Deploying Multimodal Models on RunPod


Multimodal AI models integrate various types of data, such as text, images, audio, or video, to allow tasks such as image-text retrieval, video question answering, or speech-to-text. Examples are CLIP, BLIP, and Flamingo, among others, showing what is possible by combining these modes–(but deploying them presents unique challenges including high computational requirements, complex data pipelines, and scalability concerns.
RunPod offers a robust cloud platform specifically optimized for AI workloads, making it ideal for deploying resource-intensive multimodal models. This guide provides detailed, step-by-step instructions for successfully deploying multimodal AI models on RunPod.
Challenges of Multimodal AI Deployment
Resource Requirements
Multimodal models process complex datasets that combine modalities, such as pairing text and images. This inevitably adds a higher bar to clear for VRAM and compute needs. For example, llama-3.2 90b Vision could be described as the 70b parameters of the LLM itself, with another 20b of vision parameters "bolted on." Most multimodal models require at least 16GB VRAM for inference, bare minimum.
Integration
There is always a jam in aligning multiple modalities within the inference pipelines. For example, combining image preprocessing with text embedding generation requires seamless orchestration.
Scalability
Multimodal deployments demand elasticity to handle varying workloads, especially in production scenarios where demand keeps fluctuating.
Preparing for Deployment
Environment Setup
Create a RunPod account at runpod.io, if you haven't already done so. Then, select an appropriate GPU instance based on your model requirements. For CLIP/BLIP: a smaller GPU spec like the A40 (48GB) will get the job done. For larger models still, A100 (80GB), H200 (141GB) or multiple GPUs may be necessary.
RunPod offers a number of pre-set templates that comes with most common libraries pre-installed - you can start with the official PyTorch templates, for example.
If you'd rather create and push your own Docker file, that's certainly an option, too. An example Docker build may look something like this:
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
# Set environment variables
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
ENV PATH="/usr/local/cuda/bin:${PATH}"
# Install system dependencies
RUN apt-get update && apt-get install -y --no-install-recommends \
python3.10 \
python3-pip \
python3-dev \
git \
wget \
libgl1-mesa-glx \
libglib2.0-0 \
&& rm -rf /var/lib/apt/lists/*
# Set working directory
WORKDIR /workspace
# Install Python dependencies with pinned versions
COPY requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt
# Copy model loading and inference scripts
COPY app/ /workspace/app/
# Set entrypoint
ENTRYPOINT ["python3", "/workspace/app/main.py"]With your example requirements.txt set up like this:
torch==2.0.1
torchvision==0.15.2
transformers==4.33.1
pillow==10.0.0
numpy==1.24.3
ftfy==6.1.1
regex==2023.8.8
tqdm==4.66.1
tensorboard==2.13.0Preparing the Model
Here's an example of how you might use CLIP to classify an image, in code:
%%writefile app/model_loader.py
import os
import torch
from transformers import CLIPProcessor, CLIPModel
def load_clip_model():
# Check for GPU availability
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# Load model and processor
model_name = "openai/clip-vit-large-patch14"
model = CLIPModel.from_pretrained(model_name).to(device)
processor = CLIPProcessor.from_pretrained(model_name)
# For production, consider enabling evaluation mode
model.eval()
return model, processor, deviceAnd here's the code for running queries against an example:
import os
import torch
import numpy as np
from PIL import Image
from model_loader import load_clip_model
import matplotlib.pyplot as plt
# Load model when container starts
print("Loading CLIP model...")
model, processor, device = load_clip_model()
print("Model loaded successfully!")
def process_image_text_pair(image_path, text_queries):
"""
Process an image with multiple text queries through CLIP
Returns similarity scores for each query
"""
try:
# Load and preprocess image
image = Image.open(image_path).convert("RGB")
# CLIP requires specific input format
# Process each text query individually
similarity_scores = []
for query in text_queries:
inputs = processor(
text=[query], # Note: text needs to be a list even for single item
images=[image],
return_tensors="pt",
padding=True
)
# Move inputs to the same device as model
inputs = {k: v.to(device) for k, v in inputs.items()}
# Run inference with no gradient calculation for efficiency
with torch.no_grad():
outputs = model(**inputs)
# Get similarity score for this text-image pair
similarity = outputs.logits_per_image[0][0].item()
similarity_scores.append(similarity)
return {
"similarity_scores": similarity_scores,
"success": True
}
except Exception as e:
return {"error": str(e), "success": False}
def run_example(custom_image_path=None):
"""
Run an example operation to verify the model works
"""
# Use provided image path or default to example
image_path = custom_image_path if custom_image_path else "example_image.jpg"
# Define some example text queries
text_queries = [
"a photo of a person wearing a beanie",
"a photo of a kitchen",
"a person wearing gloves",
"a person examining something small"
]
# Process all queries at once
result = process_image_text_pair(image_path, text_queries)
if result["success"]:
scores = result["similarity_scores"]
results = list(zip(text_queries, scores))
# Sort by score in descending order
results.sort(key=lambda x: x[1], reverse=True)
print("\nResults (sorted by similarity):")
for query, score in results:
print(f"Query: '{query}' - Similarity score: {score:.4f}")
# Display image with results
try:
plt.figure(figsize=(10, 6))
# Show image
image = Image.open(image_path)
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.title("Input Image")
plt.axis("off")
# Show results as bar chart
plt.subplot(1, 2, 2)
queries = [r[0] for r in results]
scores = [r[1] for r in results]
y_pos = np.arange(len(queries))
plt.barh(y_pos, scores)
plt.yticks(y_pos, queries)
plt.xlabel("Similarity Score")
plt.title("CLIP Text-Image Similarity")
plt.xlim(0, max(scores) * 1.1) # Set reasonable x-axis limits
plt.tight_layout()
plt.savefig("clip_results.png")
print("Results visualization saved to 'clip_results.png'")
# Show in notebook if running in one
plt.show()
except Exception as e:
print(f"Error creating visualization: {str(e)}")
else:
print(f"Error processing image: {result.get('error', 'Unknown error')}")
if __name__ == "__main__":
print("Running CLIP example...")
# Replace with your actual image path
run_example("example_image.jpg")
print("Example completed!")
Here's how this would look in action:
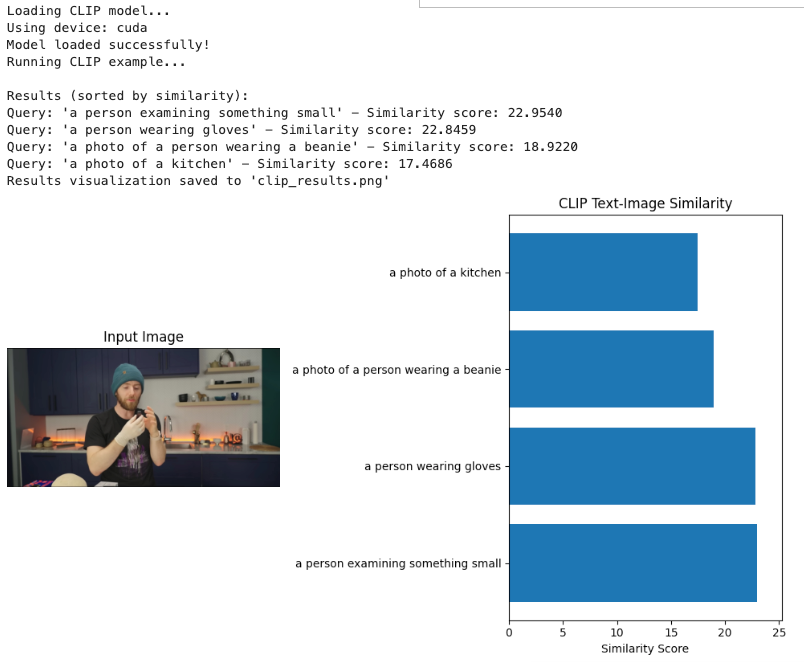
Conclusion
RunPod provides an excellent platform for deploying resource-intensive multimodal AI models. By following these detailed steps, you can deploy models like CLIP, BLIP, or Flamingo with optimal performance and scalability. The platform's GPU-focused infrastructure, combined with proper containerization and API design, enables efficient serving of multimodal models for production use cases.
Remember to regularly update your models and monitor performance to ensure your deployment remains efficient and cost-effective over time.