How to run vLLM with RunPod Serverless


In this blog you’ll learn:
- When to choose between closed source LLMs like ChatGPT and open source LLMs like Llama-7b
- How to deploy an open source LLM with vLLM
If you're not familiar, vLLM is a powerful LLM inference engine that boosts performance (up to 24x) - if you'd like to learn more about how vLLM works, check out our blog on vLLM and PagedAttention.
Choosing Between Closed Source and Open Source LLMs
When deciding between a closed source LLM like OpenAI's ChatGPT API and a open source LLM like Meta’s Llama-7b, it's crucial to consider cost efficiency, performance, and data security. Standard models are convenient and powerful, but open source LLMs offer tailored performance, cost savings, and enhanced data privacy.
Open source models can be fine-tuned for specific applications, ensuring accuracy in niche tasks. While the initial costs might be higher, ongoing expenses can be lower than standard APIs, especially for high-volume use cases. These models also provide greater control over data, which is essential for sensitive information, and offer scalability and adaptability to meet evolving needs. Here’s a table to help you understand the differences better:
| Criteria | Open Source LLMs | Closed Source LLM APIs |
|---|---|---|
| Tailored Solutions | Domain-specific | General-purpose capabilities |
| Cost | Lower long-term costs | Lower short-term costs |
| Data Privacy | Greater control | Limited control |
| Scalability | Flexible and adaptable | Fixed |
| Performance | Superior for specific tasks | Robust general performance |
Now that we’ve established why open source LLMs could be the right fit for your use case, let’s explore a popular open source LLM inference engine that will help run your LLM much faster and cheaper.
What is vLLM and why should you use it?
vLLM is a blazingly fast LLM inference engine that lets you run open source models at 24x higher throughput than other open source engines.
vLLM achieves this performance by utilizing a memory allocation algorithm called PagedAttention. For a deeper understanding of how PagedAttention works, check out our blog on vLLM.
Here are the key reasons why you should use vLLM:
- Performance: vLLM achieves 24x higher throughput than HuggingFace Transformers (HF) and 3.5x higher throughput than HuggingFace Text Generation Inference (TGI).
- Compatibility: vLLM supports thousands of LLMs and an ever-growing list of transformer architectures. vLLM is also GPU agnostic, working with NVIDIA and AMD GPUs, making it compatible with any GPU workload.
- Developer ecosystem: vLLM has a thriving community of 350+ contributors who constantly work to improve its performance, compatibility, and ease of use. Typically within a few days of a new breakthrough open source model being released, it is vLLM compatible.
- Ease of use: vLLM is easy to install and get started with.
Now let's dive into how you can start running vLLM in less than a few minutes.
How to deploy your model with vLLM on RunPod Serverless
Follow the step-by-step guide below with screenshots and video walkthrough at the end to deploy your open source LLM with vLLM in less than a few minutes.
Pre-requisites:
- Create a RunPod account here. Heads up, you'll need to load your account with funds to get started.
- Pick your Hugging Face model and have your Hugging Face API access token (found here) ready if needed.
Step-by-step Guide:
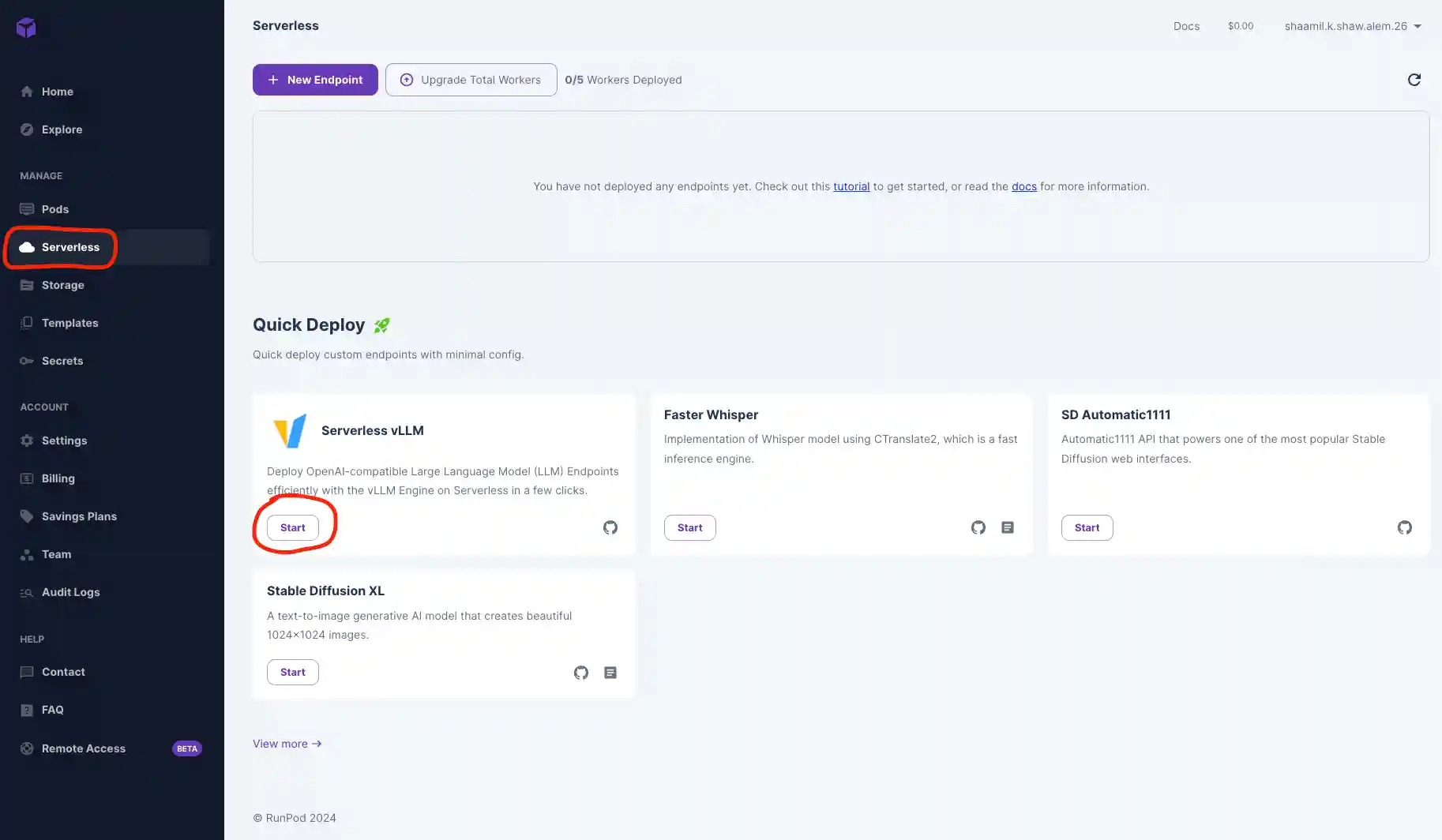
- Navigate to the Serverless tab here in your RunPod console and hit the Start button on the Serverless vLLM card under Quick Deploy.
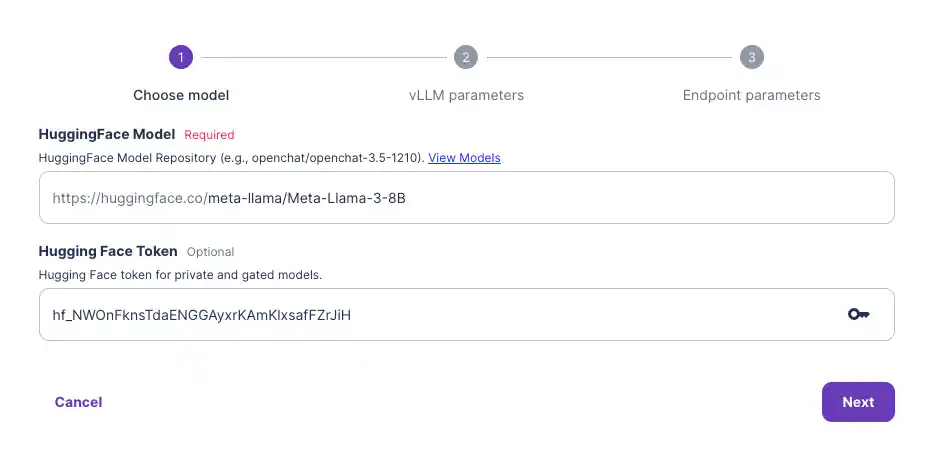
- Input your Hugging Face model along with the access token that you can get from your Hugging Face account (found here).
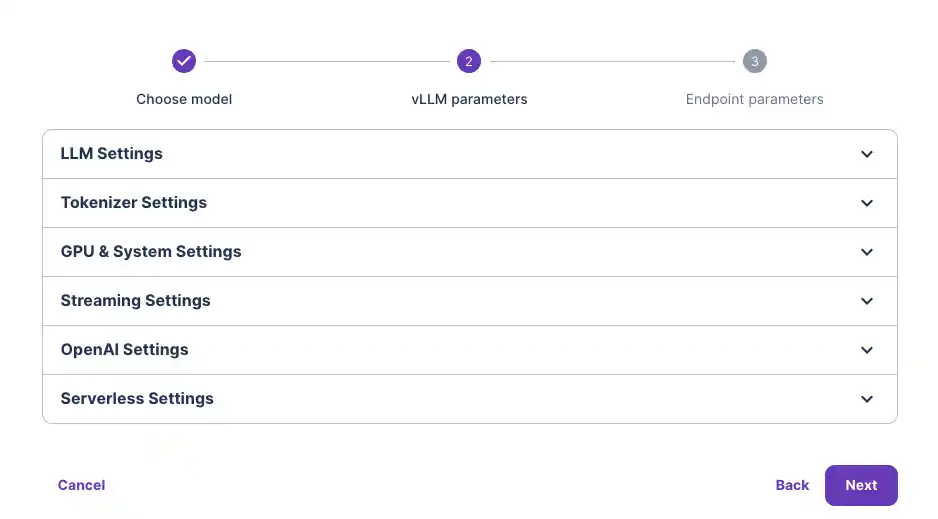
- You are given the option to customize your vLLM model settings. For most models, this is not required to get them running out of the box. But it may be required for your model if you're using a quantized version like GPTQ, for example, in which case you would need to specify the quantization type in the “Quantization” drop-down input.
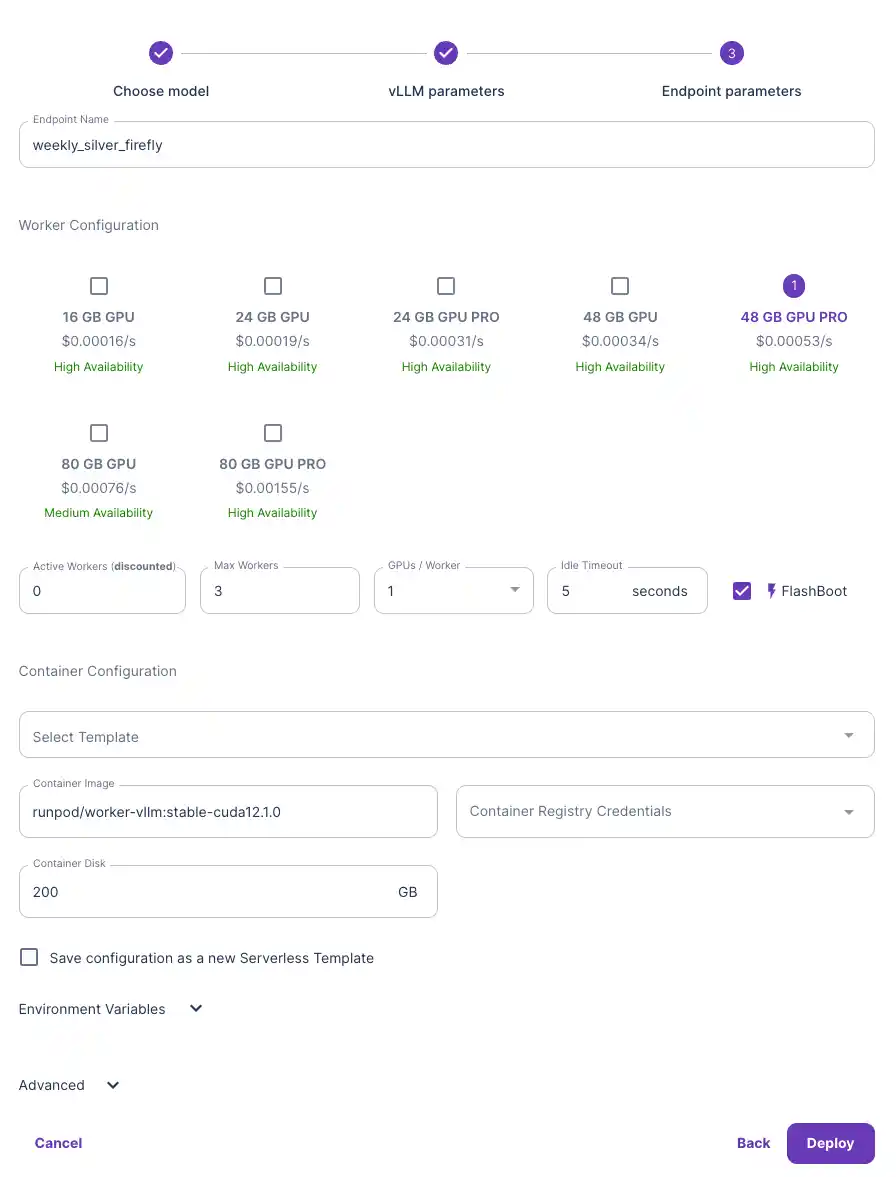
- Select the GPU type you would like to use. For a guide to selecting the right GPU VRAM for your LLM, checkout our blog: Understanding VRAM and how Much Your LLM Needs. For now, 48 GB should do fine for my Llama3-8b model. Now deploy!
- Now that you’ve deployed your model, let’s navigate to the “Requests” tab and test that our model is working.
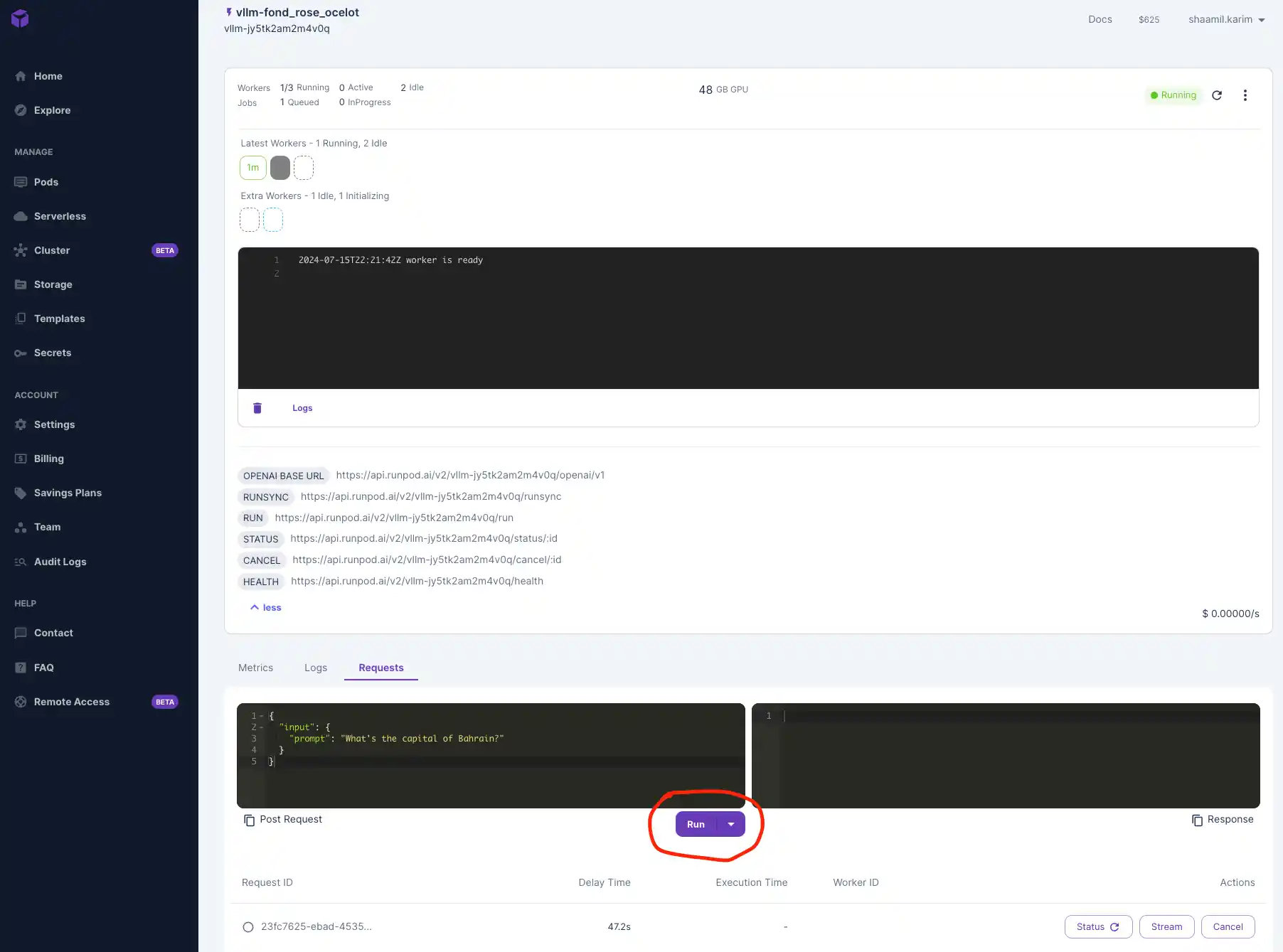
- Use the placeholder prompt or input a custom one and hit Run!
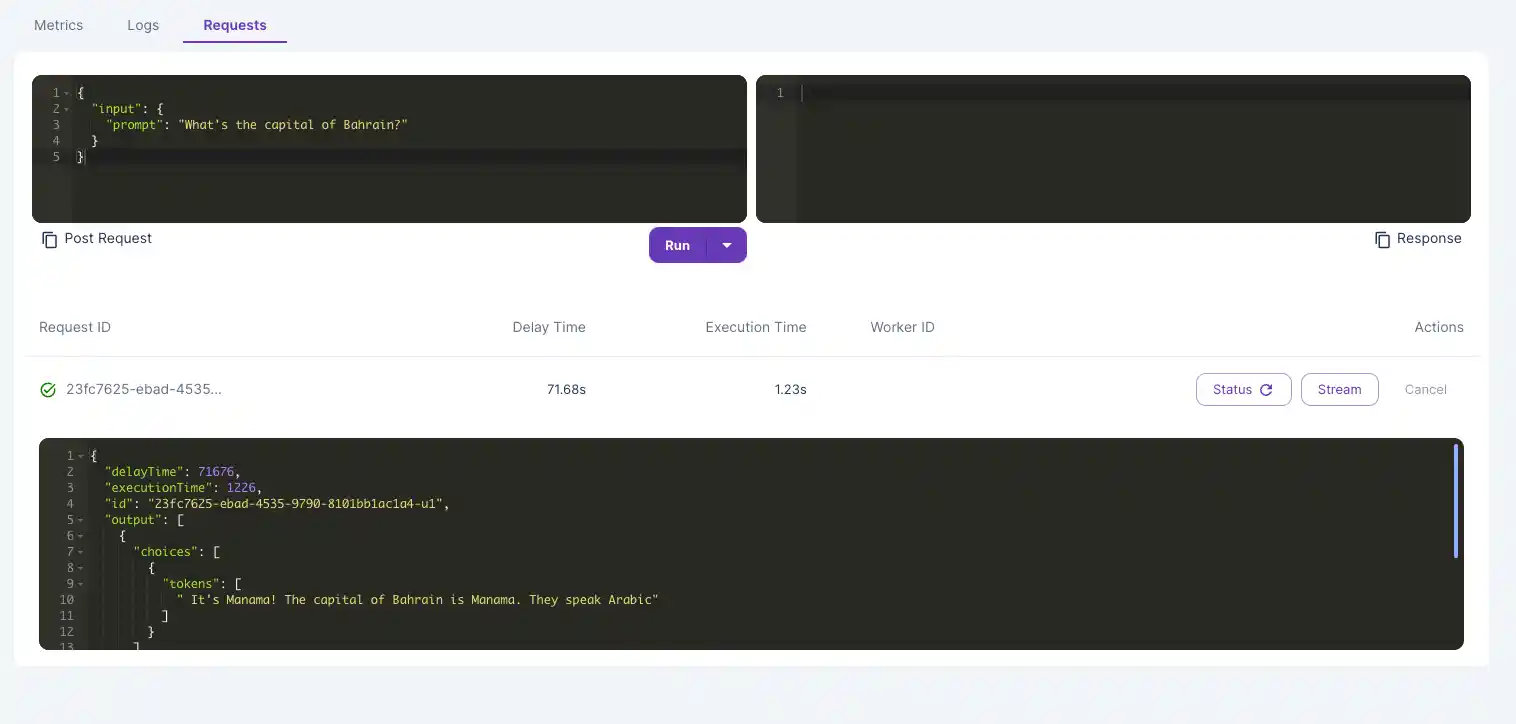
- After your model is done running, you’ll see your outputs below the Run button.
Video guide:
Troubleshooting
When sending a request to your LLM for the first time, your endpoint needs to download the model and load the weights. If the output status remains "in queue" for more than 5-10 minutes, read below!
- Check the logs to pinpoint the exact error. Make sure you didn't pick a VRAM that was too small. You can estimate the amount VRAM you'll need by using an estimator tool like this one.
- If your model is gated (ex. Llama), first make sure you have access, then paste your access token from your hugging face profile settings when creating your endpoint.
Conclusion
To recap, open source LLMs boost performance through fine-tuning for specific applications, reduce inference costs, and maintain control over your data. To run your open source LLM, we recommend using vLLM - an inference engine that's highly-compatible with thousands of LLMs and increases throughput by up to 24x vs. other engines.
Hopefully by now, you should have a stronger grasp of when you should use closed source vs open source models and how to run your own open source models with vLLM on RunPod.