Open Source Video and LLM: New Model Roundup


Remember when generating decent-looking videos with AI seemed like something only the big tech companies could pull off? Those days are officially over. 2024 brought us a wave of seriously impressive open-source video generation models that anyone can download and start playing with. And here's the kicker - many of these open models are going toe-to-toe with (and sometimes beating) the fancy proprietary options.
Here are the most exciting releases from the past year, and five models really stand out from the pack: Mochi 1 from Genmo, Hunyuan Video from Tencent, LTX-Video by Lightricks, Wan2.1 from Alibaba, and SkyReels V1 from Skywork AI. Each brings something unique to the table–whether you're after buttery-smooth motion, lightning-fast generation, or Hollywood-quality scenes with realistic humans.
The first quarter of 2025 has also witnessed a surge in open-source large language model releases, each pushing the boundaries of what's possible with increasingly modest hardware requirements. As a GPU cloud provider committed to democratizing access to cutting-edge AI, we're thrilled to see this trend of "more capability, less compute" gaining momentum. In just the past month, four groundbreaking models have emerged that deserve special attention: QwQ-32B, Gemma 3, Cohere Command A, and OLMo 2 32B. Each offers distinct advantages for different use cases while dramatically reducing the hardware threshold needed for state-of-the-art AI performance. Let's explore what makes these models special, their ideal applications, and how you can deploy them efficiently on our platform.
Open Source Video Generation
Mochi 1 by Genmo
Mochi was the first of the crop of open-source video models that began releasing in late 2024, and along with it has an open-sourced VAE (AsymmVAE.) AsymmVAE uses an asymmetric encoder-decoder structure designed specifically for video compression. The asymmetry in the name refers to the intentional imbalance between the encoder and decoder components. This asymmetric design is purposeful - by making the decoder more powerful than the encoder, the model can reconstruct high-quality video from highly compressed latent representations.
The AsymmVAE works in tandem with the AsymmDiT (Asymmetric Diffusion Transformer) architecture. This integration is key to Mochi 1's performance:
- The AsymmVAE compresses the video to a manageable size
- The AsymmDiT then performs diffusion operations in this compressed latent space
- This approach allows the model to reason over 44,520 video tokens simultaneously with full 3D attention
By working in the compressed space, the model can effectively process longer video sequences with available computational resources than would be possible when operating on raw video data. This becomes very important when you consider how VRAM and compute-hungry these models are.
Mochi-1 can generate 480p videos up to 5.4 seconds at 30 FPS (approx. 162 frames) with 720p on the way, and weighs in at 10b pGenmo has also released a method to train LoRAs. For a rundown on the model, check out our previous blog entry on Mochi, or use our GitHub integration to deploy a Mochi worker in serverless.
HunyuanVideo by Tencent
Hunyuan Video represents a significant advancement in open-source video generation, positioning itself as a powerful competitor to leading closed-source models, weighing in at 13 billion parameters. This model produces cinematic-quality videos with strong physical accuracy and scene consistency, and specializes in continuous, complex motions and sequential actions within a single prompt.
According to human evaluations, Hunyuan Video outperformed several closed-source models including Luma 1.6 and leading Chinese video generation models across text alignment, motion quality, and visual quality metrics.
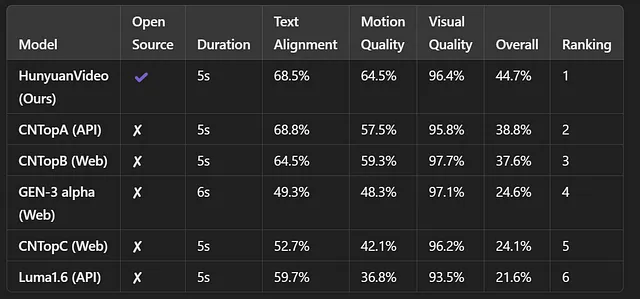
Beyond that, HunyuanVideo has also given rise to the largest video LoRA training community on CivitAI, with over 500 LoRAs available for download. (Warning: NSFW will appear if your CivitAI filters are set to show it.) It has positioned itself as the best model for those interested in
Hunyuan Video can generate videos up to 129 frames up to 720p, and setting it to 201 frames will make the output form a perfect loop - though it is believed that this is a happy accident rather than an intentional feature.
Source: Reddit
You can get started on RunPod by deploying the template Hunyuan Video - ComfyUI Manager - AllInOne3.0 by dihan which will set up a ComfyUI instance in just a few clicks.
A side view of a boxer is training in a gym with a heavy bag. The video is shot in a cinematic style with harsh sunlight pouring through the windows. The focus is on the boxer's body and how his hands impact the bag while punching.
A front view of a blonde woman in the spring, walking down a forest path, wearing a long, flowing peasant dress and holding a parasol.
LTXVideo by Lightricks
LTX-Video stands out as the first DiT-based (Diffusion Transformer) video generation model capable of producing high-quality videos in real-time. According to its developers, it can generate videos faster than they can be watched, presuming that the compute requirements do not outstrip the resolution demands (currently, this would be around 360p, presuming your step count is relatively controlled.) The hardware requirements are relatively modest compared to competitors, requiring as little as 8GB of VRAM; it can generate 720x480x121 videos in under a minute on an RTX 4060.
The model performs best with detailed prompts that focus on chronological descriptions of actions and scenes. It supports automatic prompt enhancement to improve results from short prompts. A new checkpoint was also released just two days ago, with support for keyframes and video respective, higher resolutions, and improved prompt understanding and overall quality.
LTXVideo works best on 720p and below, and can generate up to 257 frames. It tends to work better with long, descriptive prompts, as shown below.
You can try out LTXVideo with this template from hearmeman.

Wan2.1 by Alibaba
Wan2.1 is a comprehensive suite of open-source video foundation models that positions itself as a state-of-the-art contender in the video generation landscape. Unlike previous models in the list, Wan2.1 comes with multiple weights available (14b and 1.4b) as well as having separate model checkpoints dedicated to text-to-video and image-to-video, allowing for much more choice in your deployments with other models - if speed or compute resources are a concern, you can opt for the 1.4b model, or if you have a specific need for text or image to video specifically you can use a variant of the model that has been trained for that specific purpose. The lightweight T2V-1.3B model requires only 8.19GB VRAM, making it accessible on consumer GPUs while still producing high-quality results.
Wan supports 720 and 1080p resolutions up to 81 frames; however, the model is very compute-heavy compared to other models in this roundup. On the other hand, the quality speaks for itself, and puts out some very striking results if you're able to spend the compute.
You can deploy a Wan instance with this template from hearmeman.
A side view of a boxer is training in a gym with a heavy bag. The video is shot in a cinematic style with harsh sunlight pouring through the windows. The focus is on the boxer's body and how his hands impact the bag while punching.
A front view of a blonde woman in the spring, walking down a forest path, wearing a long, flowing peasant dress and holding a parasol.
SkyReels V1 by Skywork AI
SkyReels V1 is a specialized human-centric video foundation model that focuses on delivering cinematic-quality video generation with particular emphasis on realistic human portrayals. Released in February 2025, it builds upon HunyuanVideo by fine-tuning it with approximately 10 million high-quality film and television clips.
SkyReels excels in the following areas:
- Human-Centric Design - Specifically optimized for generating realistic human figures and interactions, with superior performance in facial expressions and natural movements.
- Facial Animation Excellence - Captures 33 distinct facial expressions with over 400 natural movement combinations, providing nuanced emotional portrayals.
- Cinematic Quality - Trained on Hollywood-level film and television data to produce videos with professional composition, actor positioning, and camera angles.
- Multi-Mode Generation - Supports both Text-to-Video (T2V) and Image-to-Video (I2V) generation.
Skyreels generates up to 94 frames at 960 x 544 resolution (with longer frame counts possible with optimization.)
You can get started with SkyReels by using this template from hearmeman (be sure to edit the environment variables to download the models.)
A side view of a boxer is training in a gym with a heavy bag. The video is shot in a cinematic style with harsh sunlight pouring through the windows. The focus is on the boxer's body and how his hands impact the bag while punching.
Open-Source Large-Language Models
QwQ-32B
The Qwen team has made a significant breakthrough in AI model efficiency with their newly released QwQ-32B, demonstrating that smaller models can achieve performance comparable to much larger counterparts when properly leveraging reinforcement learning techniques. This 32 billion parameter model rivals DeepSeek-R1's performance, which boasts 671 billion parameters (with 37 billion activated), showcasing the immense potential of applying RL to robust foundation models. QwQ-32B has been called "diet Deepseek" - most of the performance at a fraction of the weight.
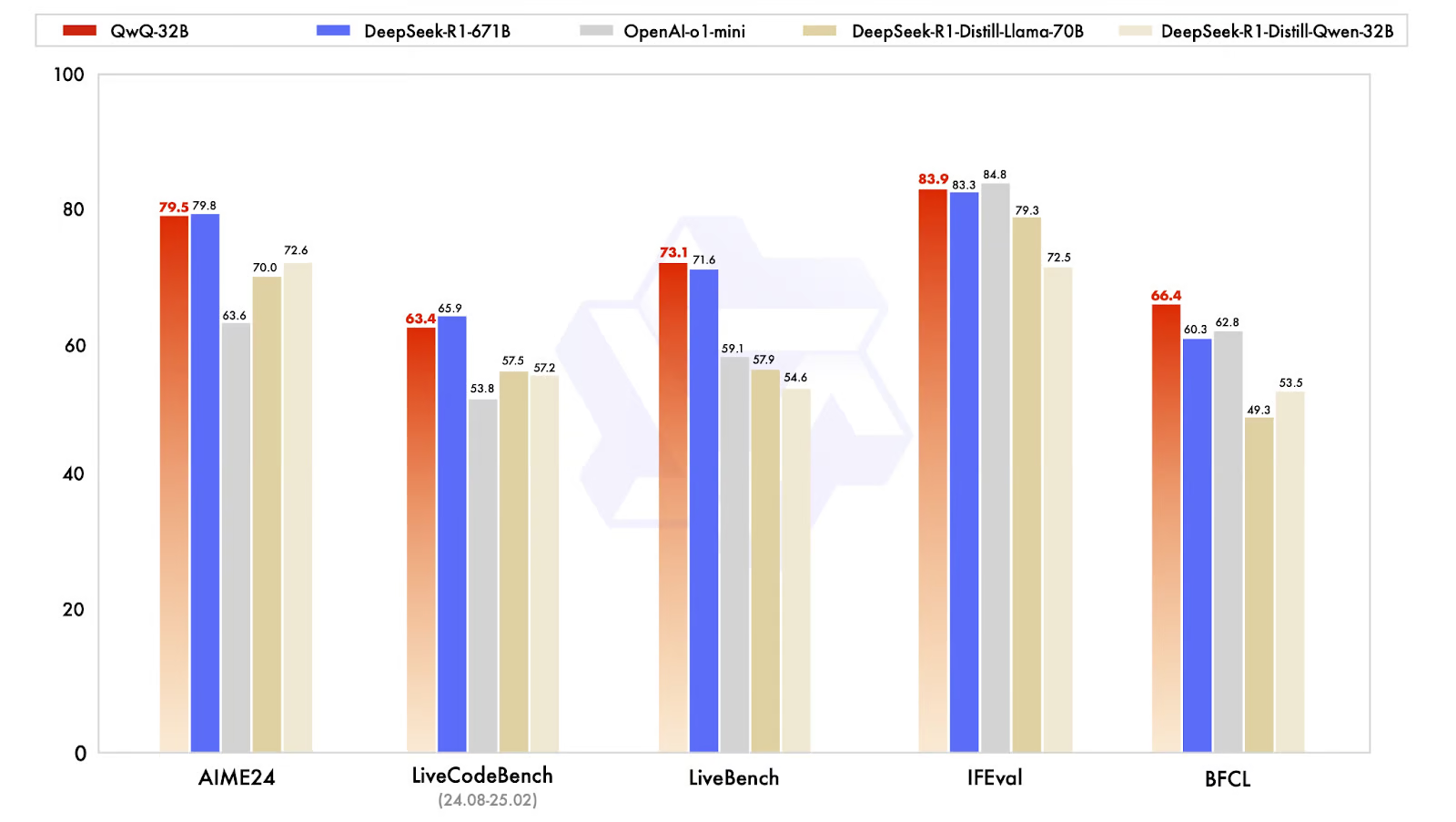
What sets QwQ-32B apart is its sophisticated training methodology, which began with a cold-start checkpoint followed by a multi-stage reinforcement learning approach. Rather than relying solely on traditional reward models, the team implemented an accuracy verifier for mathematical problems and a code execution server to assess generated code against test cases, ensuring functional correctness. After optimizing for math and coding performance, a second stage of reinforcement learning was applied to enhance general capabilities, including instruction following and alignment with human preferences, creating a well-rounded model that excels across diverse tasks.
Best use case: Mathematical reasoning, coding, problem solving.
Resources required: 1xA100 or 2xA40 (full weights), 1x A40 (8-bit), RTX A4500 (4-bit)
Gemma 3
Google DeepMind has unveiled Gemma 3, their most advanced and portable open model collection to date, designed explicitly for developers seeking to run powerful AI on modest hardware. Available in four sizes (1B, 4B, 12B, and 27B parameters), Gemma 3 marks a significant breakthrough by delivering performance that outranks much larger models—including Llama3-405B, DeepSeek-V3, and o3-mini according to human preference evaluations—while requiring only a single GPU. The 27B model in particular sits firmly among the top performers on the Chatbot Arena leaderboard with an impressive Elo score of 1338, making it an attractive option for developers seeking frontier-level capabilities without enterprise-scale computing resources.
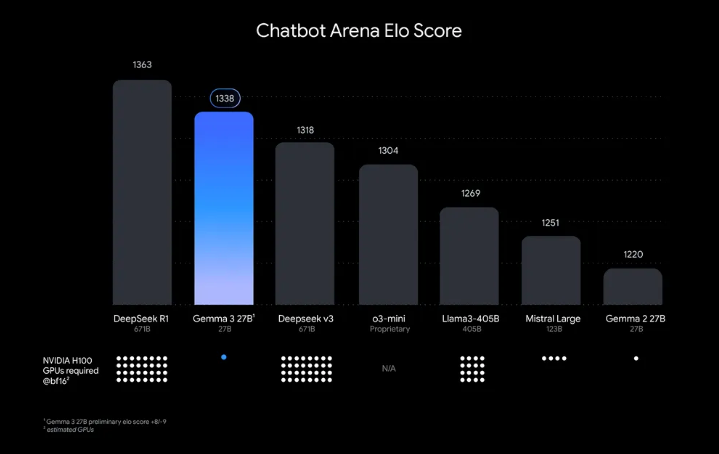
What truly sets Gemma 3 apart is its expanded multimodal capabilities, providing developers with text and visual reasoning in a surprisingly lightweight package. The models support over 140 languages, can process images and short videos, and feature an expansive 128K token context window—enabling applications to handle vast amounts of information in a single session. Technical advances include a carefully designed 5:1 ratio of local to global attention layers, which dramatically reduces KV cache memory requirements during inference, making these models exceptionally efficient even with long contexts. Official quantized versions further reduce computational requirements while maintaining high accuracy, creating an ideal balance between performance and resource efficiency.
Gemma 2 was an extremely capable model as well - but its unfortunate Achilles' heel was its 8k context size, especially since 128k was frequently the norm, even back then. Now that it has similarly expanded its context window, it's much better suited to handle document ingestion and long-context prompts.
Best use cases: General purpose, creative writing, image/video captioning.
Resources required:
- 27b: 1xA100 or 2xA40 (full weights), 1xA40 (8-bit), RTX A4000 (4-bit)
- 12b: 1xA40 (full weights), RTX 3080 (8-bit), literally anything (4-bit)
- 4b, 1b: literally anything
Note: As of the writing of this article, some packages are still pending support for the new Gemma 3 architecture, though most are slated to have updates pushed over the next few days.
Cohere Command A
Cohere has unveiled Command A, a groundbreaking generative AI model engineered specifically for enterprise environments that demand both superior performance and operational efficiency. This 111 billion parameter model delivers capabilities on par with or exceeding those of GPT-4o and DeepSeek-V3 across a spectrum of enterprise tasks, while requiring dramatically less hardware—running on just two GPUs compared to the 32 typically needed for comparable models. In head-to-head human evaluations focusing on business, STEM, and coding challenges, Command A consistently matches or outperforms its larger competitors while providing 1.75x faster token generation than GPT-4o and 2.4x faster than DeepSeek-V3, making it ideal for organizations requiring responsive AI solutions without sacrificing quality.
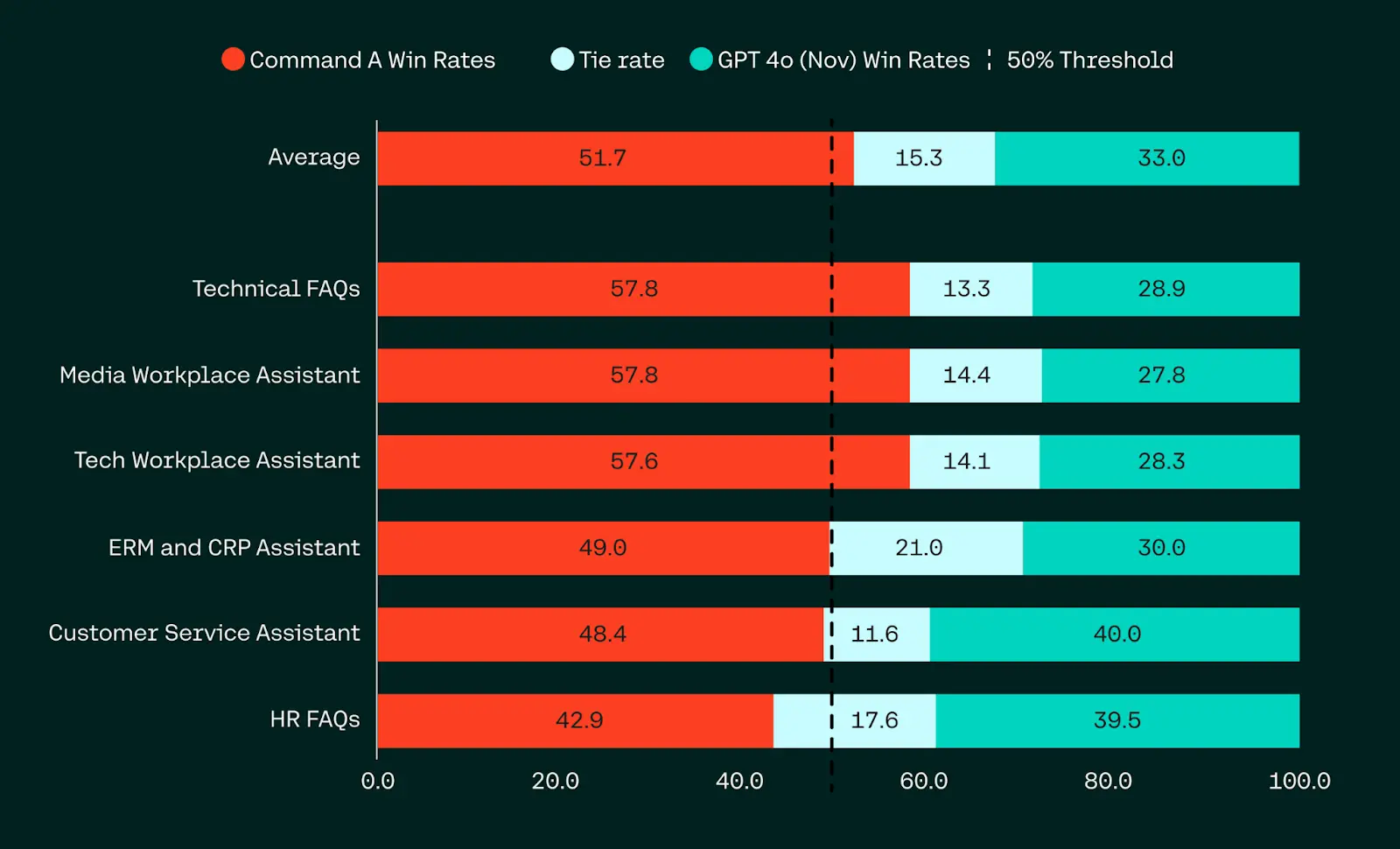
What distinguishes Command A beyond its computational efficiency is its enterprise-ready feature set, including an expansive 256K context window (twice that of most leading models) for processing extensive corporate documentation. The model excels in multilingual performance across 23 languages—including Arabic dialects, where it significantly outperforms competitors—and integrates seamlessly with Cohere's advanced retrieval-augmented generation (RAG) system to deliver verifiable citations from company data. Command A demonstrates particular strength in SQL generation, repository-level question answering, and agentic tasks like multi-turn customer support, positioning it as an ideal foundation for AI agents operating within secure enterprise environments.
With 128k context being largely the norm for open source models, Command A pushing the envelope to 256k means more room for deep repositories of information, aided by its improved processing speed.
Best use cases: Iterating over large depositories to find answers, RAG, workplace assistance.
Resources required: 2xH200 or 3xA100/H100 (full weights), 1x H200 or 2x A100/H100 (8-bit), 1x A100/H100 (4 bit)
OLMo 2 32B
The Allen Institute for AI has released OLMo 2 32B, marking a watershed moment in open AI development as the first fully open model to outperform both GPT-3.5 Turbo and GPT-4o mini across multiple academic benchmarks. This new flagship of the OLMo 2 family—which also includes 7B and 13B parameter versions—achieves comparable performance to leading open-weight models like Qwen 2.5 32B while requiring only one-third of the training compute, demonstrating remarkable efficiency in its development pathway. All components of OLMo 2—including training data, code, methodology, and model weights—are freely available to researchers and developers, creating a true end-to-end open ecosystem for state-of-the-art language model development and deployment.
The exceptional performance of OLMo 2 32B stems from a meticulously engineered development process spanning multiple training phases. The base model underwent comprehensive pretraining on 6 trillion tokens from the OLMo-Mix-1124 dataset, followed by mid-training on the curated 843 billion token Dolmino dataset with model souping techniques to enhance stability. The final post-training phase implemented the Tülu 3.1 recipe, incorporating supervised fine-tuning, direct preference optimization, and reinforcement learning with verifiable rewards (RLVR) using an innovative Group Relative Policy Optimization (GRPO) approach. This sophisticated training pipeline was powered by the newly developed OLMo-core framework, a highly efficient system designed for seamless scaling on modern hardware that supports 4D+ parallelism and fine-grained activation checkpointing.
While OLMo 2 32B only has a 4k context length at the moment, the team is aware and looking to increase it in a new release shortly.
Best use cases: Complex reasoning, knowledge retrieval, and instruction following.
Resources required: 1xA100 or 2xA40 (full weights), 1x A40 (8-bit), RTX A4500 (4-bit)
How to Run These Models on RunPod
Our serverless infrastructure will always be the premier method to deploy large language models - since you only pay for the inference time, you'll be able to get it deployed almost instantly with our vLLM quick deploy and send API requests to the endpoint. Just go to the Deploy a Serverless Endpoint page, select Text, enter the Huggingface path of the desired model, and select your suggested GPU spec as listed above. We have a full guide to deploying vLLM here.
If you would prefer to deploy a pod, I would highly recommend using the KoboldAI template as loading an 8-bit quantization will cut the resource requirements in half while not appreciably affecting performance, and providing a convenient OpenAI-compatible API endpoint in the process. We have a guide on how to do that here.
Training your own LoRAs
Want to customize these models for your own needs? Fine-tuning with LoRa lets you adapt them without needing massive compute. You can train your own LoRAs on RunPod, too! The general process is to supply videos or images with a specific file name (e.g. video_1.mp4) with a corresponding caption in a text file (video_1.txt).
- For Mochi, refer to the guide they have published on their GitHub.
- For LTX, Hunyuan, and Wan, we recommend diffusion-pipe by tdrussel and have our own guide example for Hunyuan here which will work for the other models by editing the config files.
Conclusion
Our serverless infrastructure is specifically designed to make these models accessible with zero setup time and pay-per-use pricing. Whether you're a solo developer experimenting with these new models, a researcher pushing the boundaries of what's possible, or an enterprise deploying production-grade AI solutions, our platform's flexible deployment options ensure you can leverage these breakthroughs immediately. Start building the next generation of AI applications today—the barriers to entry have never been lower.
Open-Source Video Models Have Leveled Up
Looking at what Mochi 1, Hunyuan Video, LTX-Video, Wan2.1, and SkyReels V1 can do, it’s clear that open-source video generation has taken a massive leap forward this year. The gap between free, open models and proprietary commercial options has shrunk dramatically—and in some areas, it’s practically disappeared. Each model has found its niche:
- LTX-Video specializes in real-time generation,
- SkyReels V1 is built for hyper-realistic human performances,
- Mochi 1 excels at smooth, natural motion,
- Hunyuan Video brings cinematic camera techniques into AI-generated video, and
- Wan2.1 makes high-quality video generation possible even on lower-tier hardware.
LLMs Are Moving Toward Specialized, Efficient Models
Meanwhile, in the world of language models, we're seeing a shift away from one-size-fits-all toward highly specialized, efficient models that excel in distinct areas:
- QwQ-32B leads in mathematical reasoning and problem-solving
- Gemma 3 brings multimodal intelligence with image and video processing
- Command A is built for enterprise-grade performance and RAG-powered insights
- OLMo 2 stands out as a fully transparent, open-source research model
This shift suggests an AI ecosystem where developers choose the right model for the task at hand, rather than relying on a single dominant model. And since all these releases are open source, they’ll only improve as researchers, engineers, and tinkerers across the world fine-tune, optimize, and expand their capabilities.