Benchmarking LLMs: A Deep Dive into Local Deployment and Performance Optimization


I just love the idea of running an LLM locally. It has huge implications for data security and the ability to use AI on private datasets. Get your company’s DevOps teams some real GPU servers as soon as possible.
Benchmarking LLM performance has been a blast, and I’ve found it a lot like benchmarking SSD performance because there are so many variables. In benchmarking SSD performance, you have to worry about the workload inputs, like block size, queue depth, access pattern, and the state of the drive. In LLMs you have inputs like model architecture, model size, parameters, quantization, number of concurrent requests, size of the request in tokens in and tokens out, and the prompts can make a huge difference.
The main points you want to optimize are latency, to first token and completion, and total throughput in tokens per second. For something that a user is reading along, even 10-20 tokens per second is plenty fast, but for coding you may want something much faster to be able to iterate on.
“Best practices in deploying an LLM for a chatbot involves a balance of low latency, good reading speed and optimal GPU use to reduce costs.” - NVIDIA
OpenAI currently charges for their API endpoints by the number of tokens in and tokens out. Current pricing is around $5 for 1M tokens in and $2.5 for 1M tokens out.
Open-source endpoints like ollama are a great place to start, since they are extremely easy to run. You can just spin up a docker or if you want a nice front end along you can use open-webui. I don’t need a front end since I’m using an OpenAI compatible API to target the LLM endpoint. I’m using llmperf to do the benchmarking
python token_benchmark_ray.py \
--model "meta/llama3-8b-instruct" \
--mean-input-tokens 550 \
--stddev-input-tokens 150 \
--mean-output-tokens 1024 \
--stddev-output-tokens 10 \
--max-num-completed-requests 300 \
--timeout 600 \
--num-concurrent-requests 30 \
--results-dir "result_outputs" \
--llm-api openai \
--additional-sampling-params '{}'Testing ollama (which I suspect uses the CUDA backend), oddly only uses one of the cards when I run 10 concurrent requests, and throughput is similar to a single instance but with much higher latency.
| GPU | Model | Quant | Sample Size | Requests | Tokens/sec |
|---|---|---|---|---|---|
| 2x RTX 4090 | llama3:8b-instruct-fp16 | 16 bit | 100 | 10 | 56.92 |
Inference performance on ollama seems okay for single requests but doesn't scale.
The start of this project was me getting excited about NVIDIA NIMs from the keynotes at GTC and Computex this year. I can say I wish NVIDIA had just made these optimized microservices with the backend completely open-source, but they can be run anywhere (on your local compute) with their API key authentication. They are extremely easy to run, being able to spin up a completely optimized and tuned LLM endpoint in just a few minutes (most of the time being spent downloading the model).
NVIDIA claims in their blog post, that an H200 can get up to 3000 tokens/s…I wanted to put this to the test and also compare the inference performance vs some high-end consumer cards like an RTX 4090.
I grabbed the NIM from here and start it in docker on the same system.
https://build.nvidia.com/meta/llama3-8b
This is a system I’m messing around with that doesn’t have the GPU at full PCIe bandwidth, but I accidentally discovered that inference doesn’t appear to be very PCIe bandwidth intensive, but I haven’t tried a model big enough.
| GPU | Model | Quant | Sample Size | Requests | Tokens/sec |
|---|---|---|---|---|---|
| 2x RTX 4090 | llama3:8b-instruct-fp16 | 16 bit | 20 | 1 | 84.68 |
| 2x RTX 4090 | llama3:8b-instruct-fp16 | 16 bit | 300 | 100 | 1053.51 |
A 4090 system is currently renting for $0.54/hr on Runpod community cloud, so by my math, in one hour, I could service 3.79M tokens on these two cards for a total of $1.08. Not bad at all! The only problem with this setup is that I can’t run the higher-end models because I don’t have enough GPU VRAM. To run the llama3-70b at 16-bit precision, I would need 141GB total, or 75GB at 8-bit.
https://ollama.com/library/llama3 you can see there are 68 different tags on llama 3, because people want to run these on different systems with different amount of GPU VRAM or system DRAM for CPU inference (which is much slower).
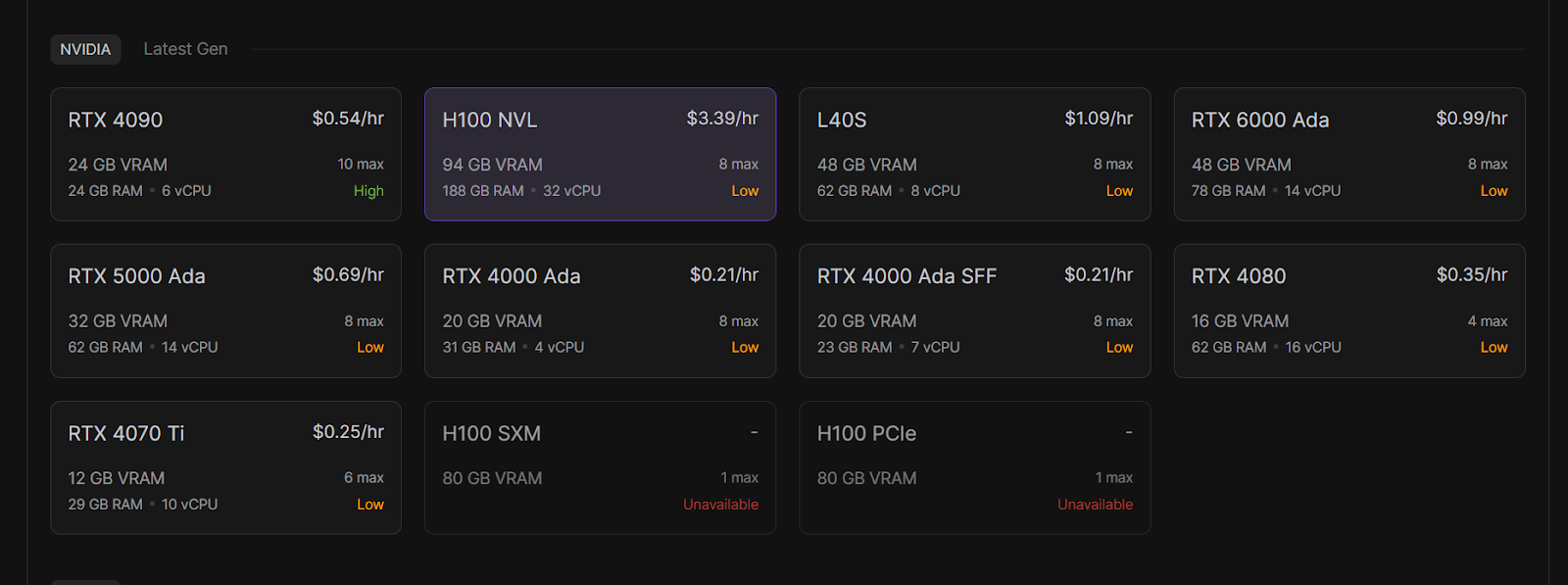
I don’t happen to have any H100s, but thankfully I can easily rent one for this test on RunPod for $3.39/hr.
For anyone who wants to try this at home, you will need an NVIDIA API key to be able to download and run the images anywhere, but it looks like this.

NVIDIA’s claim of 3000 tokens per second with H200 was probably with 8-bit precision, but let's see how close we can get!
| GPU | Model | Quant | Sample Size | Requests | Tokens/sec |
|---|---|---|---|---|---|
| 1x H100 NVL | llama3:8b-instruct-fp16 | 16 bit | 300 | 30 | 917.70 |
| 1x H100 NVL | llama3:8b-instruct-fp16 | 16 bit | 300 | 50 | 1140.03 |
| 1x H100 NVL | llama3:8b-instruct-fp16 | 16 bit | 300 | 100 | 1513.60 |
H100 performance with NVIDIA NIM.
Similar to how queue depth works on SSDs, increasing the concurrent requests increases the latency by 4-5x but can increase the total throughput in tokens/s by 18x. It seems to me here if we are able to get 1500 tokens per second on 16-bit then we are spot on for this optimized NVIDIA performance! Now I want to test some higher-end models like llama3-70b that actually can use the higher amount of VRAM the H100 has over a consumer GPU. I also want to see the impact of changing the precision and quantization of the model on performance. Unfortunately, NVIDIA doesn’t give us access in the NIM to easily swap out the model precision, but I’m sure that is coming since Blackwell has optimizations for FP4 they will be adding this in the future!
This was a fun weekend experiment, would love folks who optimize LLMs to chime in. Seems like NVIDIA has knocked it out of the park here with NIMs…and the ability for anyone to spin this up privately and do RAG and AI work on their own infrastructure or easily test with the NVIDIA endpoints.