How To Use Very Large Language Models with RunPod - 65b (and higher) models


Many LLMs (such as the classic Pygmalion 6b) are small enough that they can fit easily in almost any RunPod GPU offering. Others such as Guanaco 65B GPTQ are quantized which is a compression method. to reduce memory usage, meaning that you will be able to fit the model into a smaller card. This will give you many of the benefits of being able to use model, but can also reduce the level of performance you might derive from it. The language that the model uses will be less precise compared to using the same model "straight out of the box." If you need the highest level of power possible out of a large model without compromising its quality, then you may need to assign multiple cards to a pod and do some extra configuration to get the model up and running. With unquantized models starting at 65b or so, multi-GPU pods will become necessary as these models will generally not fit in even a single A100 with 80GB of VRAM. (We'll get into how to use quantized models and their benefits and tradeoffs out of the box in another article, but let's look at how to get these huge models up and running with their full, uncompromised precision.)
Why use a larger model?
Using a large language model with more parameters can result in better performance for natural language processing tasks. A larger model has the capacity to capture and represent the complexities of language, allowing it to learn patterns and relationships between words that smaller models may miss. This improved understanding of subtle nuances in word usage helps the model make predictions about unseen data with greater accuracy. Additionally, a larger language model can contain more features than its smaller counterparts, giving it potentially richer representations of text which could be used by downstream applications such as machine translation or sentiment analysis. Your mileage may ultimately vary based on your needs, especially since different models have different training data – and a larger model is not automatically better based on its parameter count – but all other things being equal, a model with more parameters will have more tools in its toolbox for any given prompt.
(If you've only ever used the smaller Pygmalion models, I seriously can't stress how much your experience might be if you can afford to give the higher WizardLM or Guanaco models a spin!)
The rule of 2
Although each model varies slightly with its memory needs, the general rule of thumb is that you will need 2gb of VRAM per billion parameters to use the base model. This means that if you want to mount a 65b model, you'll need to spin up a pod with two A100s at the very least to get the ~130GB of memory you need.
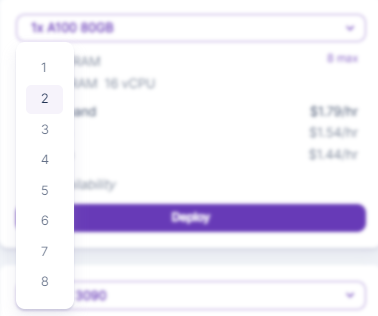
Alternatively, you can create a pod with other card configurations, such as a pod with 3 to 4 A40s which have 48GB of RAM each. However, due to the way that language inference works, you'll likely see a performance drop-off with each successive card added, as the model will be spread over multiple GPUs and have to search through the memory of each card while doing its computations, which is quite a different experience compared to the performance gain you might experience by assigning multiple GPUs to Stable Diffusion. Long story short, you're going to be better off using a couple of high-powered cards, rather than trying to use, say, eight A4000s, even if the total amount of VRAM is the same.
For some of the largest models, like BLOOMChat with its whopping 176 billion parameters, you may need to assign it even more A100s or other 80gb card offerings.
Ensure that all the cards are being utilized
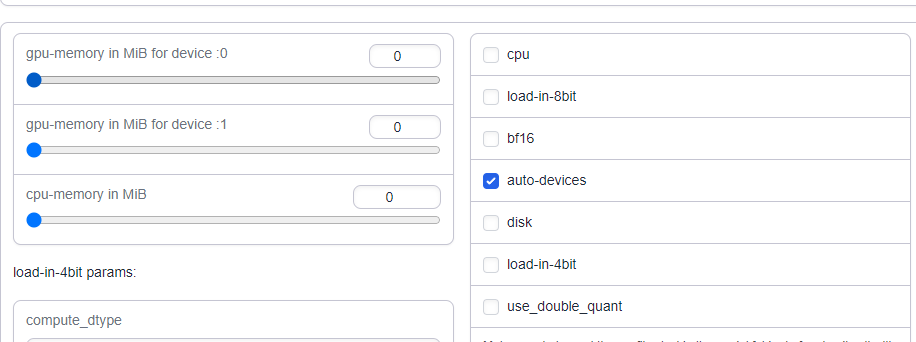
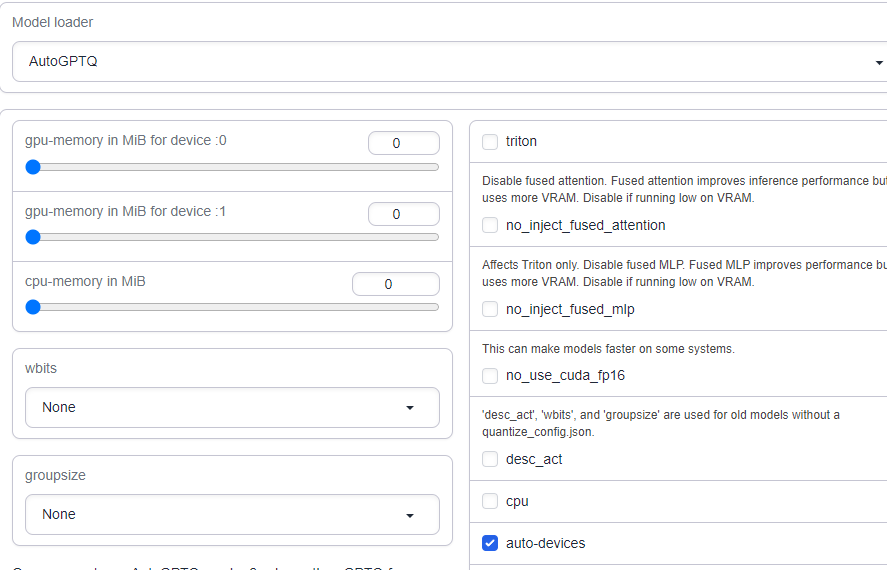
Once you have the model downloaded and set up, depending on the model type you'll want to be sure that the model actually uses all of the cards assigned to the pod. Otherwise, it may attempt to use up all the VRAM in a single card and then throw a CUDA out of memory error, even though there are perfectly serviceable cards that it may not see.
For Transformer and GPTQ models, ensure that you have the auto-devices checkbox checked under the Model tab.
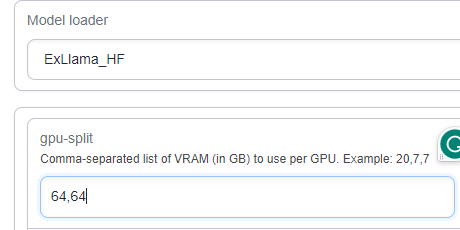
For Llama models, you might need to instead manually assign the VRAM amounts under the gpu-split parameter:
Questions?
Feel free to reach out to us on our Discord if you have any trouble getting a model loaded!