How KRNL AI Scaled to 10,000+ Concurrent Users while Cutting Infrastructure Costs by 65% with RunPod Serverless


When Giacomo, Founder and CPO of KRNL, reached out to RunPod in May 2023, we weren’t actually sure if we could support his use case. They needed a provider that could cost-effectively scale up to handle hundreds of thousands of users, and scale back down to zero in minutes.
At the time, we hadn’t had to scale up to >1200 Serverless workers on one-endpoint. We had good reasons to believe our systems could autoscale to handle the volume, but it had not been stress-tested in production. But, we were able to support KRNL (albeit with a few growing pains) through every one of their viral spikes over the last 12 months. To this day, KRNL uses RunPod to handle all inference for their consumer applications.
About KRNL
KRNL builds products that make AI accessible to anyone. Their flagship product, Loopsie, is an AI photo generator and editor that lets you turn your pictures into 3D characters.
Giacomo had been using another leading Serverless provider to run their Deforum inference, but ran into serious cost constraints as his usage scaled. KRNL’s product was built so well that it would grow virally as soon as it launched in any region.
Their product first went viral in Thailand, rapidly gained hundreds of thousands of users, and nearly melted down their infrastructure provider in the process. When they got hit with a big bill at the end of the month, they started looking elsewhere.
Switching to RunPod Serverless
Giacomo had his eyes set on scaling to Russia and Kazakhstan next. All he needed was a provider that could:
1) cost-effectively scale to millions of users.
2) be reliable across multiple regions.
He didn’t need the fastest cold-start times, he was perfectly fine with users waiting longer for Derofum inference if it meant that his costs stayed low.
When Giacomo reached out, he had already gotten set up with his own RTX 4090 endpoint on RunPod Serverless. He put together his own benchmarks that showed something remarkable — the 4090s performed at nearly the same speed as the A100s he was using with his earlier provider. But at a 65% reduction in cost.
Saving time, not just money
In the early days, KRNL wanted to optimize their container images so they would load faster on serverless workers. What started out as our engineering team debugging custom container issues to reduce a single customer’s pain point eventually became Flashboot — the caching optimization layer we built to reduce cold-start time to under 250ms.
Getting to launch faster is crucial for a company like KRNL that goes viral so frequently. Developer time saved on ML ops is added cost savings in their pockets. And by not spending time setting up infrastructure, they have more time to do what they do best: making accessible AI.
Scaling to 1200+ concurrent serverless workers
This is what KRNLs GPU cloud spend looked like with RunPod right after they switched:
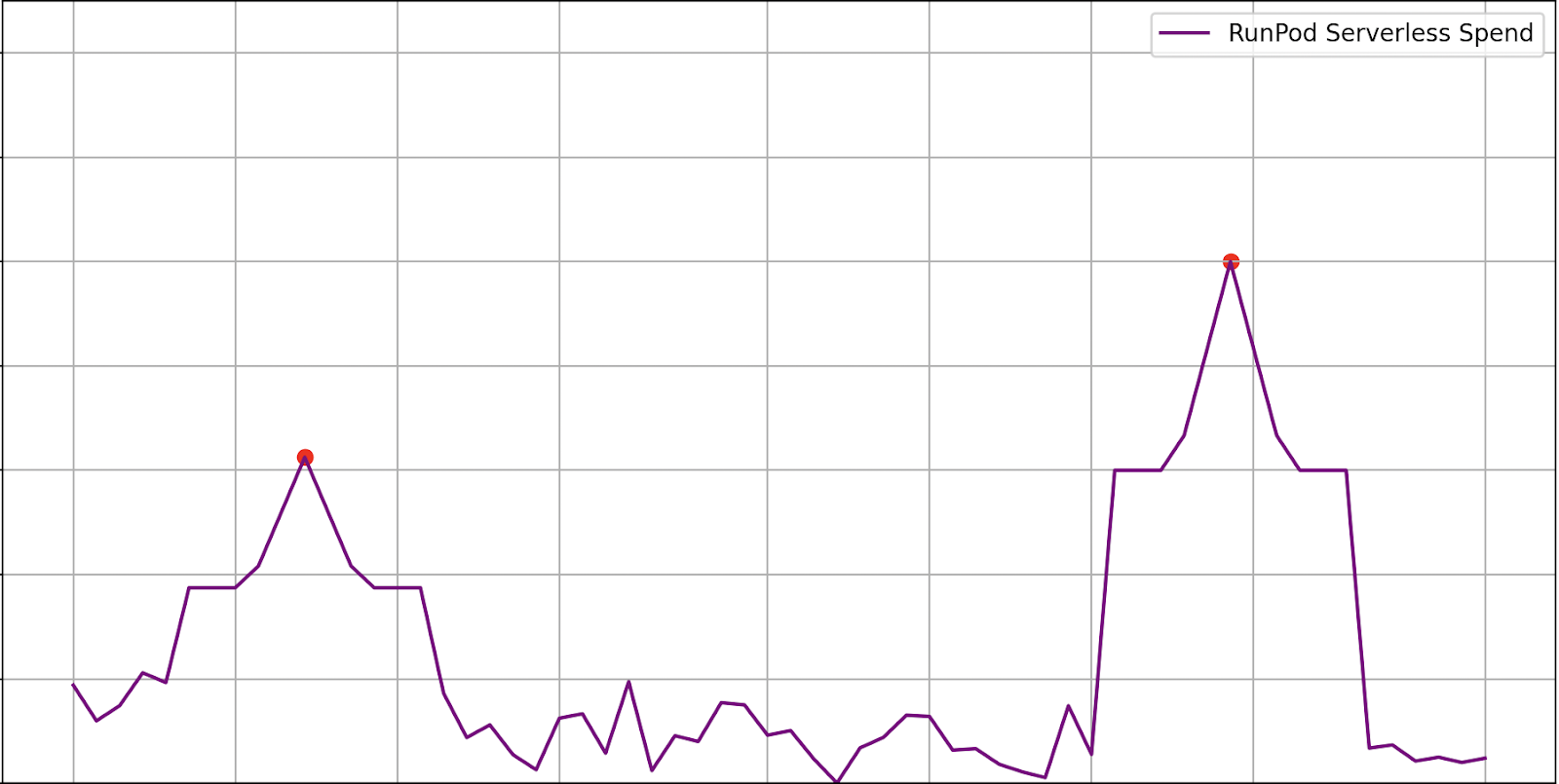
And this is what their spend looks like when you plot it against their spend on their previous provider:
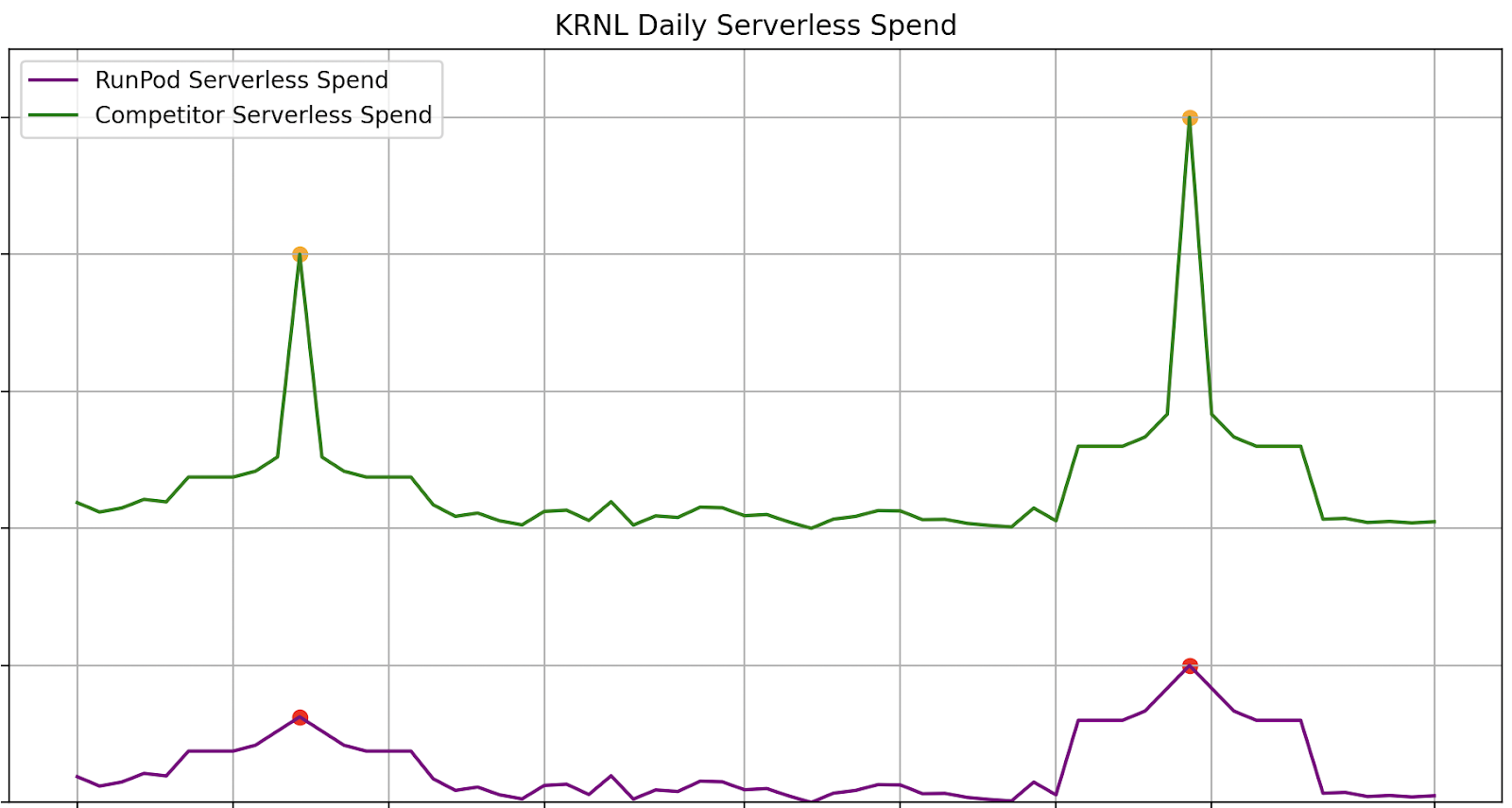
After switching to RunPod Serverless, they were able to reduce their costs by two-thirds, run their models with low latency due to multi-region support, and maintain uptime through several quick spikes of virality.
RunPod looks forward to supporting KRNL as they look to scale their Machine Learning inference. If you’re in the same boat as them, try out RunPod serverless here or book a call with our team to learn more.