llama-7B) with LLaMA, with RAG on Llama and also GPT-3.5 below:
Conclusion – Which Should You Choose?
As we’ve explored, RAG, fine-tuning, and RAFT each bring unique strengths to the table for enhancing large language models. RAG excels in retrieving up-to-date information, making it ideal for tasks that require current and relevant data. Fine-tuning, on the other hand, allows models to specialize in specific domains, providing in-depth expertise and tailored responses.
RAFT, the innovative approach from UC Berkeley, combines the best aspects of both RAG and fine-tuning. By training models to integrate retrieval and generative processes, RAFT creates a more powerful and adaptable language model. This method improves accuracy, enhances reasoning, and adapts to domain-specific needs effectively.
In choosing the right method, consider your specific requirements. If you need up-to-date information, RAG is your go-to. For specialized applications, fine-tuning is the way to go. And if you’re looking for a comprehensive approach that leverages the strengths of both, RAFT offers a promising solution.
Check out some videos made by Data Science Dojo and AI Anytime on fine-tuning and implementing it on Runpod. Also, look out for a blog from us soon about implementing RAG on Runpod!