AMD MI300X vs. Nvidia H100 SXM: Performance Comparison on Mixtral 8x7B Inference


There’s no denying Nvidia's historical dominance when it comes to AI training and inference. Nearly all production AI workloads run on their graphics cards.
However, there’s been some optimism recently around AMD, seeing as the MI300X, their intended competitor to Nvidia's H100, is strictly better spec-wise.

Yet even with better raw specs, most developers don’t use AMD cards for real-life production workloads, since Nvidia's CUDA is miles ahead of AMD’s ROCm when it comes to writing software for machine learning applications.
To address the growing interest in AMD, we present benchmarks for both AMD’s MI300X and Nvidia's H100 SXM when running inference on MistralAI’s Mixtral 8x7B LLM.
Our benchmarks show that the MI300X performs better than the H100 SXM at small and large batch sizes (1, 2, 4, and 256, 512, 1024), but worse at medium batch sizes.
Benchmark Setup
We chose Mistral AI's Mixtral 7x8B LLM for this benchmark due to its popularity in production workflows and its large size, which doesn't fit on a single Nvidia H100 SXM (80GB VRAM). To handle this, we set tensor parallelism to 2 on the H100, while the MI300X, with its 192GB VRAM, can fit the Mixtral 7x8B model on a single GPU.
However, directly comparing two H100 SXMs against one MI300X wouldn't be fair, so we extrapolated the performance of two MI300Xs working together. For each batch size, we doubled the performance of the previous batch size to estimate the MI300X's performance, simulating the workload distribution of two GPUs. For instance, if handling 16 sequences, each MI300X would separately process a batch of 8 sequences, mirroring the parallel workload distribution of two GPUs.
We ran the same throughput benchmark for each graphics card to test batched offline inference that comes standard as part vLLM's LLM inference framework. All computations were done using FP16 precision with input and output lengths set to 128 tokens.
Understanding Batch Size
Before we dive into the benchmarks, it's important to understand batch size. In the context of LLM inference, batch size refers to the number of prompts processed simultaneously by the model.
Smaller batch sizes can be more manageable and less resource-intensive but may not fully utilize the GPU's capabilities, leading to higher costs per token. They also result in the highest throughput per request but the lowest overall throughput. Conversely, larger batch sizes can leverage the GPU's full potential, increasing overall throughput and reducing costs per token. However, they require more VRAM and computational power and result in a lower throughput per individual request.
Understanding this balance is crucial: smaller batch sizes prioritize quick, individual responses, while larger batch sizes optimize for bulk processing and cost efficiency. Choosing the right batch size depends on your specific use case and resource availability.
Throughput Comparison (tokens/sec)
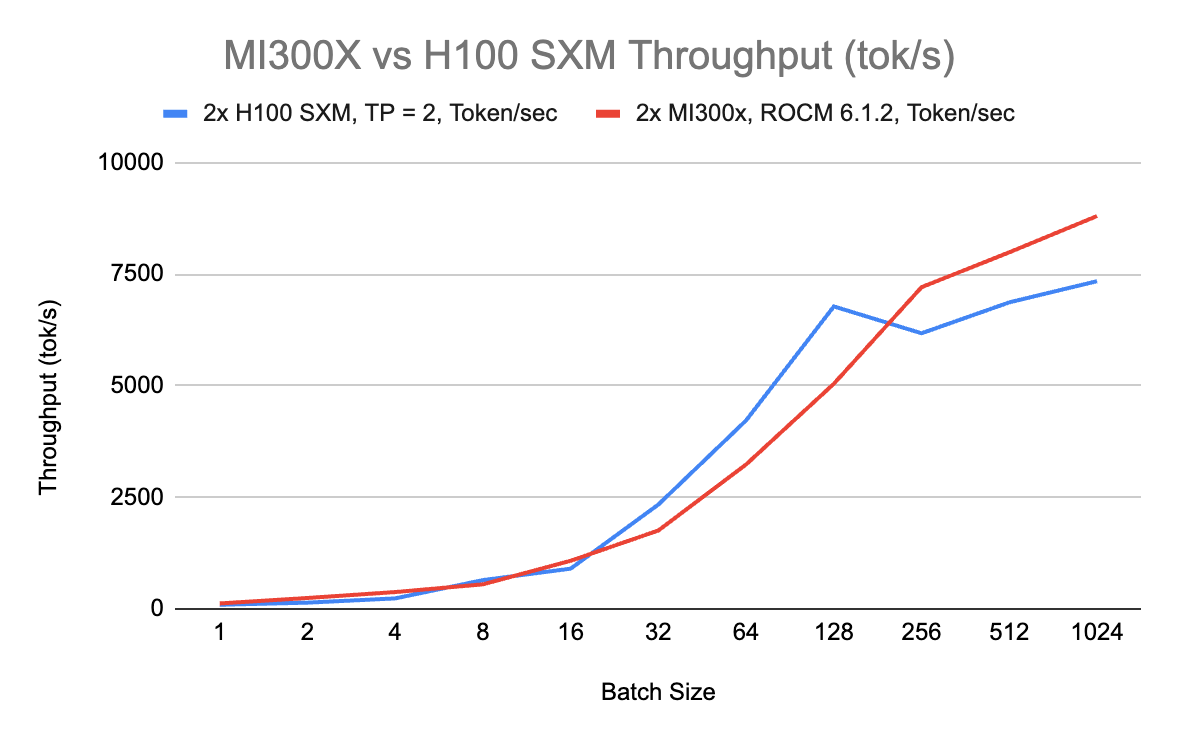
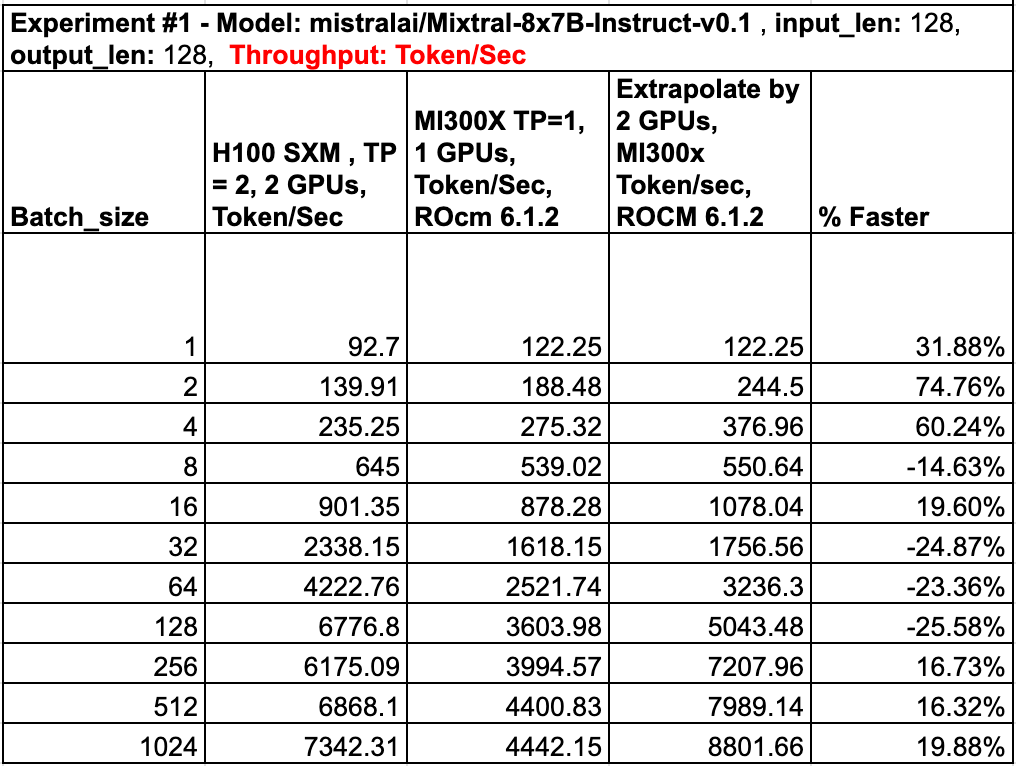
The Nvidia H100 SXM outperforms the AMD MI300X at smaller batch sizes, up to 128. However, as the batch size increases beyond 128, the MI300X starts to show its strengths. At batch sizes of 256 and above, the MI300X catches up and eventually surpasses the H100 SXM in throughput.
This shift suggests that the MI300X's larger VRAM (192GB) becomes more advantageous at higher batch sizes, allowing it to handle larger workloads more efficiently on a single GPU. Despite this, the H100 SXM’s consistent performance at smaller batch sizes highlights its suitability for applications where lower batch sizes are common.
Cost Comparison
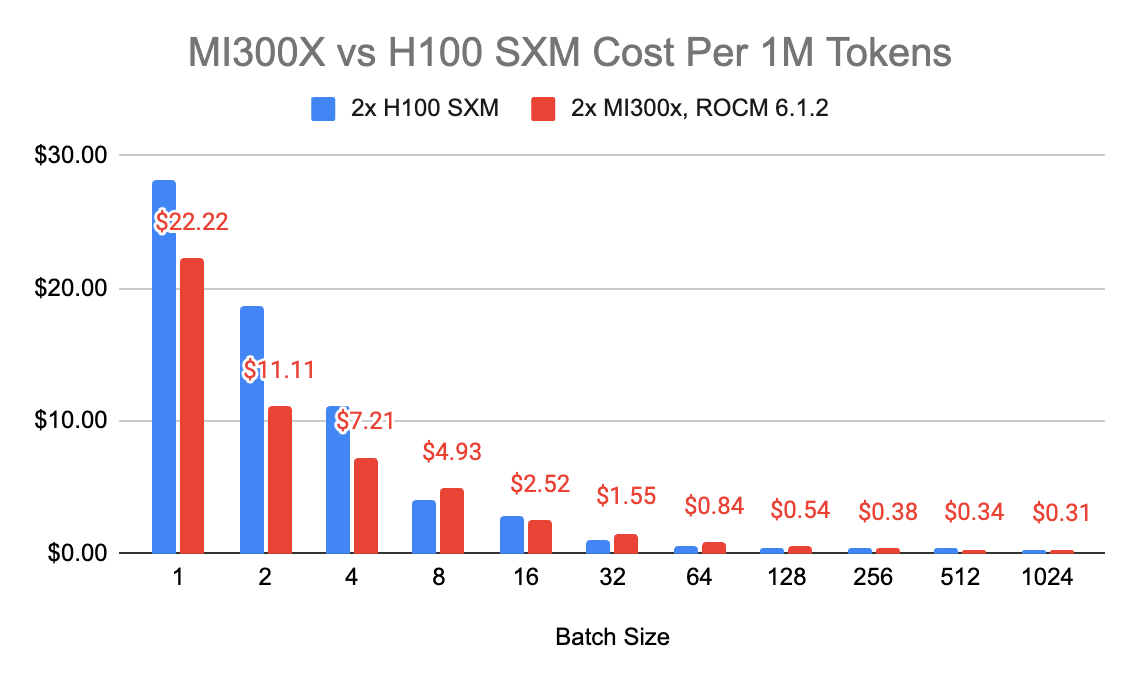
It's important to note that GPU costs can vary significantly across different cloud providers. For this comparison, we used pricing from RunPod's Secure Cloud, where the H100 SXM is priced at $4.69 per hour and the MI300X at $4.89 per hour.
At smaller batch sizes (1 to 4), the MI300X is more cost-effective than the H100 SXM. For instance, at a batch size of 1, the MI300X costs $22.22 per 1 million tokens, compared to the H100 SXM's $28.11. This cost advantage continues at batch sizes of 2 and 4, with the MI300X maintaining lower costs.
At higher batch sizes (256, 512, and 1024), the MI300X regains its cost advantage, offering lower costs per 1 million tokens compared to the H100 SXM. This indicates that while the MI300X is more expensive at medium batch sizes, it becomes more cost-effective for both very low and very high batch sizes.
Serving Comparison
While throughput and cost per 1M tokens provide valuable insights into GPU performance and cost-efficiency, serving benchmarks offer a more comprehensive view of real-world capabilities.
Serving benchmarks evaluate end-to-end performance, including request throughput, token processing times, and inference latency, which are crucial for understanding user experience and responsiveness. These metrics reflect how GPUs handle different load conditions and batch sizes in production environments.
For this comparison, we measured 1x MI300X instead of 2x to highlight its performance under typical usage scenarios. This approach provides a deeper understanding of operational efficiency, consistency, and reliability beyond raw computational power and cost.
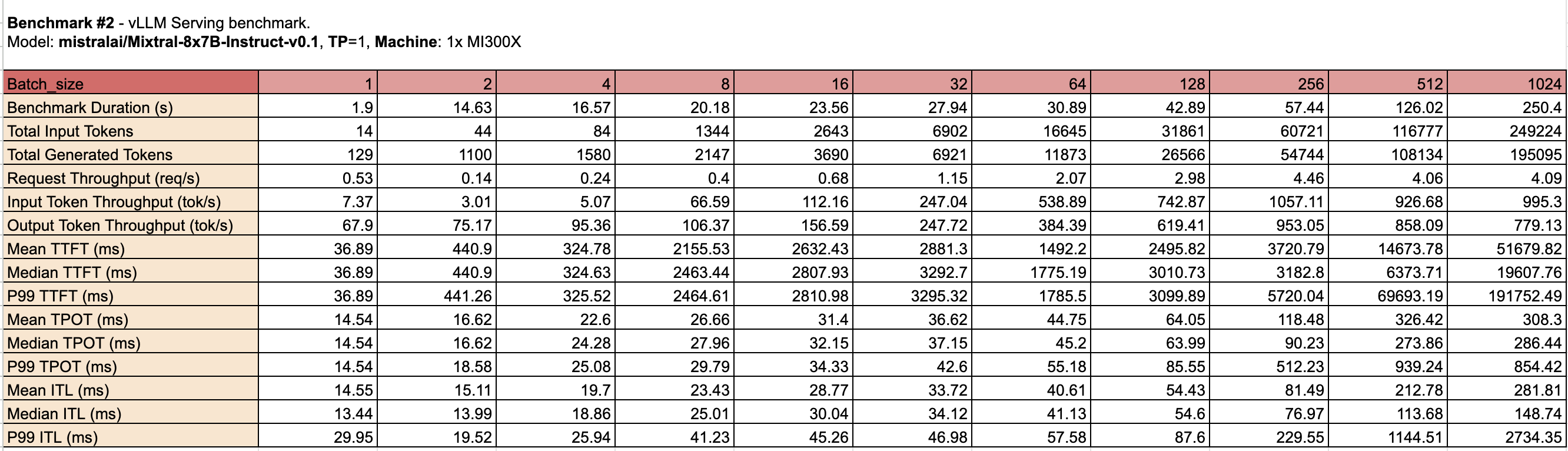
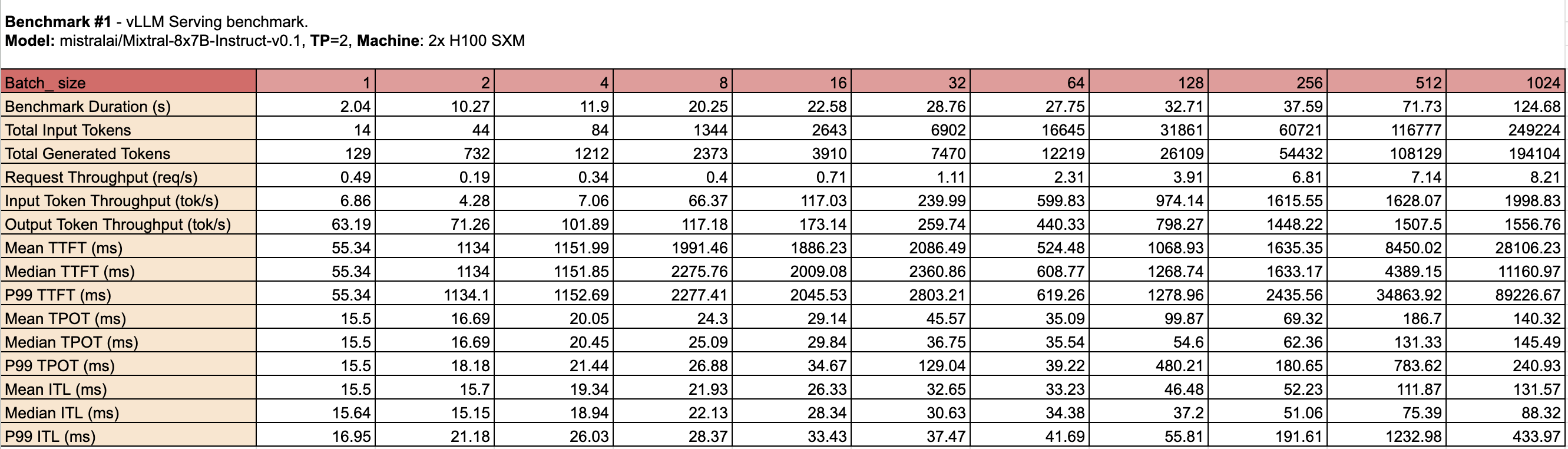
Both GPUs have their strengths: the Nvidia H100 SXM offers higher throughput at smaller to medium batch sizes, while the AMD MI300X provides lower latency and better consistency at larger batch sizes. The choice between the two will depend on the specific requirements of the workload, such as the desired balance between throughput and latency.
Conclusion
The MI300X excels at very low and very high batch sizes, offering better cost efficiency and leveraging its larger VRAM to handle larger workloads more effectively. Conversely, the H100 SXM demonstrates superior throughput at smaller to medium batch sizes, making it suitable for applications where these batch sizes are common.
Serving benchmarks reveal that the MI300X has lower latency and delivers consistent performance under higher loads, while the H100 SXM maintains robust throughput and cost-efficiency in mid-range batch sizes.
We’ll be working on more real world tests, specifically benchmarking other popular open source models like Mixtral 8x22b where AMD’s 192 GB of VRAM may be more impactful, and Llama-3 8b which is (arguably) the most popular open-source LLM out today.
If you want to try benchmarking or running AI workloads on the MI300X yourself, you can rent it by the minute on RunPod.
Replicate our Benchmarks
We encourage you to validate our benchmarks by running your own tests using the code outlined below. By replicating these benchmarks, you can gain a deeper understanding of the performance characteristics of the AMD MI300X and Nvidia H100 SXM in your specific use cases. Whether you're testing throughput, cost-efficiency, or serving benchmarks, following our setup and commands will help you see firsthand how these GPUs perform with MistralAI’s Mixtral 8x7B LLM.
AMD MI300X Benchmarks
Hardware:
- GPU: 1x MI300x
- Memory: 192 GB VRAM
- Tensor Parallelism (TP): 1
- Cloud Provider: RunPod
Software:
- vLLM Version: 0.4.3 + ROCm614
- Repository: ROCm/vllm
Commands to replicate throughput benchmarks:
git clone https://github.com/vllm-project/vllm
cd vllm/benchmarks/
# command to benchmark an LLM
benchmark_throughput.py --backend vllm --model "mistralai/Mixtral-8x7B-Instruct-v0.1" --input-len=128 --output-len=128 --num-prompts=<BATCH SIZE>
Commands to replicate serving benchmarks:
# client cmd
python benchmark_serving.py --backend vllm --model mistralai/Mixtral-8x7B-Instruct-v0.1 --dataset-name sharegpt --dataset-path "./ShareGPT_V3_unfiltered_cleaned_split.json" --num-prompt=<BATCH_SIZE>
# server cmd
python -m vllm.entrypoints.openai.api_server --model mistralai/Mixtral-8x7B-Instruct-v0.1 --disable-log-requests --tensor-parallel-size 1 --dtype auto
Nvidia H100 SXM Benchmarks
Hardware:
- GPU: H100 SXM
- Memory: 80 GB VRAM
- Tensor Parallelism (TP): 2
- Cloud Provider: RunPod
Software:
- vLLM Version: 0.4.3
- Repository: vllm-project/vllm (pip install vllm==0.4.3)
Commands to replicate benchmarks:
git clone https://github.com/vllm-project/vllm
cd vllm/benchmarks/
# command to benchmark an LLM
python benchmark_throughput.py --backend vllm --model "mistralai/Mixtral-8x7B-Instruct-v0.1" --input-len=128 --output-len=128 --num-prompts=<BATCH_ SIZE> --tensor-parallel-size 2