DeepSeek R1 - What's the Hype?


DeepSeek R1 is a recently released model that has been topping benchmarks in several key areas. Here's some of the leaderboards it's shot to the top of:
- LiveBench: Second place, with only GPT4 o1-2024-12-17 surpassing it as of this writing.
- Aider: Ditto.
- Artificial Analysis: Fifth place, beaten only by closed models Sonnet 3.5 and Gemini/OpenAI.
And finally, R1's release paper also shows how it holds up against several other closed source models:
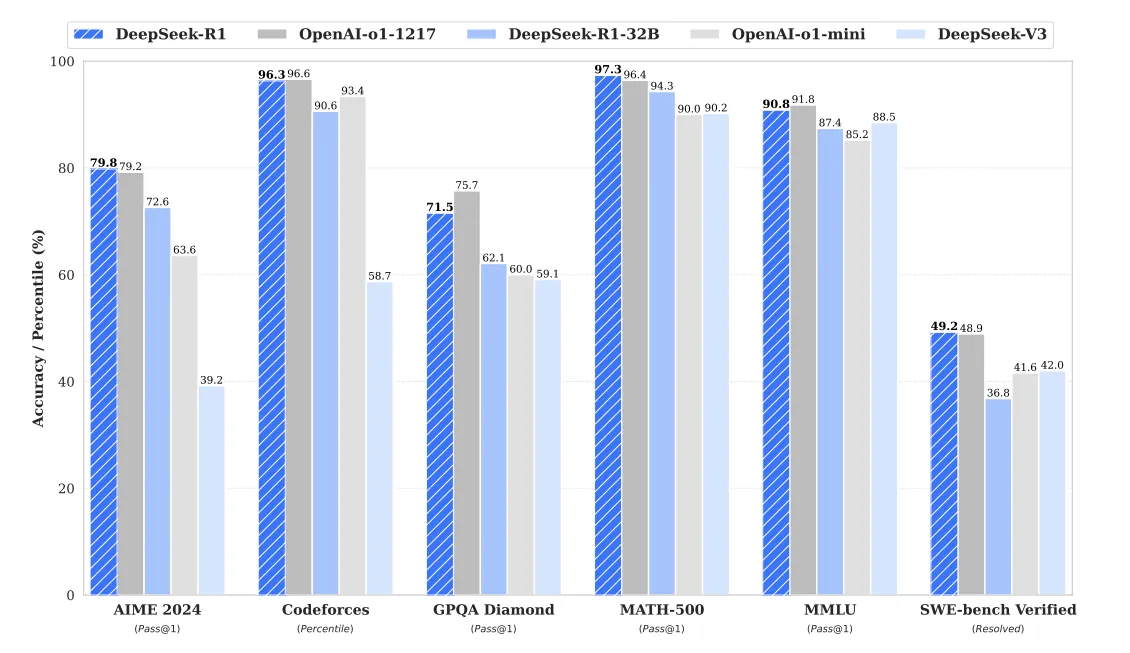
Having an open-weights model that's able to run with the best of walled-off closed models is legitimately exciting. We've written before about how important it is to have access to high-quality open source models, but the tl;dr is that you have privacy and security running local models on RunPod without having to worry about these models being trained on your sensitive data (remember that old adage about if the service is free, you're the product.)
So what makes R1 so special?
Chain of Thought Prompting
Chain of thought prompting is an approach that encourages LLMs to break down their reasoning process into explicit steps, similar to how humans solve complex problems. Rather than just asking for an answer, we guide the LLM to "show its work" by thinking through the problem systematically.
There are limits to how much you can load into a prompt for large language models. Think of each additional request in a given prompt as an additional ball you're giving to a juggler. A newbie juggler (a small LLM) might only be able to keep two balls in the air at once and will start dropping them quickly the more you give them. But even the best jugglers can only keep so many balls in the air. The more you give an LLM to do in a single shot, the more likely it is to elide requests within that prompt, or forgo one request in the service of another.
In contrast, chain of thought allows the juggler to compartmentalize the motion of keeping each ball in the air, without forcing it to think about the balls that are currently in the air. Moving the hands is the core driver of keeping the juggle going, not thinking about the balls that are already in the air. Just as a juggler doesn't need to actively think about a ball that's already following its predetermined arc, an LLM using chain of thought prompting doesn't need to actively hold every previous step of its reasoning in working memory. Once a logical step has been written down and its implications understood, the model can let that piece "follow its arc" while focusing attention on the next immediate logical move it needs to make.
Chain of thought prompting is not new by any means, but what is new with R1 is you can extract that reasoning and send it to any model you want. You can see the individual thinking steps that it's taking. There's a lot of science and proof that it's boosted the accuracy and output of LLMs, but to actually see the intermediate steps has been the hidden domain of the big closed models, up until now. CoT has been up until now a very "under the hood" practice with open source LLMs. We knew it existed, we knew it worked, but the internal steps were something of a black box in practice until you got to a very low level. R1 is different because it reasons through each step individually instead of figuring it all out in the same response, and you can see the way it thinks almost in real-time.
By the way, you can extract JUST the reasoning from deepseek-reasoner, which means you can send that thinking process to any model you want before they answer you.
— Pietro Schirano (@skirano) January 22, 2025
Like here where I turn gpt-3.5 turbo into an absolute genius! pic.twitter.com/vB1nd9xrJJ
A chain of thought prompt would look something like this:
A store is having a 20% off sale.
Sarah buys a shirt originally priced at $45 and pants originally priced at $65.
The store charges 8% sales tax on the final discounted price.
How much does Sarah pay in total?
Let's solve this step by step.
For each step, explain your thinking and show your calculations.And you might get a response like this:
First, I'll calculate the discount on each item:
Shirt discount: $45 × 20% = $45 × 0.20 = $9
Pants discount: $65 × 20% = $65 × 0.20 = $13
Next, I'll find the discounted prices:
Discounted shirt price: $45 - $9 = $36
Discounted pants price: $65 - $13 = $52
Now I'll add the discounted prices together:
Subtotal after discount: $36 + $52 = $88
Finally, I'll calculate and add the sales tax:
Sales tax: $88 × 8% = $88 × 0.08 = $7.04
Total price: $88 + $7.04 = $95.04
Therefore, Sarah will pay $95.04 in total.You can check the deepseek_reasoning JSON tag to see the model's internal train of thought, or have it output visibly as listed in the movie above.
How to get started with DeepSeek R1 on RunPod?
I won't lie - this is a very large model and will be spendy to run compared to other LLMs - it is 671B after all. You would need over 1300GB of VRAM to run it at full weights, which would easily reach $30+/hr of GPU spend just for one cluster. Fortunately there's a number of ways to either run R1 itself at a more acceptable price point, or to benefit downstream from its use.
Distillations
In the context of large language models (LLMs), distillation is a process where we take a large, powerful model (called the "teacher" model) and try to transfer its knowledge and capabilities into a smaller, more efficient model (the "student" model). R1 being so high on the leaderboards means that it has a lot to teach, and it being an open model means its knowledge is freely accessible - a potent combination. DeepSeek has already run this process on several popular models:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
- deepseek-ai/DeepSeek-R1-Distill-Llama-7B
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
These are just standard transformers models and can be run as you would any other model (check out my video on setting up LLMs in serverless, if you're interested.)
All of the chain of thought prompting mentioned above should function about as well in the distillations as it does in the base model.
Be aware that are a number of tutorials out there claiming that you can "run Deepseek R1 on 16GB on VRAM!" This is misleading. The base R1 model will not run on anything close to that, no matter what level of quantization you use, it's simply far too large. What those tutorials are referring to is running the distillations above, the smallest of which would fit. The distillations existing is a great thing, but running one of them is "not running DeepSeek R1", strictly speaking.
Quantizations
The community has been very helpful in quantizing R1 with a quickness. Check out unsloth's huggingface page for GGUF quant of the model. You could run Q4 in a 4 to 5x H200 pod. Because it's a mixture of experts model, it's going to be generally easier to get more acceptable speeds with such a large model than, say, hosting Llama3 405b in a pod.
If you want to just get a pod up and running with an API endpoint so you can immediately begin testing with GGUF, kobold.cpp is in my experience the quickest way to do so and is my personal go to. This will get a pod spun up in just a few minutes, where you can test it and then invest in a more specialized solution if you like what you see.
Further, you can use Unsloth's dynamic quantization that drops down as low as 1.58 bits, meaning that you can fit it in as low as 2 A100 or H100 cards - putting it well within the reach of even running into serverless. They accomplish this by quantizing selective layers to 4-bit (generally considered the lowest level of quant that still maintains most of the model's performance) while leaving others at a lower level.
Full weights
Right now, running R1 at full weights probably isn't going to be a feasible task without setting up something like distributed inference with multiple nodes. This would take more memory than you can get in a single pod with 8xH200s so some level of distribution is going to be necessary. (If you do go this route, though, reach out to us, we would love to talk about your case study.)
Conclusion
R1 puts us back squarely into a really exciting time for LLMs. In my personal opinion, LLMs have seen primarily incremental improvements over the past year or so (barring some notable interesting cases like Nemotron) but to have such closed-source power combined with open-source accessibility really begins to re-open competition against the big closed-off model providers.
Questions? Hop into our Discord and ask away!