Ada Architecture Pods Are Here - How Do They Stack Up Against Ampere?


The Ada architecture is the latest architecture developed by Nvidia that is capable of achieving vastly improved performance on AI and HPC workloads compared to previous Nvidia GPU architectures. Ada also comes equipped with a new generation of Tensor Cores, which greatly accelerate matrix operations commonly used in deep learning algorithms. In addition, Ada brings with it higher clock speeds, lower power consumption, and a die cache size that is 16 times larger than that found on Ampere cards. This architecture represents a significant step forward for Nvidia in its pursuit of providing cutting-edge computing solutions for data centers.
Benchmarking Ada vs Ampere cards
Below are data collected via test runs of two different Ada pods compared to the old Ampere architecture.
Stable Diffusion task runtime in seconds (100 inference steps, 5 images per batch)
This test was conducted using the RunPod Stable Diffusion Template using the AUTOMATIC1111 interface.
| Resolution | RTX 6000 Ada (4x) | RTX 4090 Ada (4x) | A6000 Ampere (4x) | A6000 Ampere (1x) |
| 256x256 | 28 | 57 | 16 | 47 |
| 512x512 | 38 | 58 | 24 | 52 | 768x768 | 39 | 70 | 60 | 109 |
| 1024x1024 | 104 | 91 | 126 | 360 |
| 1280x1280 | 195 | 299 | 340 | 600 |
| 1536x1536 | 309 | 320 | 549 | 1201 |
| 1792x1792 | 484 | 602 | 1809 | 2200 |
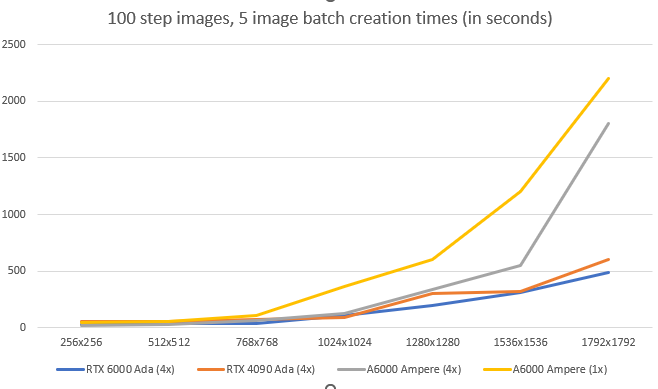
These results show that aside from the (probably rather questionable) use case of pumping out very small images, the Ada cards show up to a 50% increase on mid-level images and up to tripled or even quadrupled performance on the largest possible images within Stable Diffusion.
Text generation tokens per second in Oobabooga per model (fully loaded context)
This test was conducted using Oobabooga in the RunPod Text Generation UI Template with a pre-existing text log large enough to completely fill the context buffer.
| Model | A6000 Ada | RTX 4090 Ada | A6000 Ampere |
| Pygmalion 350m | 15.21 | 15.91 | 14.6 | Pygmalion 6b | 12.3 | 11.31 | 10.7 |
| KoboldAI 13B-Erebus | 2.03 | 1.9 | 1.3 |
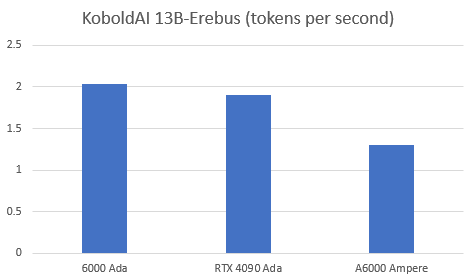
Looking at text generation, we also see a solid increase in tokens per second even on smaller models that nudges close to being 70% faster on the computationally expensive Erebus model.
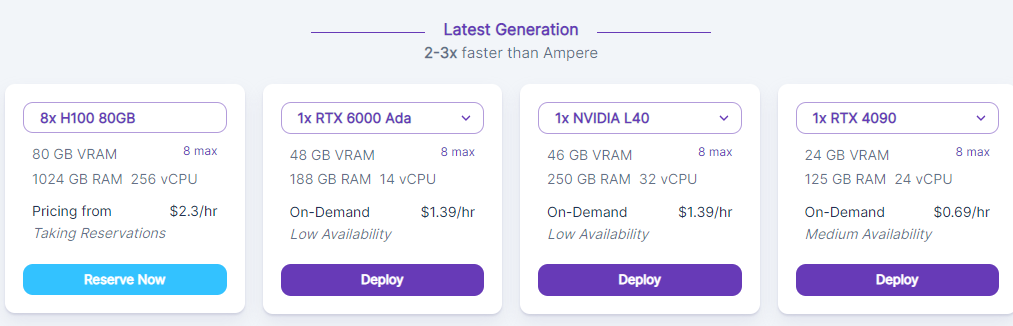
How Do I Set Up A Pod On Ada?
Simple - when setting up a pod, just ensure that you select an option at the top displayed under Latest Generation, such as what you see under the Secure Cloud listing. These GPUs tend to be more highly in demand, so grab them while you can!
Questions?
Feel free to reach out to us on our Discord - we are here to help!