Breaking Out Of The 2048 Token Context Limit in Oobabooga


Since its inception, Oobabooga has had a hard upper limit of context of 2048 tokens for how much it can consider. Since this buffer includes everything in the Chat Settings panel including context, greeting, and any additional recent entries in the log, this can very quickly fill up to the point where it loses memory of major entries to the ether, which can very quickly break your immersion or require manual editing of the bot's output to keep things moving on.
As of the latest version of Oobabooga, this context size has now quadrupled to 8192, giving you much more room to work with. When combined with other plugins such as long term memory, you can keep your scenes going for much, much longer than you would normally be able to.
How to ensure the latest Oobabooga version is installed
The latest version of Oobabooga is required as the trust-remote-code flag must be enabled within your install; while this flag is available in older versions, it is implemented in a way such that you still need the newest versions installed. The latest version will eventually be pushed to the RunPod template, but this will not retroactivately update existing pods. So there's a chance you'll need to update your install if you have an older pod, or if you set up a new pod before the template is updated.
The easy way to find out if you need to upgrade is if seeing that your Interface page in Oobabooga looks like this.
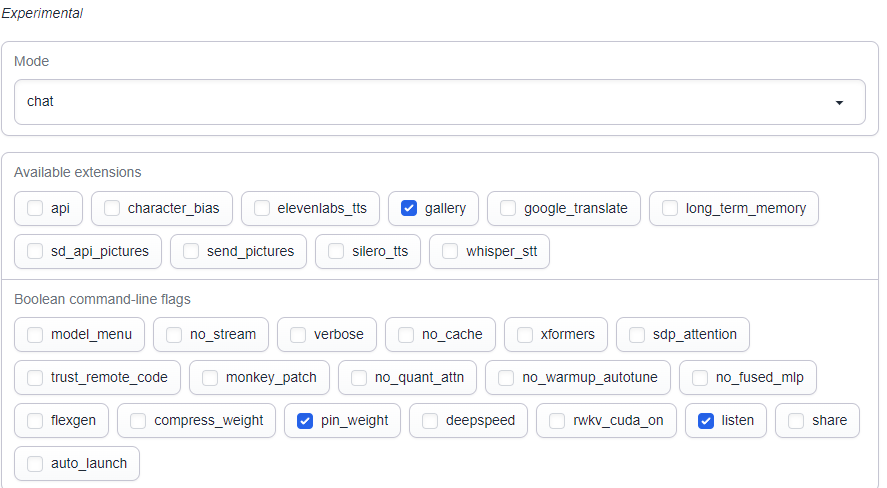
If it's like this already, you're fine.
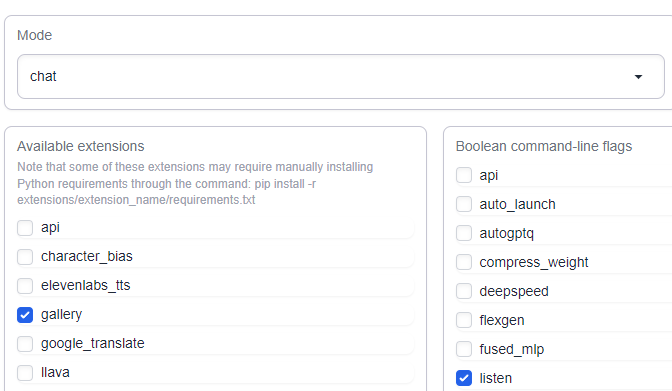
If you need to upgrade, here's what you need to do:
Open up a web terminal and type ps aux to see the running oobabooga server and to find out its PID. In this case, it's 47, so type kill 47 to kill the server.
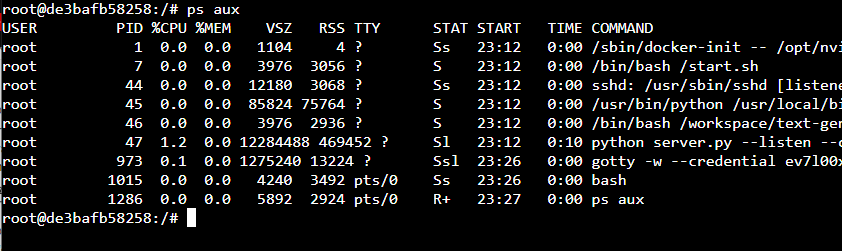
Then cd into the workspace folder, and type rm -r text-generation-webui to remove the existing Oobabooga install. Be aware this will remove any text logs in your install, as well as models and plugins, so back them up before you do this! Then, reinstall with the following instructions.
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt
Now, you'll need to find models that are capable of more than 2048 tokens of context. The amount of tolerance varies widely among existing models, and though every model is different, some will be able to handle more context past the old limit than others. For example, pygmalion-7b began falling apart for me at around 2300 tokens (which is still an increase over 2048, better than nothing!) However, the two listed models are purported to be able to handle over 10,000 tokens of context using landmark attention, so give these a try if you're interested in specifically experimenting with large context models. Credit to Eugene Pentland on HuggingFace for getting these set up there.
python download-model.py eugenepentland/WizardLM-7B-Landmark
python download-model.py eugenepentland/Minotaur-13b-Landmark
Then, hold your breath and restart the server with the following parameters:
python server.py --chat --trust-remote-code --listen
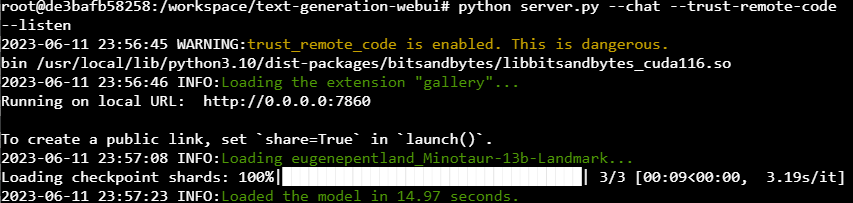
The server should come back up. You'll need to go to the Parameters page before you do anything else and pump up the following parameters.
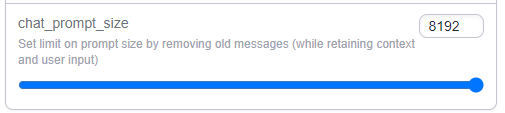
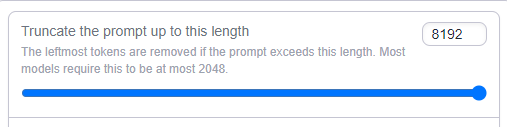
As the context buffer continues to fill up, you'll see over time as the log builds that it will eventually break out of the old limit.
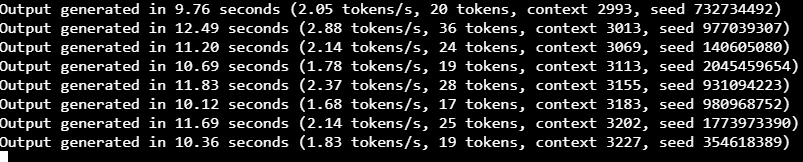
Since you are now able to define a context size arbitrarily instead of the 2048 limit previously imposed by Oobabooga, eventually the model will go off the rails if it wasn't designed for large contexts. Where it does so is different for each model. Some were specifically designed with the 2048 limit in mind, others were not and may actually be able to go significantly higher than the limit provided until it runs into some other kind of technical problem. You'll know when the model details when it starts to output gibberish like this:
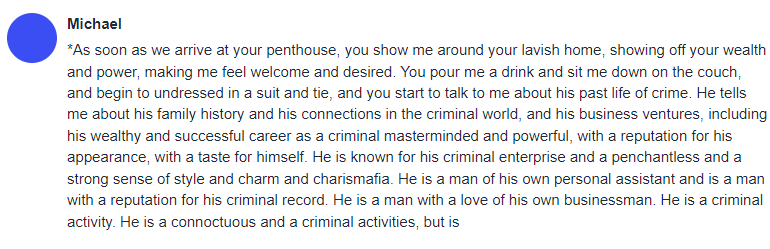
At that point, you'll know the model has hit its limit, and you need to dial it back. This was with the Wizard30b model, which occurred at about 2600 tokens of context. (For what it's worth, I tried with the Landmark models at even at 4000 tokens of context they kept going, and that's about where I decided to stop the test.)
At that point, I set the max prompt size to about 2500 to avoid going over the line where it started falling apart. However, even for a model that wasn't designed to take advantage of the extra context length, I still managed to get an extra 500 context worth of tokens that I wouldn't have gotten otherwise – and sometimes, that can make all the difference in creative writing. Also bear in mind that this can be combined with plugins such as Long Term Memory, which themselves cost a few tokens of context to invoke the memories, so having an extra 20 to 30% of context space is nothing to sneeze at and can help defray the context hit you may take in from other sources. Different models may have different limits, so play around and see what you can find out!